

TL;DR overview
- Working with multiple code variants in C++ involves managing preprocessor-driven conditional compilation that creates different code paths for different platforms, configurations, or feature flags.
- Static analysis of C++ code with multiple variants requires analyzing all relevant configurations to ensure complete coverage, as bugs may hide in platform-specific or feature-specific branches.
- SonarQube supports multi-variant C++ analysis by allowing teams to configure multiple compilation database entries, ensuring that code paths for all target platforms are analyzed.
- Properly managing code variants reduces the risk of shipping platform-specific bugs and ensures consistent code quality across all build configurations.
As a C or C++ developer, you probably build your source code in several different ways. At the very least most developers build so-called “debug” and “release” builds separately (or optimized and non-optimized builds). But perhaps you also build cross-platform, say for Windows, Linux and macOS? Or maybe you still support 32-bit architectures as well as 64-bit? If you work with embedded systems you may target many different processors. Or perhaps you just maintain a library that can be configured for different error-handling mechanisms (exceptions, error codes, etc)? There are plenty more possibilities - and of course all the permutations between them. Depending on the nature of your project you may or may not be in control of which permutations are in use. In any case, we call each possible build configuration a “code variant”.
Usually, most of the source code is common to all variants but the pre-processor is often used to conditionally compile specific portions in or out. So the post-processed source code differs, of course. But, being C++, even the meaning of the common parts may differ, too! In fact, the meaning can change even without the pre-processor. For example, the sizes of objects may vary between architectures or even just due to packing and alignment configuration. Any of these changes may affect the analysis results. For example, Sonar’s rule S1238 cares about the size of objects passed as parameters.
How was this supported before?
Clearly all, or at least key, code variants should be analyzed. While this has long been recognized, until recently our support was more of a workaround than a first-class feature. Variants could be scanned independently - but the results were then independent, too. So if you marked an issue as “won’t fix”, for example, you would have to do that for each variant. There were a few ways to mitigate these issues, but none were very satisfying.
So we’ve now added first-class support for Multiple Code Variants and we’re pleased to say that this support is available starting from SonarQube Server 10.1.
How does the new feature work?
We will still do a full analysis for each variant. But this is now both easier and more expressive to set up - and, more importantly - the results are shown in an aggregated view that solves all the problems we had before! Let’s see this in action with an example.
Imagine you have a project that mostly works on Linux for 64-bit architectures, built using GCC. We have debug and release builds, so that’s two variants already. But it can also be built with clang and, additionally, a 32-bit version is published as part of the release package.
Now the cross-product of all those configuration options gives us eight possible code variants. However, not all of them are interesting and we can probably focus on just four of them:
- Main: GCC, 64-bit, release
- Debug: GCC, 64-bit, debug
- Clang: clang, 64-bit, debug
- 32: GCC, 32-bit, release
The names, in bold, are how we are going to refer to the respective variants. The first thing we need to do is to let SonarQube Server know those names, which we do by defining the property: sonar.cfamily.variants.names to have the value: Main, Debug, Clang, 32.
sonar.projectKey=xxxxxxxxxxxxxxxxxxx
sonar.cfamily.variants.names=Main, Debug, Clang, 32
Next, we need to provide the configuration for each variant. We do this the same way we would for a single variant: either using the build wrapper or by providing a compilation database file. However, the configurations (build-wrapper-dump.json or compilationdb.json) should be placed in the directory named after the variant name (e.g. Main), itself under the directory specified by the sonar.cfamily.variants.dir property. So, for example, if sonar.cfamily.variants.dir has the value, /Users/philnash/Dev/MyProject/bw-out then the first build configuration json files should be written to /Users/philnash/Dev/MyProject/bw-out/Main/ and so on.
MyProject
|- bw-out
| |- Main
| |- Debug
| |- Clang
| |- 32
|- …
It’s important to point out one limitation at the time of this writing. As usual, the build configuration json files must be generated on the machine where the analysis takes place. So if you are building for different platforms or architectures you will have to do some sort of cross-compilation for this to work. This may seem inconvenient, or even make it impossible, in some cases. But making this trade-off has allowed us to release this feature now. Supporting multiple machines is feasible for the future but will be a big task in itself. To help us understand the impact of this limitation please do let us know if this is an obstacle to you.
This also means that you will probably not be able to run those builds in parallel - e.g. using GitHub Actions’ matrix strategy - because this will typically happen on different (virtual) machines - or at least isolated environments. All the build configurations must be produced before the analysis step can run.
With those two things (the …names property and placing the config files in corresponding subdirectories) we can now launch the analysis as usual - except it will now take longer because it is performing four analyses instead of just one.
Now what?

Well, when first looking at the results of the analysis it may not appear much different to a normal (single variant) analysis. However, if you look closely, you’ll see a new field for each issue indicating how many variants are impacted. In our case, if the issue is variant-independent then we would expect to see “4 variants” displayed here. But if the number is less, then - bingo! - all that effort to set up multiple code variants has paid off - we just found a variant-specific issue.
