

TL;DR overview
- Vulnerable regular expressions in JavaScript can cause catastrophic backtracking, where a crafted input string causes the regex engine to consume exponential CPU time, leading to denial of service (ReDoS).
- The vulnerability arises from regex patterns with nested quantifiers or overlapping alternations that create an exponential number of matching paths for certain inputs.
- ReDoS is a practical attack vector in server-side JavaScript: a single malicious request with a crafted string can hang a Node.js event loop and block all other requests.
- SonarQube detects vulnerable regex patterns through static analysis, flagging expressions at risk of catastrophic backtracking before they reach production.
I first heard about regular expression denial of service (ReDoS) vulnerabilities from GitHub's Dependabot. Several of my projects over the years have had dependencies that suffered from ReDoS vulnerabilities, and I would bet that if you've built any JavaScript project with dependencies, you've also come across this.
This got me thinking; if there are vulnerable regular expressions in our dependencies' code, what about our application code, too? It is upon all of us who may write a regular expression to recognise when one may be vulnerable.
In this article, we are going to look deeper into ReDoS and show what can go wrong. We'll investigate real-life examples of vulnerable regular expressions from outage reports and open source. We'll see what can go wrong with seemingly innocent regular expressions like /\s*,\s*/ or /^(.+\.)*localhost$/. We'll understand what causes expressions like these to be vulnerable and see ways to fix and avoid ReDoS issues.
What is a regular expression denial of service vulnerability?
Due to the way that many regular expression engines work it is possible to write an expression that, with the right input, will cause the engine to take a long time to evaluate. In JavaScript, this will occupy the main thread and halt the event loop until the expression has been completely evaluated.
In the front end, this will cause the main thread to hang, stopping animations and other events. In the back end, this will block the main thread and prevent the server from being able to serve other requests or process other events. So that's a bad user experience in the browser and on the server, an issue that may also bring your entire application down leading to a bad experience for everyone involved.
Does this really happen?
In 2016 Stack Overflow experienced a 34-minute outage, in 2019 CloudFlare experienced 27 minutes of downtime. In each case, a ReDoS started a chain of events that led to a full outage. Neither incident was due to anything malicious, just a couple of regular expressions that no one expected to cause an issue ballooning up to full CPU usage. We'll take a look at each of the regular expressions that caused these outages throughout this article.
As I wrote above, ReDoS vulnerabilities also manifest in npm packages which your application may rely on. ReDoS issues have been found in the regular expressions of well-known packages like minimatch, moment, and node-fetch, each responsible for millions of downloads a week.
There are plenty of places you might write a regular expression within an application, for example; parsing data out of user input, replacing subsections of text, or validating user input. Since ReDoS vulnerabilities depend on the combination of a vulnerable regular expression with problematic user input, and we can't control user input, this is where regular expressions can get dangerous. So let's look at what causes a ReDoS and how we can avoid it.
Backtracking
It might not seem obvious, but most problems with regular expressions stem from failing to match part of the string they are being evaluated against. Matching is easy, but not matching can cause a process called backtracking where the regular expression engine will go back over choices that it made and try alternatives.
Lost in spaces
Let's have a look at an example. In the Stack Overflow outage, the offending regular expression was /^[\s\u200c]+|[\s\u200c]+$/. Let's break down what each part means:
- The
^matches the start of a line and the$matches the end of the line \smatches whitespace characters like tab and space\u200cis a Unicode zero-width space that isn't otherwise matched by\s- Square brackets create a character class that matches any character within the brackets
- The
+is a quantifier that matches 1 or more characters - The
|is a disjunction, an "or", it gives alternatives for the expression to match
Put together, the expression looks for one or more whitespace characters at the start of a line or one or more whitespace characters at the end of a line. It was being used to trim whitespace from the beginning or end of a line.
This works great if the string begins or ends with a whitespace character. However, if a string ends with a lot of space characters and then a non-space character it will cause an issue. For Stack Overflow, a post that contained around 20,000 unbroken whitespace characters, but did not begin or end with one, caused the issue.
Why is it a problem?
Let's investigate why this was an issue with an example that is easier to see. The regular expression /a+$/ checks for a string that has 1 or more "a" characters at the end (it's easier to see the character "a" instead of whitespace).
