

TL;DR overview
- This post presents Sonar's scoring results across the top three industry benchmarks for Java static application security testing, providing measurable evidence of detection accuracy and false positive rates for Java code analysis.
- SonarQube's Java analyzer demonstrates high true positive rates on benchmarks covering injection vulnerabilities, authentication issues, and insecure API usage common in enterprise Java applications.
- Benchmark comparisons position Sonar's Java SAST alongside other leading tools, helping development and security teams make informed decisions about which static analysis platform to adopt.
- SonarQube Java analysis supports taint analysis, secrets detection, and deeper SAST for third-party library interactions, providing comprehensive security coverage beyond what standard benchmarks measure.
In our previous blog post, we discussed the importance of leveraging benchmarks to track the progress of our SAST capabilities. If you haven't read it, here's a quick summary.
In January 2023, we decided to use popular SAST benchmarks to track the progress of our SAST capabilities but also to be transparent about what should be detected and not detected on these benchmarks to help the overall SAST market raise the bar and bring clarity and eliminate ambiguity. We will publish Sonar’s scores for Java, C#, and Python SAST benchmarks and everything required to reproduce the figures.
Today, we are excited to share more details about the Top 3 Java SAST benchmarks, namely:
- The ground truth corresponding to the list of expected and not expected issues
- How Sonar scores on these selected benchmarks
For those who aren’t familiar, here’s a quick reminder about acronyms we typically use in the context of computing benchmark results:
- TP = number of True Positives = issues expected and detected
- FP = number of False Positives = issues not expected but detected
- FN = number of False Negatives = issues expected but not detected
- True Positive Rate (TPR) = TP / (TP + FN)
- False Discovery Rate (FDR) = FP / (FP + TP)
Our approach
We looked at 109 projects available on GitHub related to SAST benchmarks. This corresponds to projects that are candidates to be considered as benchmarks on which we want to apply our selection criteria. Out of these, we selected the top 3 based on the following criteria:
- The main language is Java
- The project is a vulnerable application even if it was not originally designed as a SAST benchmark because it’s usually what people we talk to (users, prospects, customers), choose to assess the maturity of SAST products
- The project should be not archived
- The project should have test cases corresponding to problems that are in the code and can be detected by a SAST engine.
- The project should have test cases corresponding to web applications
- The project should not be linked to a vendor to avoid bias
