

TL;DR overview
- SonarQube 9.9 LTS delivers substantial Python analysis improvements, including precomputed symbols from Typeshed for better performance and accuracy, and new rules for Python 3.10 and 3.11 language features.
- The Python analyzer in 9.9 LTS covers 249 rules, adding new domains including AWS CDK security rules, regex correctness checks, and improved unit test quality detection.
- Security analysis is enhanced through symbolic execution that can now detect more vulnerability classes, including taint-flow issues in modern Python web frameworks.
- Python developers benefit from tighter integration with SonarQube for IDE, receiving 9.9 LTS-era feedback in their local environment through Connected Mode to ensure consistency with CI analysis.
SonarQube Server 9.9 LTS sports a powerful Python analyzer, with 250 (okay, 249) rules for making sure that Python developers can write Code Quality that is fit for production and fit for development.
In this LTS release, there are significant advancements in Python analysis compared to SonarQube Server 8.9 LTS. Grab a coffee and get comfortable as I walk you through these improvements!
Using SonarQube Cloud? You'll find all these improvements there as well.
Updates to the analysis engine
Precomputed symbols from Typeshed boost performance and accuracy
To provide accurate analysis, SonarQube Server relies on type information for the Python standard library as well as common libraries used by Python developers. This type information is provided by Typeshed (a collection of Python stubs).
In SonarQube Server 8.9 LTS, this information was calculated at analysis time, which was expensive. It also wasn’t possible to collect all the information available, such as conditional type information based on the version of Python being used.
SonarQube Server 9.9 LTS extracts far more data from Typeshed with better performance (calculating symbols once, shipped with SonarQube Server, not on each analysis), leading to an analysis with better performance and better results.
Python version can be provided for more accurate analysis results
As just mentioned, SonarQube Server can now take into consideration type information specific to the version of Python being used.
Python 3 has many breaking changes compared to Python 2, which has an impact on our bug detection rules when some code pattern is a bug in Python 3 but not in Python 2!
Developers using SonarQube Server 9.9 LTS can now set the sonar.python.version analysis parameter in order to detect issues specific to Python 2 or Python 3.
Consider this piece of code:
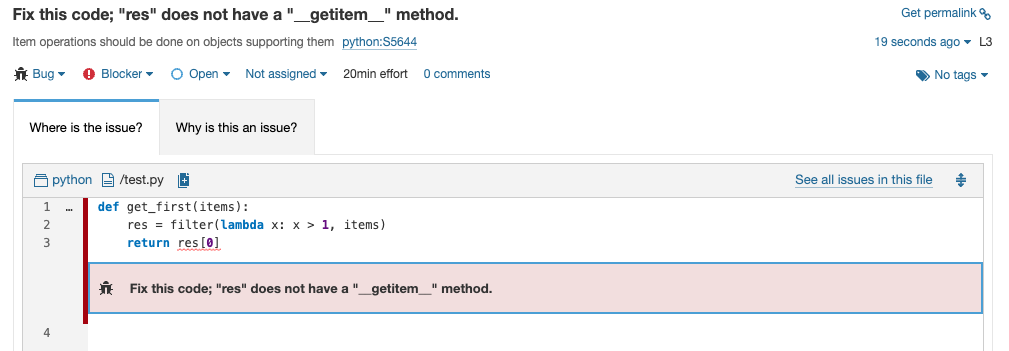
def get_first(items):
res = filter(lambda x: x > 1, items)
return res[0]There's a problem here if you're using Python 3: The filter API returns an iterator that does not have a __getitem__ method. This isn't a problem with Python 2, because the same API returns a list. This is an easy mistake to make if you're migrating your codebase to Python 3.
SonarQube Server 9.9 LTS, knowing the version of Python being used, can properly raise an issue on this code.
Support for Python 3.10 and 3.11
Speaking of Python versions… a new SonarQube Server LTS means support for new versions of a language, which requires SonarQube Server to update how code is parsed and understood in the context of raising issues.
In SonarQube Server 9.9 LTS there is added support for Python 3.10 and 3.11, parsing new constructs like the many patterns of the match statement and the except* syntax.
This also means that existing rules have been updated to not raise false-positives on these constructs either.