Consider the string "aaaaab". We can see immediately that this doesn't match, but that's not how a regular expression engine works. It matches the first "a" then the + quantifier tells it to match as many more as it can, so it matches the next four characters all the way up until the "b". Because it met a "b" and not the end of the line the match fails.
(aaaaa)bBut the evaluation isn't done yet. The engine backtracks to where it started the match, discards the first "a" and starts again with the second "a". Now it matches the next three characters, meets the "b" and fails the match.
a(aaaa)bIt then backtracks again, starting with the third "a" and repeats for the fourth and fifth as well.
aa(aaa)b
aaa(aa)b
aaaa(a)bOnce it exhausts all the possible starting points it finally decides there is no match and the expression fails completely.
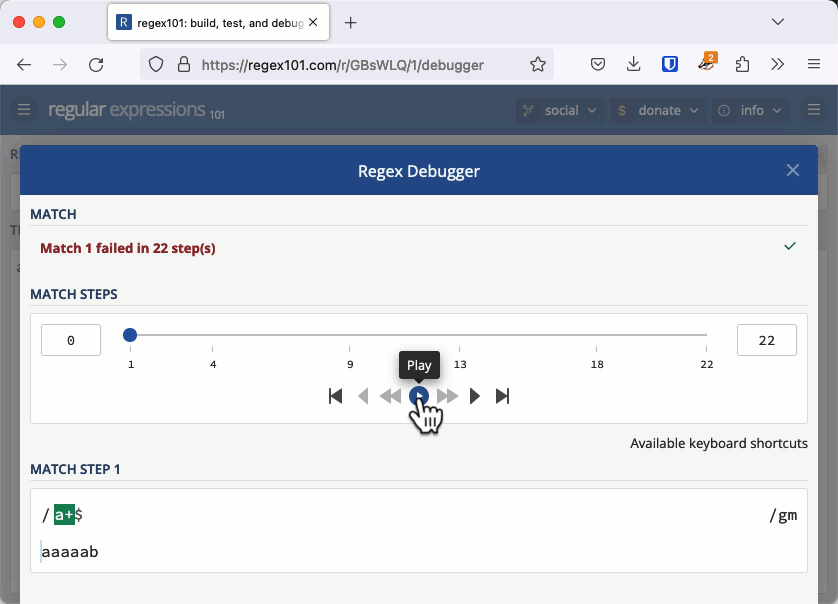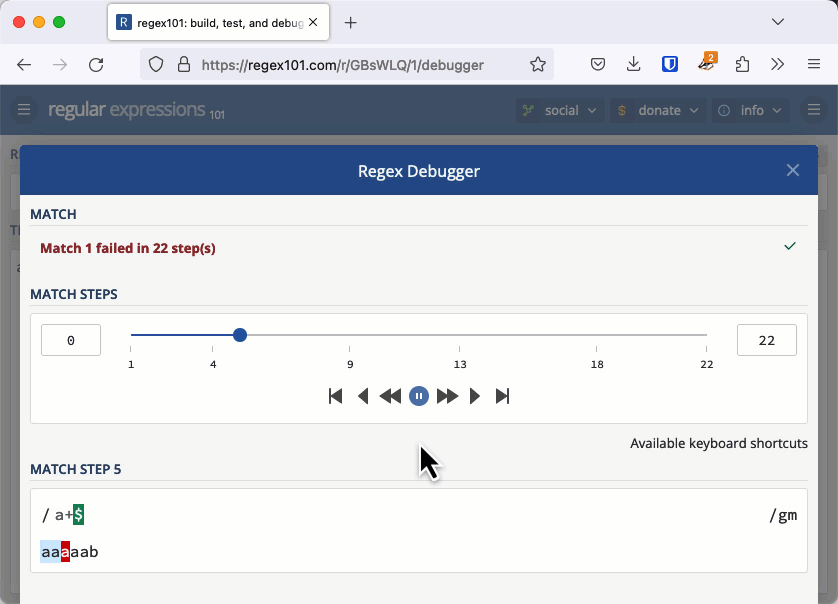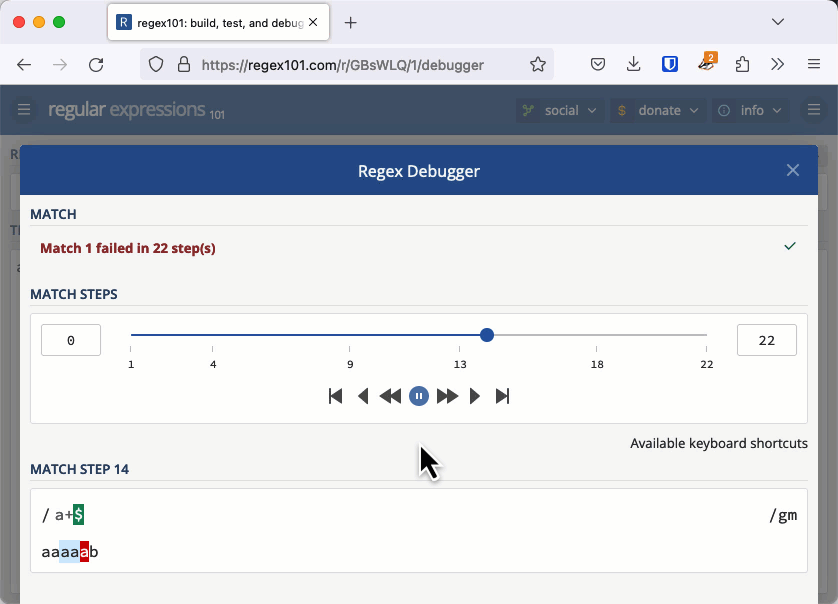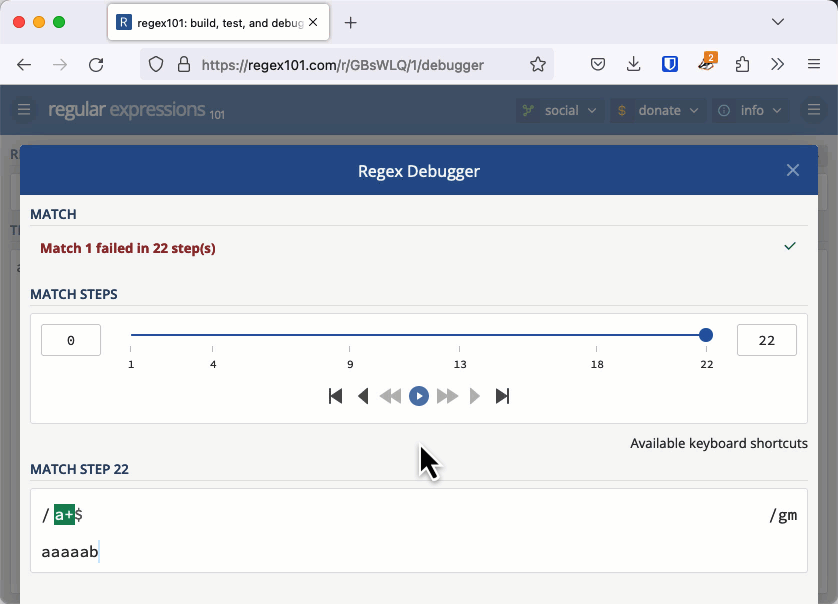
For each "a" we add to the string, the entire length of the string needs to be checked one more time. This makes the complexity of checking this string O(n2) or quadratic time.
On a small string, this is fine. It takes 22 steps to check "aaaaab", 29 steps to check "aaaaaab" and 37 steps to check "aaaaaaab". But when you have 20,000 characters to check, like Stack Overflow did, it takes about 200 million steps and that is enough to keep a server hanging a long time. You can check this out in the regex101 debugger.
JavaScript examples
Stack Overflow is built in .NET, but this is the sort of thing that can affect a JavaScript project too. For example, the http-cache-semantics package used to use the regular expression /\s*,\s*/ to split the Cache-Control header by commas and trim the whitespace on each side. From what we know about backtracking now, any amount of whitespace would start this search and as long as there wasn't a comma at the end of the whitespace, it would start the backtracking. Send a request with a Cache-Control header full of whitespace and you could crash any server that used a vulnerable version of this package.
Solving backtracking issues
In these cases, the use of the * or + quantifiers followed by another character or a boundary is the problem.
The regular expressions /\s*,/ and /[\s\u200c]*$/ both give the engine license to keep checking whitespace characters as long as they are present and not followed by a comma or the end of the line, and then backtrack once the match fails.