Finally, the ordering was done on the popularity of the benchmark, without looking at its internal quality (no judgment) The popularity was determined by a couple of factors:
- the number of GitHub votes
- the number of times prospects or customers talk about it with us
Based on this, we selected these 3 Java projects:
Our findings
At Sonar, we consider that a good SAST solution should have a True Positive Rate at 90% and a False Discovery Rate lower than 10%.
Let's now proceed to share the scores of Sonar on these benchmarks:
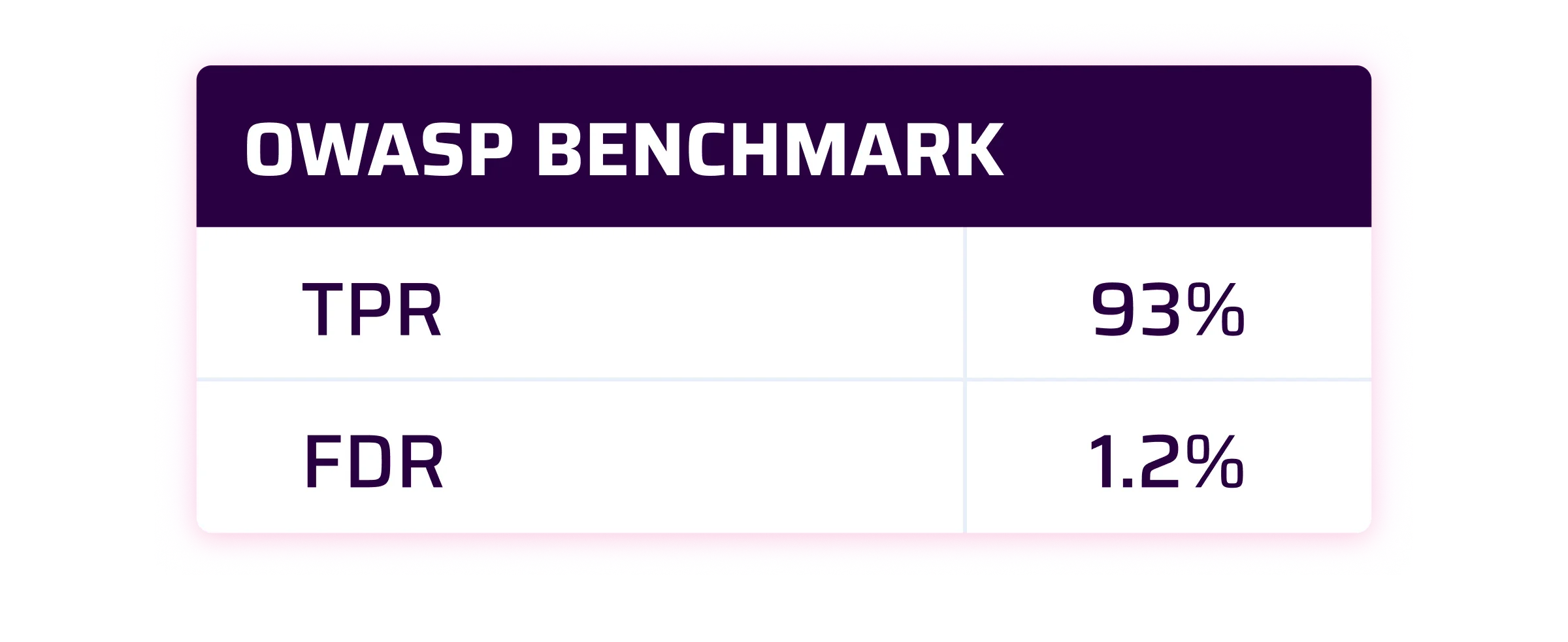

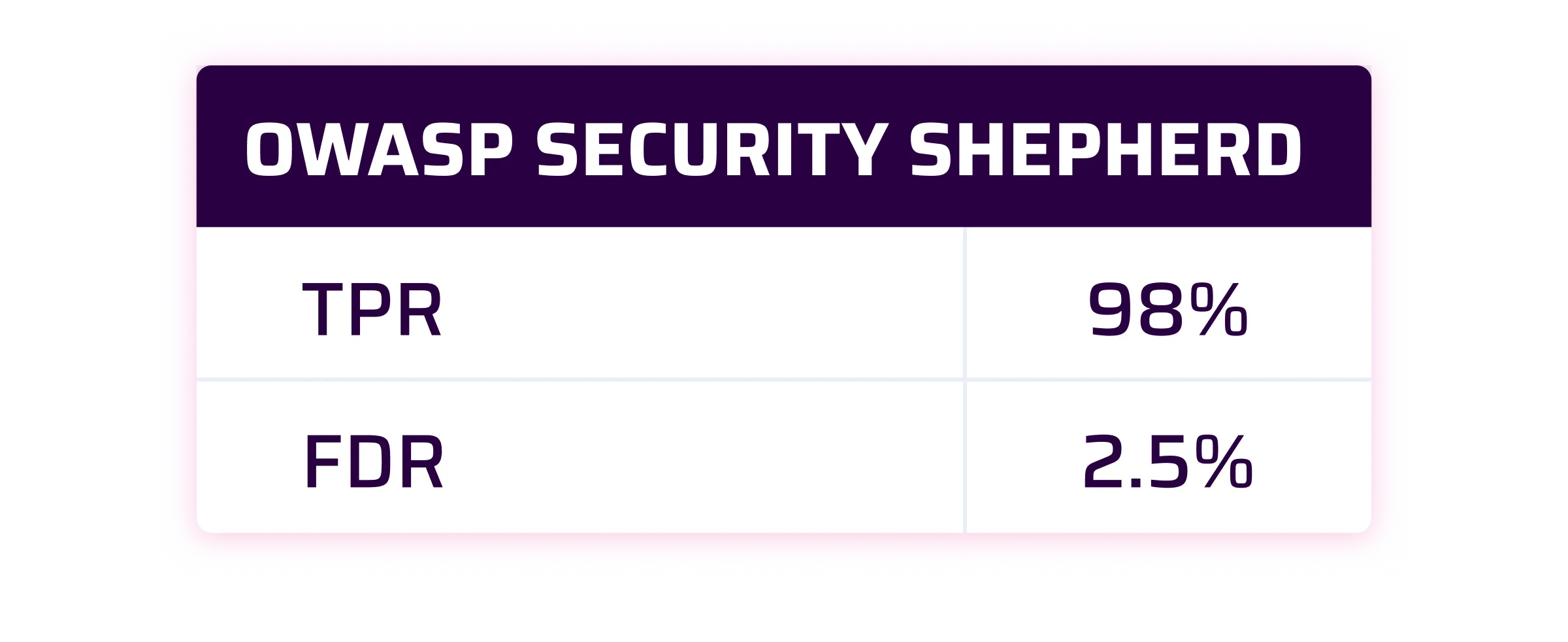
As you can see by yourself, the results are pretty good. For the OWASP Benchmark and SecurityShepherd is even beyond our expectations for the TPR. For WebGoat, we are very close to our own internal target.
In all cases, we will not give up and will continue to improve our Java SAST engine to always provide more accurate and actionable results.
Our computation
We said it in the first part of this blog series, usually SAST vendors just claim but don’t provide anything to reproduce their results. At Sonar, we want to change that. To replicate these results, access the ground truths provided in the sonar-benchmarks-scores repository. It's recommended to utilize the most recent version of either SonarQube Server Developer Edition or SonarQube Cloud.
In addition to the ground truth file for each benchmark, we also provide a special file called ignored-findings.json. Sonar has this unique concept of Security Hotspot. Security Hotspots detect precise code patterns, but the information to know if the finding should be fixed or not is not contained in the code. This is why we request users using our products to manually review detected Hotspots to assess with human eyes if there is really a change to be done. This file is there to simulate this manual activity that only a human can perform to assess for example that no security sensitive data is leaking. In a nutshell, the ignored-findings.json contains the list of Security Hotspots that are safe.
The ground truths correspond to the Sonar AppSec team's perspective on the issues that should be detected or not detected. We acknowledge that we may have made mistakes, so if you come across any misclassifications, please don't hesitate to report them here.
Final word
By sharing the ground truths and showcasing how Sonar scores on these Java SAST benchmarks, our goal is to bring transparency and help companies make well-informed decisions about their SAST solutions. We strongly believe that by sharing our TPR, FDR, and the ground truths, users will gain a better understanding of the effectiveness and accuracy of Sonar's security analyzers. Learn more about Sonar SAST solutions here, and sign up using the simple form below to be notified for the next in the series on Sonar's performance in the Top 3 C# SAST Benchmarks.
Alex
