

TL;DR overview
- mXSS (mutation Cross-Site Scripting) exploits HTML's tolerance for malformed markup: a payload appears harmless during sanitization but mutates into malicious code when the browser re-parses it for rendering.
- Parser differentials—differences between how a sanitizer and a browser interpret the same markup—are the root cause; Sonar demonstrated this via CVE-2023-33726 in Joplin, where bypasses led to arbitrary command execution.
- Common mitigations include using client-side sanitizers like DOMPurify, ensuring consistent rendering contexts, and avoiding desanitization—post-sanitization manipulation that inadvertently restores injection vectors.
- mXSS has affected high-profile applications including Google Search; Sonar's research has also identified bypasses in HtmlSanitizer (CVE-2023-44390), Typo3 (CVE-2023-38500), and OWASP java-html-sanitizer.
Cross-site scripting (XSS) is a well-known vulnerability type that occurs when an attacker can inject JavaScript code into a vulnerable page. When an unknowing victim visits the page, the injected code is executed in the victim’s session. The impact of this attack could vary depending on the application, with no business impact to account takeover (ATO), data leak, or even remote code execution (RCE).
There are various types of XSS, such as reflected, stored, and universal. But in recent years, the mutation class of XSS has become feared for bypassing sanitizers, such as DOMPurify, Mozilla bleach, Google Caja, and more… affecting numerous applications, including Google Search. To this day, we see many applications that are susceptible to these kinds of attacks.
But what is mXSS?
(We also explored this topic in our Insomnihack 2024 talk: Beating The Sanitizer: Why You Should Add mXSS To Your Toolbox.)
Background
If you are a web developer, you have probably integrated or even implemented some kind of sanitization to protect your application from XSS attacks. But little is known about how difficult it is to make a proper HTML sanitizer. The goal of an HTML sanitizer is to ensure that user-generated content, such as text input or data obtained from external sources, does not pose any security risks or disrupt the intended functionality of a website or application.
One of the main challenges in implementing an HTML sanitizer lies in the complex nature of HTML itself. HTML is a versatile language with a wide range of elements, attributes, and potential combinations that can affect the structure and behavior of a webpage. Parsing and analyzing HTML code accurately while preserving its intended functionality can be a daunting task.
HTML
Before getting into the subject of mXSS, let's first have a look at HTML, the markup language that forms the foundation of web pages. Understanding HTML's structure and how it works is crucial since mXSS (mutation Cross-Site Scripting) attacks utilize quirks and intricacies of HTML.
HTML is considered a tolerant language because of its forgiving nature when it encounters errors or unexpected code. Unlike some stricter programming languages, HTML prioritizes displaying content even if the code isn't perfectly written. Here's how this tolerance plays out:
When a broken markup is rendered, instead of crashing or displaying an error message, browsers attempt to interpret and fix the HTML as best as they can, even if it contains minor syntax errors or missing elements. For instance, opening the following markup in the browser <p>test will execute as expected despite missing a closing p tag. When looking at the final page’s HTML code we can see that the parser fixed our broken markup and closed the p element by itself: <p>test</p>.
Why it's Tolerant:
- Accessibility: The web should be accessible to everyone, and minor errors in HTML shouldn't prevent users from seeing the content. Tolerance allows for a wider range of users and developers to interact with the web.
- Flexibility: HTML is often used by people with varying levels of coding experience. Tolerance allows for some sloppiness or mistakes without completely breaking the page's functionality.
- Backward Compatibility: The web is constantly evolving, but many existing websites are built with older HTML standards. Tolerance ensures that these older sites can still be displayed in modern browsers, even if they don't adhere to the latest specifications.
But how does our HTML parser know in which way to “fix” a broken markup? Should <a><b> become<a></a><b></b> or <a><b></b></a> ?
To answer this question there is a well-documented HTML specification, but unfortunately, there are still some ambiguities that result in different HTML parsing behaviors even between major browsers today.
Mutation
OK, so HTML can tolerate broken markup how is this relevant?