You can also filter issues in the sidebar to focus on a specific variant - for example, if you want to focus on the 32-bit variant.
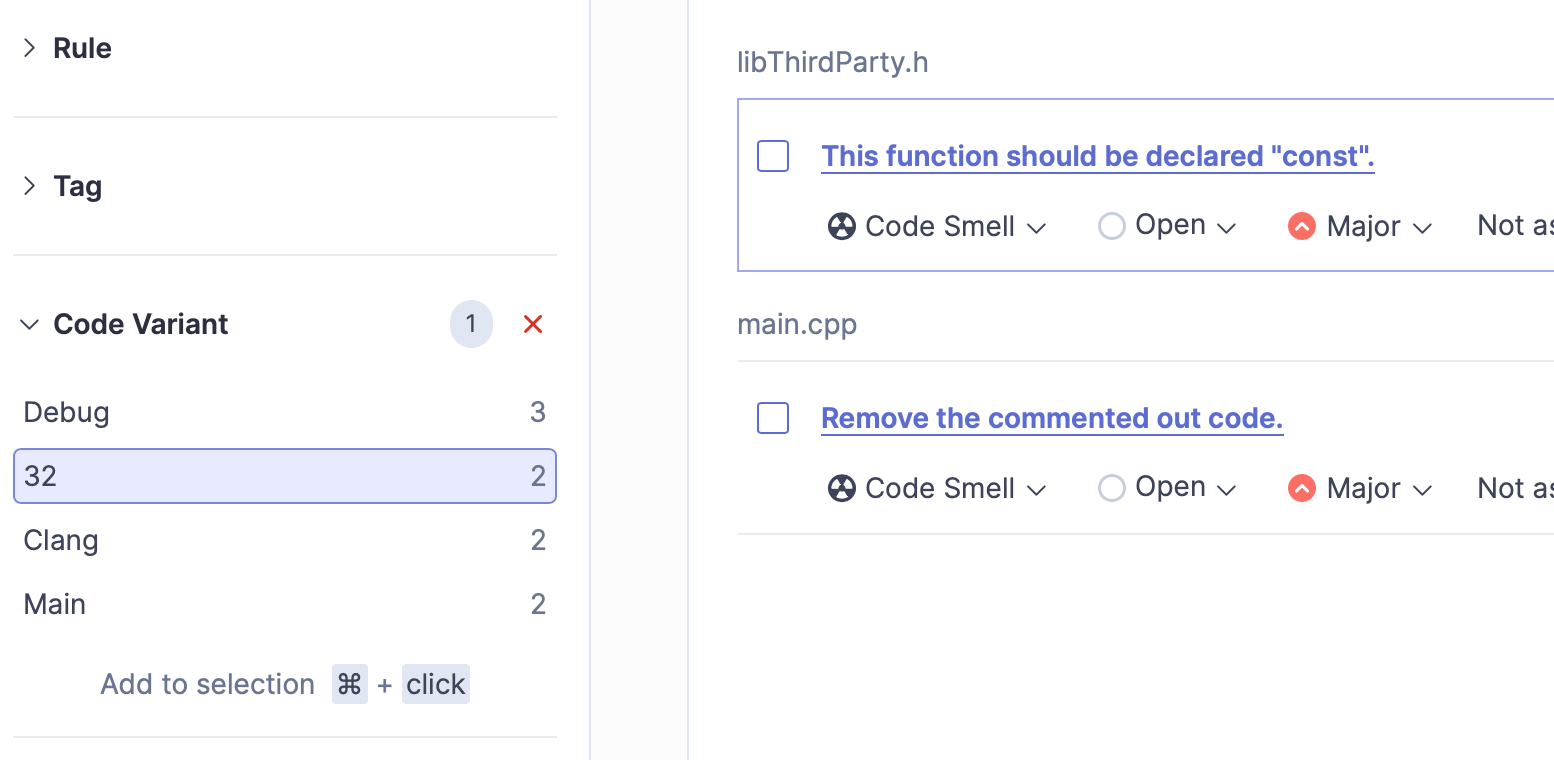
Furthermore, if an issue is marked as “won’t fix”, for example, then that now applies to all variants with the issue.
Having multiple code variants is part of the rich tapestry of C++. It’s now easier to analyze those variants and make sure they are given the attention they deserve.
FAQ
If I analyze multiple variants, does it impact the LOC of the project?
A file that is analyzed in several variants is only counted once. So the only impact you should see is if a file was previously skipped and is now taken into account in at least one of the variants.
Is multiple code variants compatible with caching?
Yes.
Is multiple code variants supported in SonarQube Cloud?
Not at the time of writing. This is under consideration. Please let us know if this interests you.
Is multiple code variants compatible with code coverage?
You can have coverage information in an analysis with multiple code variants, but you can only submit one coverage report for the whole analysis. This means you must either pick the most meaningful variant to use for coverage information or do some work, yourself, to merge coverage reports before submitting them. If this causes issues, you’re not sure how to set it up, or you have other suggestions in this area please let us know in our community forums.