Vulnerability detection powered up with symbolic analysis
SonarSource acquired RIPS Technologies all the way back in May 2020 (there were a few other things happening in the world in Spring 2020, so don't worry if you forgot)!
Not only did we gain many great colleagues, but we also acquired their advanced technology for detecting vulnerabilities in Python. After months of work, we took the best of the Sonar & RIPS engines to produce a new security engine for Python. We actually replaced the engine entirely, moving from so-called fixed point analysis to symbolic analysis.
This means the security engine for Python is now field-sensitive, and commercial editions of SonarQube Server 9.9 LTS can precisely track which field of an object is tainted (or not) by malicious user input. For you, this means fewer false-positives so you can concentrate on fixing real vulnerabilities, not analyzing the fake ones.
Fixing false-positives
On the topic of false-positives, it wasn’t only security rules that saw improvements. Sonar puts in a significant amount of effort to make sure only true issues are raised, and our developers are always reviewing issues raised by Python rules to make sure they are accurate and relevant. They also receive reports from our community and through commercial support channels.
Not counting all of the FPs fixed by updates to the analysis engine, there were 31 specific false-positives our developers addressed in SonarQube Server 9.9 LTS!
New Rules
Going back to basics
Sometimes it's easy to get so focused on the impressive new rules that, stepping back, we see there are some less complex (but still important) rules that need to be implemented!
SonarQube Server 9.9 LTS brings nine of these rules that are commonly provided by other linters, such as tracking TODO tags and making sure copyright/license headers are included on each file.
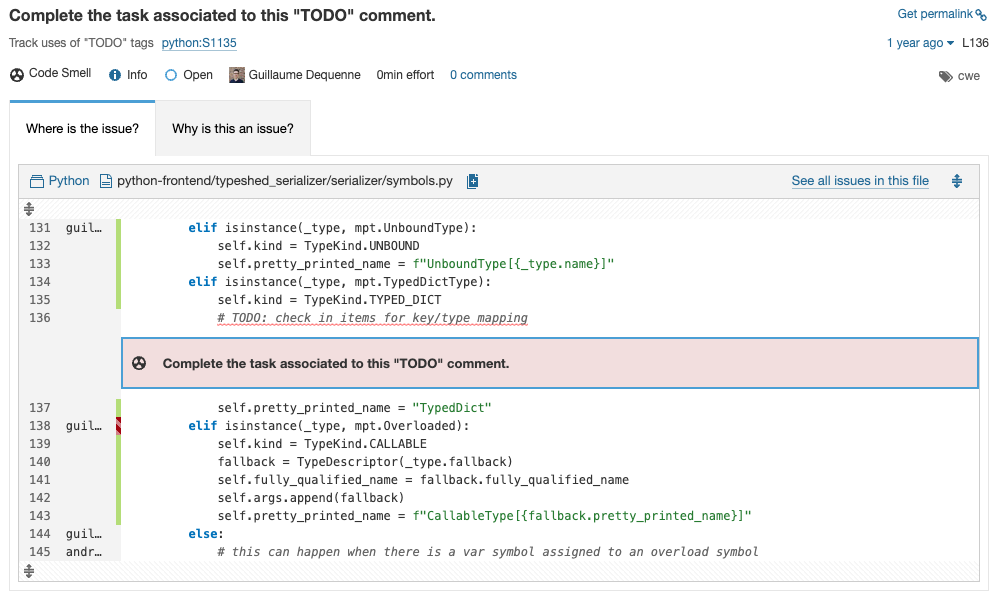
You can find the complete list of these rules here.
Write clean and error-free regular expressions
Regular expressions (regex) are sequences of symbols and characters expressing a string or pattern to be searched for within a longer piece of text. Regex is an incredible tool to express conditions that would otherwise require many lines of code to catch the same pattern.
While using regex is quite typical for developers these days, that does not make it easy to handle. Writing regexes is error-prone and time-consuming, and they're difficult to document well. Once they are written, identifying errors in them can be extremely difficult.
Not only are they difficult to write, but due to their size and complexity, they are often difficult to read and understand.