The M in mXSS stands for “mutation”, and mutation in HTML is any kind of change made to the markup for some reason or another.
- When a parser fixes a broken markup (
<p>test→<p>test</p>), that's a mutation. - Normalizing attribute quotes (
<a alt=test>→<a alt=”test”>), that's a mutation. - Rearranging elements (
<table><a>→<a></a><table></table>), that's a mutation - And so on…
mXSS takes advantage of this behavior in order to bypass sanitization, we will showcase examples in the technical details.
HTML Parsing Background
Summarizing HTML parsing, a 1500~ page-long standard, into one section is not realistic. However, due to its importance for understanding in-depth mXSS and how payloads work, we must cover at least some major topics. To make things easier, we've developed an mXSS cheatsheet (coming later in this blog) that condenses the hefty standard into a more manageable resource for researchers and developers.
Different content parsing types
HTML isn't a one-size-fits-all parsing environment. Elements handle their content differently, with seven distinct parsing modes at play. We'll explore these modes to understand how they influence mXSS vulnerabilities:
- void elements
area,base,br,col,embed,hr,img,input,link,meta,source,track,wbr
- the
templateelementtemplate
- Raw text elements
script,style,noscript,xmp,iframe,noembed,noframes
- Escapable raw text elements
textarea,title
- Foreign content elements
svg,math
- Plaintext state
plaintext
- Normal elements
- All other allowed HTML elements are normal elements.
We can fairly easily demonstrate a difference between parsing types using the following example:
- Our first input is a
divelement, which is a “normal element” element:<div><a alt="</div><img src=x onerror=alert(1)>"> - On the other hand, the second input is a similar markup using the
styleelement instead (which is a “raw text”):<style><a alt="</style><img src=x onerror=alert(1)>">
Looking at the parsed markup we can clearly see the parsing differences:
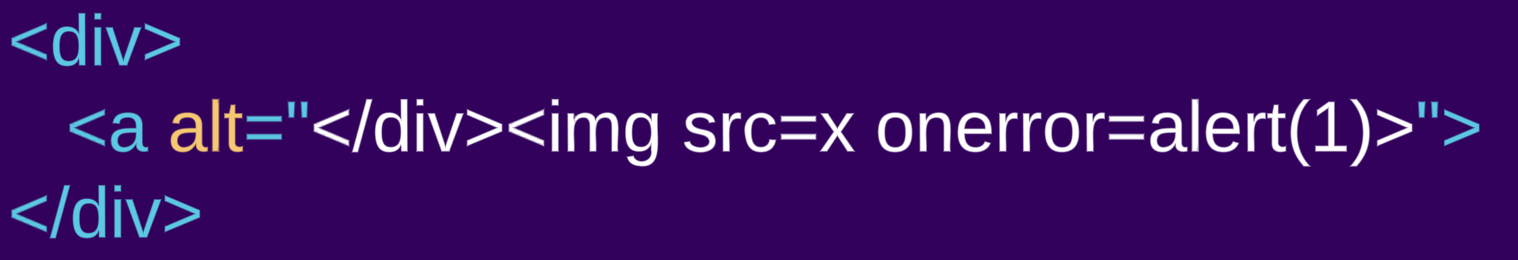

The content of the div element is rendered as HTML, an a element is created. What seems to be a closing div and an img tag is actually an attribute value of the a element, thus rendered as alt text for the a element and not HTML markup. In the style example, the content of the style element is rendered as raw text, so no a element is created, and the alleged attribute is now normal HTML markup.
Foreign content elements
HTML5 introduced new ways to integrate specialized content within web pages. Two key examples are the <svg> and <math> elements. These elements leverage distinct namespaces, meaning they follow different parsing rules compared to standard HTML. Understanding these different parsing rules is crucial for mitigating potential security risks associated with mXSS attacks.