Limit the expression or the input
There's no perfect way to solve this problem with just regular expressions. One option is to put a limit on how many characters the expression will match, which will limit how long it can spend trying to make matches. Instead of /\s*,/ try /\s{0,64},/.
Alternatively, if possible, you can restrict the length of the string input.
Use other string methods
Finally, in both the Stack Overflow and http-cache-semantics cases, the regular expression was used to trim whitespace from the string. In JavaScript, you can avoid the problem altogether by using the string function trim. This is how it was fixed in http-cache-semantics. The exact fix can be seen in GitHub, but a simplified version of the original code looked like this:
const parts = header.split(/\s*,\s*/);
for (let part of parts) {
// do stuff with part of header
}The code still uses a regular expression to split the header string on commas, but the job of trimming the whitespace is now done by the trim function:
const parts = header.split(/,/);
for (let part of parts) {
part = part.trim();
// do stuff with part of header
}Sometimes regular expressions are not the answer.
Catastrophic backtracking
Regular backtracking over very long strings of almost-matches is bad, but we can come up with something far worse in a regular expression. Let's take a look at another example.
In node-fetch, a function to check whether an origin was trustworthy used a regular expression to aid in detecting whether a URL is trustworthy. One of the tests used the regular expression /^(.+\.)*localhost$/. Let's break this one down:
.is the wildcard character, it matches any character in a string.+means we match the wildcard one or more times\.is a literal period character- the group
(.+\.)is a collection of one or more characters followed by a period ^(.+\.)*means that the group must be at the start of the string (^) and can occur zero or more times (*)- finally,
localhost$is the literal string "localhost" and it must appear at the end of the string ($)
The test was to see whether the URL host was either "localhost" or was a subdomain ending in ".localhost", for example "dev.localhost".
The issue here is twofold. Firstly, the group (.+\.) has an overlap in it. The wildcard character can match the period as well. The second problem is that both the + and * quantifiers are greedy and will try to match as much as they can. This initially causes the wildcard to match everything in a string, before backtracking to match the period.
Consider the string "a.a.a.a.a.a.a". The expression will find the last period and then go on to check whether the group exists zero or more times before looking for the ending, the literal "localhost". It doesn't find it, so the first attempt at matching fails and these are the characters considered:
(a.a.a.a.a.a.)aNow the backtracking starts, the first group matches all but one of the "a." strings and then the * quantifier causes that group to match the last "a." string.
(a.a.a.a.a.)(a.)aThe last character doesn't match "localhost", so we backtrack again. Now the options start to build up. We match the first four "a." strings, and the next two can either be matched together or in two groups.
(a.a.a.a.)(a.a.)a
(a.a.a.a.)(a.)(a.)aThis fails, so we backtrack again. Now we match the first three "a." strings and the last three can be matched in four different ways.
(a.a.a.)(a.a.a.)a
(a.a.a.)(a.a.)(a.)a
(a.a.a.)(a.)(a.a.)a
(a.a.a.)(a.)(a.)(a.)aThis is the start of an exponential sequence; the complexity is O(2n). When the number of options that a regular expression has to consider grows like this it is known as catastrophic backtracking.