Take this example:
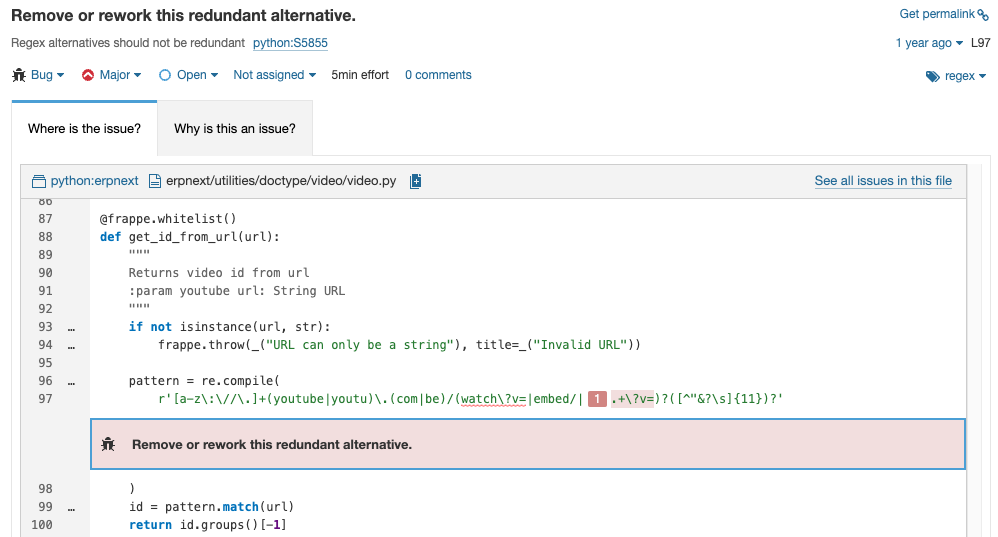
pattern = re.compile(
r'[a-z\:\//\.]+(youtube|youtu)\.(com|be)/(watch\?v=|embed/|.+\?v=)?([^"&?\s]{11})?'
)This regular expression is meant to match URLs like https://www.youtu.be/watch?v=dQw4w9WgXcQ and https://www.youtube.com/embed/dQw4w9WgXcQ
The third capturing group in this regular expression is (watch\?v=|embed/|.+\?v=)? to account for variations in the URL format. You might not have noticed that the third alternative in this capturing group, .+\?v=, is redundant, as it's already covered in the first alternative watch\?v= and will never apply to /embed/ URLs.
So this regular expression can be simplified by removing the redundant alternative group, giving us a slightly more readable:
pattern = re.compile(
r'[a-z\:\//\.]+(youtube|youtu)\.(com|be)/(watch\?v=|embed/)?([^"&?\s]{11})?'
)That would have been hard for a developer to spot on their own. It's not hard at all for SonarQube Server.
In SonarQube Server 9.9 LTS our developers introduced 21 new rules to help Python developers, write efficient, error-free, safe, and less complex regular expressions! You can find all the Python rules related to regular expressions at within the product.
Write better unit tests
If you're using the unittest or pytest frameworks to write your Python unit tests, you’re in luck, because SonarQube Server 9.9 LTS adds rules specifically related to analyzing your test code.
See all the Python rules here.
