

TL;DR overview
- This post presents Sonar's scoring results across the top three industry benchmarks for C static application security testing, providing an objective view of detection accuracy and false positive rates for C code analysis.
- SonarQube's C analyzer demonstrates strong performance on benchmarks covering common vulnerability categories including buffer overflows, memory corruption, and injection flaws relevant to systems and embedded code.
- Benchmark results reflect Sonar's ongoing investment in high-accuracy C analysis, including support for MISRA C, CWE Top 25, and CERT C security standards used in safety-critical and enterprise environments.
- The C and C++ analyzer in SonarQube supports all major compilers including GCC, Clang, MSVC, and IAR, enabling analysis across desktop, cloud, and embedded development environments.
In our previous blog posts of this series about SAST benchmarks, we discussed the importance of leveraging benchmarks to track the progress of our SAST capabilities and revealed how Sonar scores on the Top 3 Java SAST benchmarks. We recommend reading these articles before reading this one to get all the context.
Today, we are excited to share more details about the Top 3 C# SAST benchmarks, namely:
- The ground truth corresponding to the list of expected and not expected issues
- How Sonar scores on these selected benchmarks
Our approach
We took the same approach to select the C# SAST benchmarks as the Java ones. Surprisingly, it was harder because there are far fewer projects considered SAST benchmarks in the .NET ecosystem than in the Java one. We looked at 109 projects available on GitHub related to SAST benchmarks. Out of these, we selected these 3 C# projects:
Our findings
At Sonar, we consider that a good SAST solution should have a True Positive Rate of 90% and a False Discovery Rate lower than 10%.
Let's now proceed to share the scores of Sonar against these benchmarks:

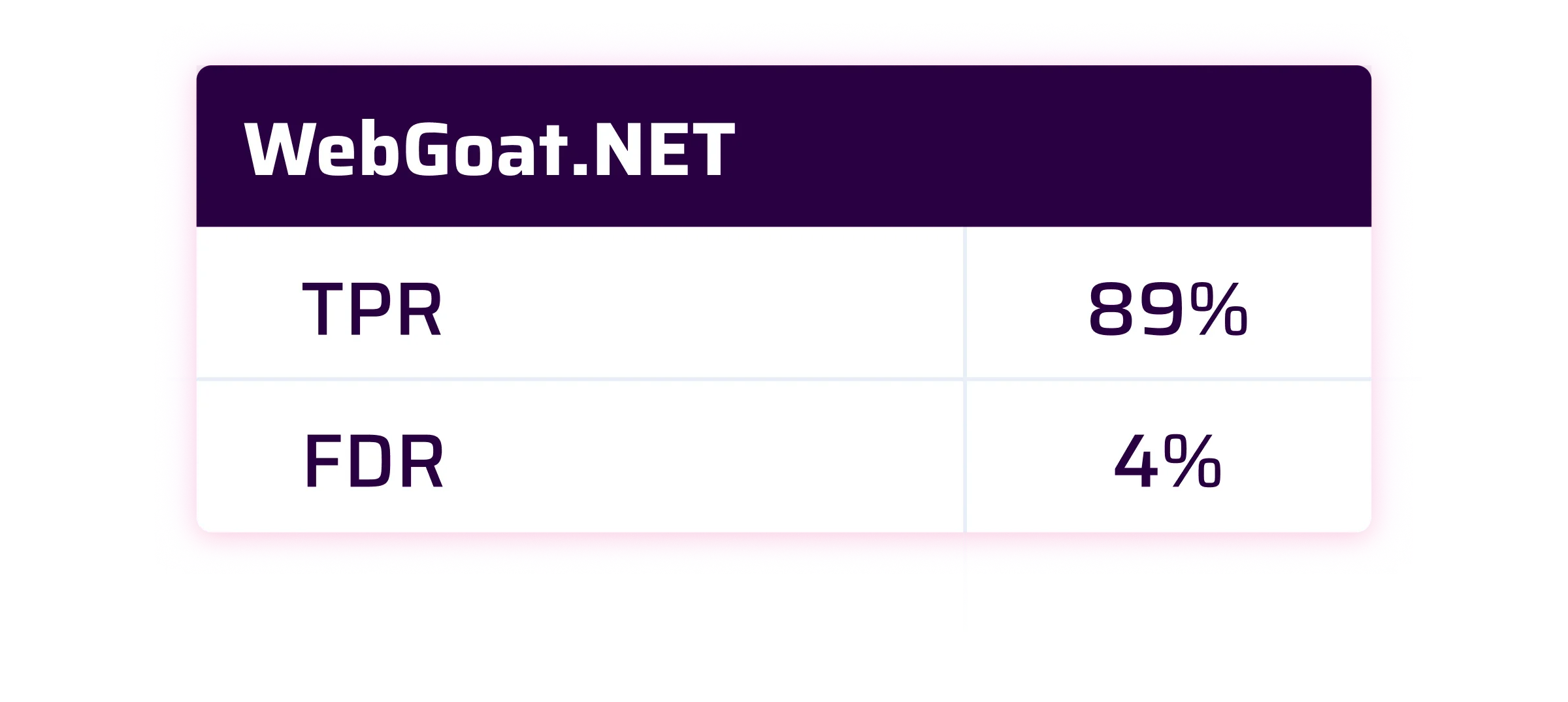

As you will see, the results are pretty good and close on average to our 90% TPR target.
In each case, we will not give up and will continue to improve our C# SAST engine to always provide more accurate and actionable results.
Our computation
We said it in part one of this blog series, usually SAST vendors make claims but don’t provide anything to reproduce or substantiate their results. At Sonar, we want to change that. To replicate these results, access the ground truths provided in the sonar-benchmarks-scores repository. It's recommended to utilize the most recent version of the SonarQube Server Enterprise Edition and here is why.
FlowBlot.NET
The FlowBlot.NET case is a little bit special. It was made to illustrate pure SAST capabilities and it doesn’t rely at all on real-life sources (where the malicious user inputs can be entered) or sinks (where the vulnerabilities can be triggered because of the malicious inputs). To be clearer, it uses fake sources and fake sinks. Out of the box without additional configuration, Sonar will find almost nothing on this project. This is expected because the Sonar security engine is made to find real-world vulnerabilities and has no knowledge about these fake sources and sinks. In order to raise the expected issues, we also had to rely on the Custom Config feature of Sonar’s security engine to declare the fake sources and sinks so that they are considered real ones.
Juliet Test Suite
By default, the Sonar security engine only considers Web/API user inputs and network sockets as sources of vulnerabilities. The Juliet benchmark is a gigantic test suite made of 28,942 test cases covering different domains (security, reliability, maintainability, and more). Of these, 16,968 test cases are related to the security domain. Among these test cases, 4,638 are related to sources that are not supported by default such as injection of command line (CLI) arguments. In order to raise the expected issues, we had to leverage the Custom Config feature of Sonar’s security engine to declare these additional sources. They are also provided in the sonar-benchmarks-scores repository.
Custom Configuration
For more information about the Custom Config feature of Sonar’s security engine, please refer to the SonarQube Server Enterprise Edition documentation (this feature is not available yet on SonarQube Cloud).
The ground truths correspond to the Sonar AppSec team's perspective on the issues that should be detected or not detected. We had to make some choices when building the ground truths because SAST benchmarks can’t be trusted blindly. We acknowledge that we may have made mistakes, so if you come across any misclassifications, please don't hesitate to report them here.
Final word
By sharing the ground truths and showcasing how Sonar scores on these C# SAST benchmarks, our goal is to bring transparency and help companies make well-informed decisions about their SAST solutions. We strongly believe that by sharing our TPR, FDR, and the ground truths, users will gain a better understanding of the effectiveness and accuracy of Sonar's security analyzers.
To finish this blog series, we will soon provide Sonar’s scores on the Top 3 Python Benchmarks.
Alex