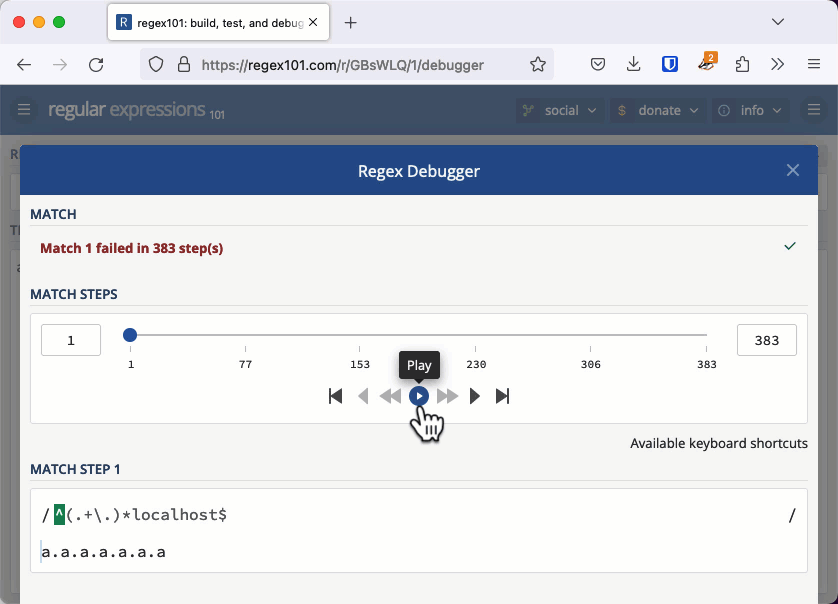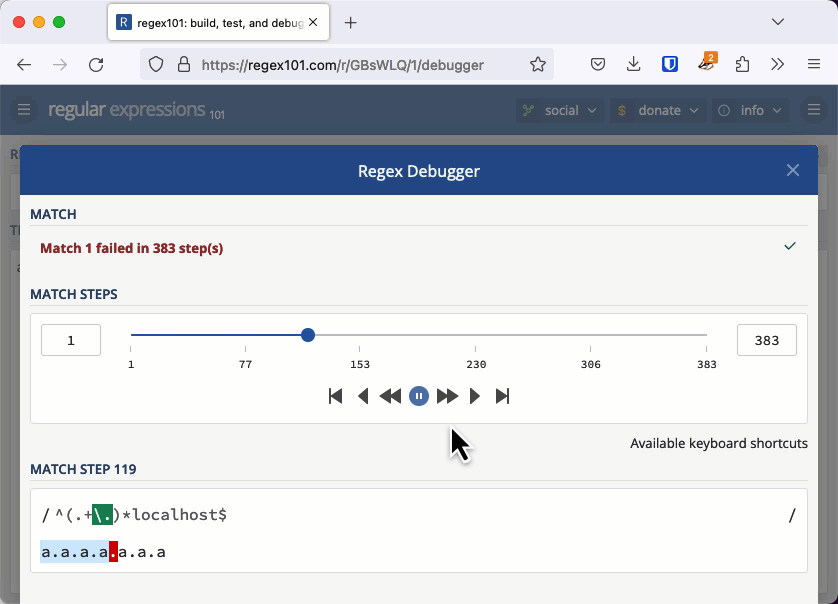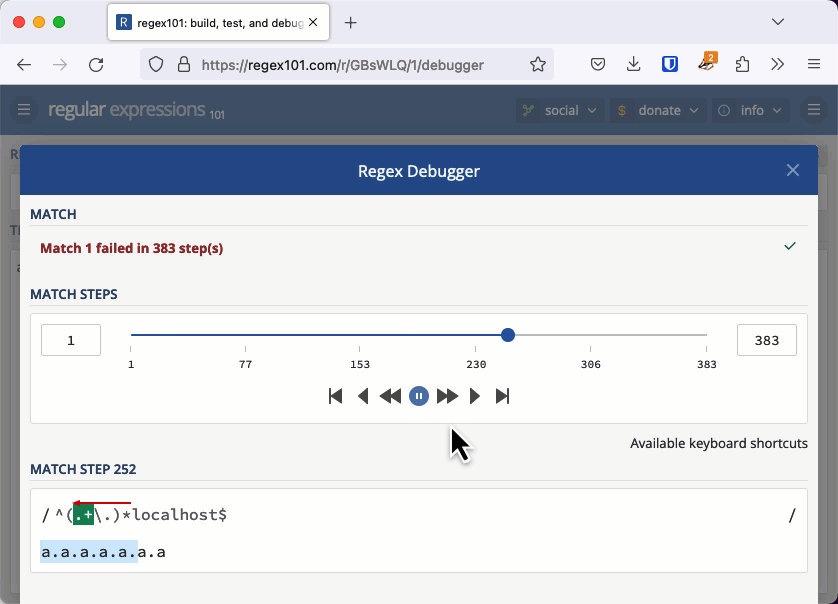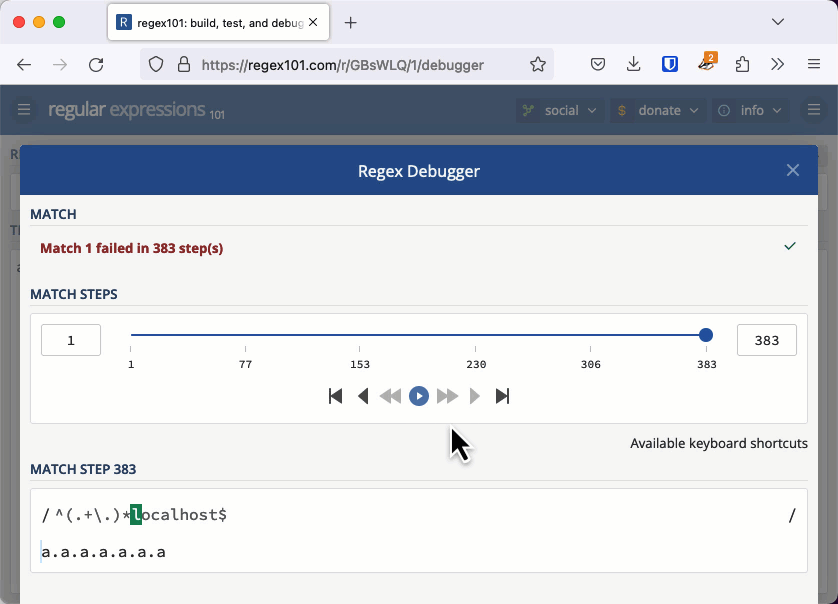
With the previous quadratic example, we needed thousands of characters to cause an issue. When the regular expression's worst case is exponential, we don't need a very long string to cause the evaluation to take seconds or even minutes. You can check this example out in the regex101 debugger. If you keep adding "a." to the string, eventually the app will tell you it has detected catastrophic backtracking.
You can also visualise what a regular expression looks like using the tool Regexper. This particular expression looks like this:
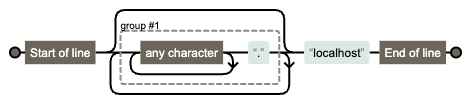
You can see there's a double loop, an internal one over "any character" and an outer one around the group. Since, "any character" also matches "." the overlap means the group can be evaluated in many different ways, as we have seen. That is what causes the catastrophic backtracking we saw above.
Testing your regular expressions
I built a tool to investigate the time it takes to evaluate regular expressions against a string. It comes with some examples, including this one. Note, the regular expression is evaluated in a web worker, which is why the interface doesn't freeze. You may also find different browsers behave in different ways. In my testing, it seems that Safari has implemented some way to