Build secure AWS infrastructure with rules targeting the AWS CDK
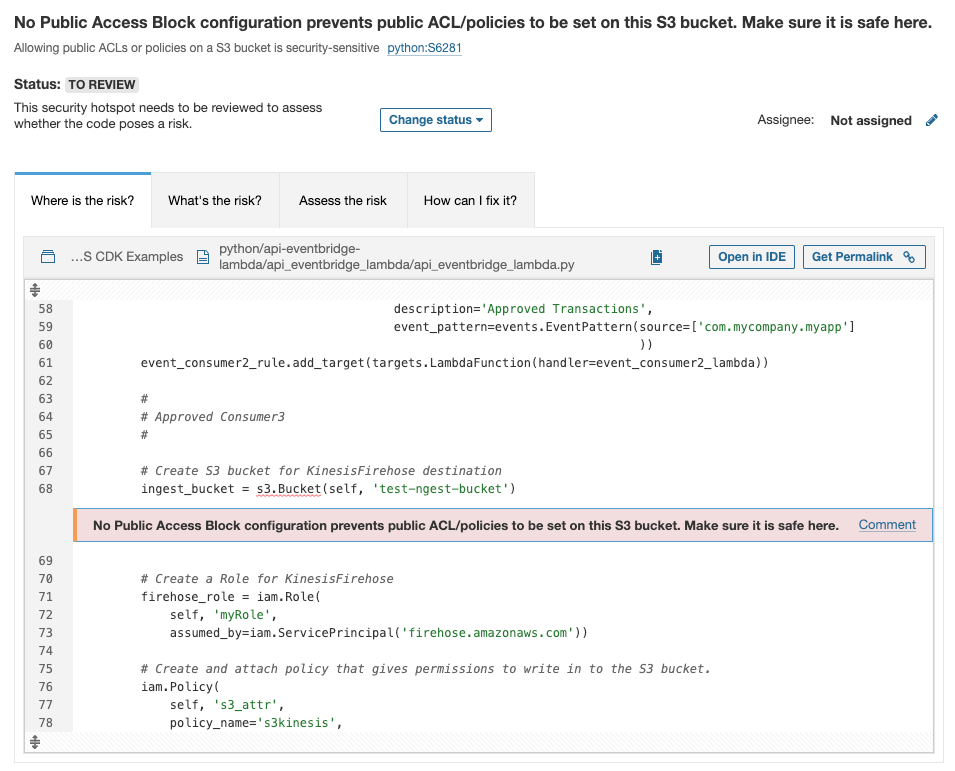
More and more developers are using the AWS CDK to describe their AWS infrastructure, combining the flexibility of a programming language with the complexity of cloud infrastructure.
The CDK provides preconfigured and experience-tested default values, but the creation of patterns and structures can still lead to security misconfigurations.
SonarQube Server 9.9 LTS provides 19 rules to raise security hotspots on AWS CDK code written in Python, to make sure your IaC is as secure as your source code.
New bug-detection rules track dataflow with symbolic execution
SonarQube Server 9.9 LTS adds support for detecting advanced Python bugs using symbolic execution.
The purpose of a symbolic execution engine is to visit all feasible execution paths, even across method calls, to find tricky bugs located in the source code.
Consider the following piece of code:
def hello(name):
print("Hello " + name.upper())
def foo():
name = None
hello(name) # Triggers an AttributeErrorIn this example a variable is initialized to None in a function and its value is used in another function. Accessing an attribute of None triggers an AttributeError.
Here's a more complex example:
def get_field(space, w_node, name, optional):
w_obj = w_node.getdictvalue(space, name)
if w_obj is None:
if not optional:
raise oefmt(space.w_TypeError,
"required field \"%s\" missing from %T", name, w_node)
w_obj = space.w_None
return w_obj
@staticmethod
def from_object(space, w_node):
w_n = get_field(space, w_node, 'n', False)
w_lineno = get_field(space, w_node, 'lineno', False)
w_col_offset = get_field(space, w_node, 'col_offset', False)
_n = w_n
if _n is None:
raise_required_value(space, w_node, 'n') # NoncompliantThere's a lot going on here:
_nis an alias forw_n- Given that the fourth arg of
get_fieldcall isFalse, andw_objwould be None, an exception will be raised, hence there will be no return value fromget_field - Now, the only possible return value of
get_fieldmust be something different thanNone - Hence, the condition
_n is Noneis always False, and some subsequent code is never evaluated.
Mistakes like this are very common and can be very difficult to work out on your own. SonarQube Server 9.9 LTS now raises issues in these cases, with nine total rules detecting similar complex bugs.
These rules are available in commercial editions of SonarQube Server.
Just an upgrade away from it all
SonarQube Server is made by developers, for developers. Our goal is to help all developers be able to write Code Quality.
If you haven’t tried SonarQube Server 9.9 LTS yet, I hope you now have even more reasons to prepare this upgrade with your team. This is a free version upgrade for all, and you can get the LTS in just a few clicks at SonarQube Server Downloads.
Need more help getting started? Check the following resources:
- SonarQube Server LTS Upgrade Checklist
- Get help upgrading using the 9.9 LTS Upgrade category of the Sonar Community
I'd like to thank fellow SonarSourcers Alexandre Gigleux and Andrea Guarino for their contributions to this blog post.