detect if the evaluation is taking too long and shortcuts the failure, which is great in general, but not useful to see this effect. Meanwhile, Firefox has a 5-second time out after which it throws an error. Chromium-based browsers appear to be happy to run the code for as long as it takes.
In real life
The CloudFlare outage was an example of catastrophic failure. Their regex was: (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*))).
It looks long and complicated, but if we visualise it we can see that we have two loops of "any character" next to each other. Those can match in multiple ways, similar to how we saw with the node-fetch example above.
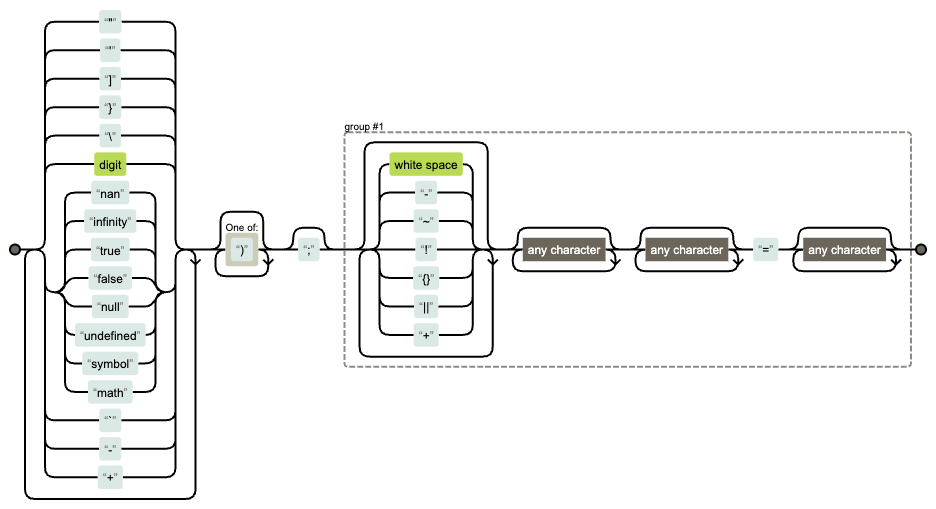
In this case, CloudFlare was trying to use this regular expression to block inline JavaScript. While it isn't made particularly clear in the report, my guess is that this regular expression was running against the body of a request or response. It doesn't take much to satisfy the start of the expression and get to the part where the two "any character" loops start and that's where the problem lies. In fact, you can start this expression matching with a single item from the left side of the visualisation, any digit or a quotation mark. If the input is long enough beyond that character, which request or response bodies likely are, the .* will greedily consume the rest of the string and eventually succumb to a catastrophic backtrack.
The appendix to the outage explains further, but I recommend reading the whole article to understand how the regular expression triggered a set of events that caused the outage, and also how CloudFlare worked to return service to normal.
More overlaps
Superhuman also had an issue with catastrophic backtracking. In their case they were trying to match email addresses using the expression /("[^"]*"|[^@])*@[^@]*/. The issue here lies in the group ("[^"]*"|[^@])* which allows for either a string surrounded by quotation marks or a string that contains anything but the @ symbol zero or more times. Since the quotation mark itself is a string that doesn't include the @ symbol, there is an overlap between these choices, which causes the evaluation to branch in a similar fashion to the node-fetch example. A long string of quotation marks will take a long time to evaluate.
Solving catastrophic backtracking issues
Catastrophic backtracking is caused by patterns that can produce different matches on the same input. So, look out for expressions like:
P*orP*?(the lazy operator), wherePis a pattern with many options for matching, like the wildcard.*- a disjunction with overlapping groups, like
(a|ab)* - consecutive patterns that overlap, watching out for optional separators, like
.*-?.*which can be reduced to.*.*
To fix catastrophic backtracking you can do a few things:
- Refactor nested qualifiers so that an inner group can't be matched by an outer group. The node-fetch example could replace the group
(.+\.)with([^.]+\.)so that there is no longer an overlap - If you are splitting a string up, take multiple passes with simpler regular expressions
- regular-expressions.info suggests using atomic grouping (
(?>pattern)) to avoid catastrophic backtracking. An atomic group avoids backtracking, once it has matched a group the engine won't go back into it to try a different way. Sadly, JavaScript doesn't have atomic groups built in, but you can fake atomic groups using a lookahead and a backreference. Fixing the node-fetch expression this way looks like this:^(?=((.+\.)*))\1localhost$. You can read more about how using lookaheads and backreferences work here - Finally, you can just avoid regular expressions. The actual fix to node-fetch swapped the regular expression for two string checks
One other alternative to consider is using a regular expression engine that doesn't use backtracking. Google has built one called re2 and there are Node.js bindings for it. There are some limitations to using it though; it doesn't support lookahead or backreferences and there are some expressions that will evaluate differently compared to the built-in RegExp, check the README for details.
Regular expressions are complicated
That's been quite a journey. Learning that those seemingly innocent regular expressions may be hiding catastrophic, server and interface collapsing issues within them is an eye-opener. Thankfully there are ways to fix the issues, but the difficulty is spotting them. There are tools available that can help though.
- SonarQube Server and SonarQube Cloud scan for potentially dangerous regular expressions and highlight them as security hotspots
- After finding they had written a bad regular expression, Superhuman put together the tool regex.rip which attempts to detect dangerous expressions
- I've pointed to the tool regex101.com a couple of times in this post, it explains regular expressions and the debugger can help you see how an expression is being evaluated
- Regexper is great for visualising expressions and spotting whether you have too many loops or overlapping conditions
- eslint-plugin-regexp is an ESLint plugin that includes a rule to report potentially dangerous backtracking
So, remember the tips in this article, watch out for wildcard characters, keep an eye on the + and * quantifiers, and when you are testing, recall that catastrophic backtracking occurs when your expression fails to match, so don't just pay attention to the success cases.
Regular expressions can turn up anywhere in your codebase and often interact with user input, validating or parsing it. Any of your regular expressions may be vulnerable to ReDoS, so go check up on your regular expressions and let me know if they are all OK.