Let's take a look at the same example as before but this time encapsulated inside an svg element:
<svg><style><a alt="</style><img src=x onerror=alert(1)>">
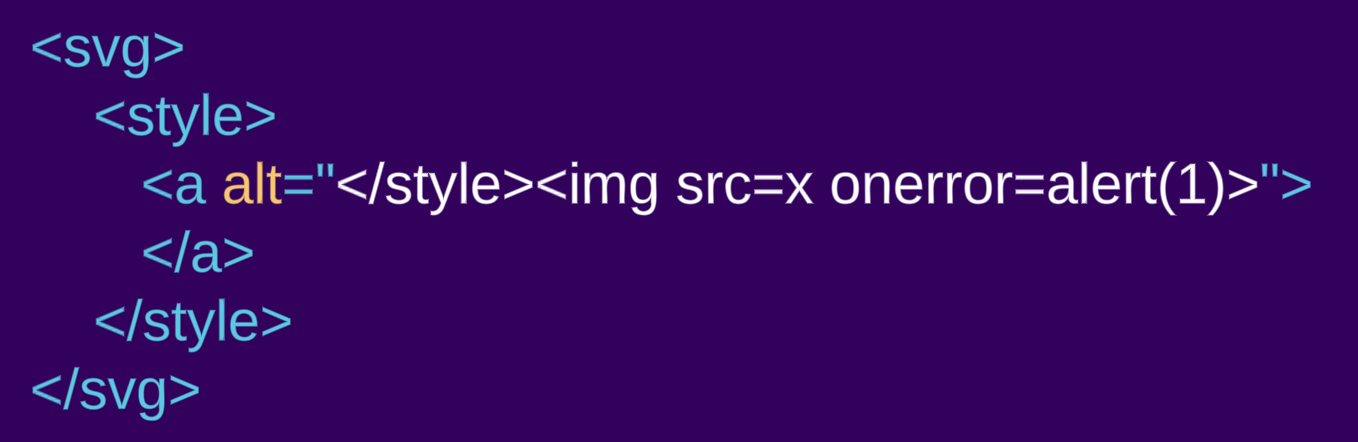
In this case, we do see an a element being created. The style element doesn’t follow the “raw text” parsing rules, because it is inside a different namespace. When residing within an SVG or MathML namespace, the parsing rules change and no longer follow the HTML language.
Using namespace confusion techniques (such as DOMPurify 2.0.0 bypass) attackers can manipulate the sanitizer to parse content in a different way than how it will be rendered eventually by the browser, evading detection of malicious elements.
From Mutations to Vulnerabilities
Often times the mXSS term is used in a broad way when covering various sanitizer bypasses. For better understanding, we will split the general term “mXSS” into 4 different subcategories
Parser differentials
Though parser differentials can be referred to as usual sanitizer bypass, sometimes it is referred to as mXSS. Either way, an attacker can take advantage of a parser mismatch between the sanitizer’s algorithm vs the renderer’s (e.g. browser). Due to the complexity of HTML parsing, having parsing differentials doesn’t necessarily mean that one parser is wrong while the other is right.
Let’s take for example the noscript element, the parsing rule for it is: “If the scripting flag is enabled, switch the tokenizer to the RAWTEXT state. Otherwise, leave the tokenizer in the data state.” (link) Meaning, that depending on whether JavaScript is disabled or enabled the body of the noscript element is rendered differently. It is logical that JavaScript would not be enabled in the sanitizer stage but will be in the renderer. This behavior is not wrong by definition but could cause bypasses such as: <noscript><style></noscript><img src=x onerror=”alert(1)”>
JS disabled:

JS enabled:

Many other parser differentials, such as different HTML versions, content type mismatches, and more, could occur.
Parsing round trip
Parsing round trip is a well-known and documented phenomenon, that says: “It is possible that the output of this algorithm if parsed with an HTML parser, will not return the original tree structure. Tree structures that do not roundtrip a serialize and reparse step can also be produced by the HTML parser itself, although such cases are typically non-conforming.”
Meaning that according to the number of times we parse an HTML markup the resulting DOM tree could change.
Let's take a look at the official example provided in the specification:
But first, we need to understand that a form element cannot have another form nested inside of it: “Content model: Flow content, but with no form element descendants.“ (as written in the specs)
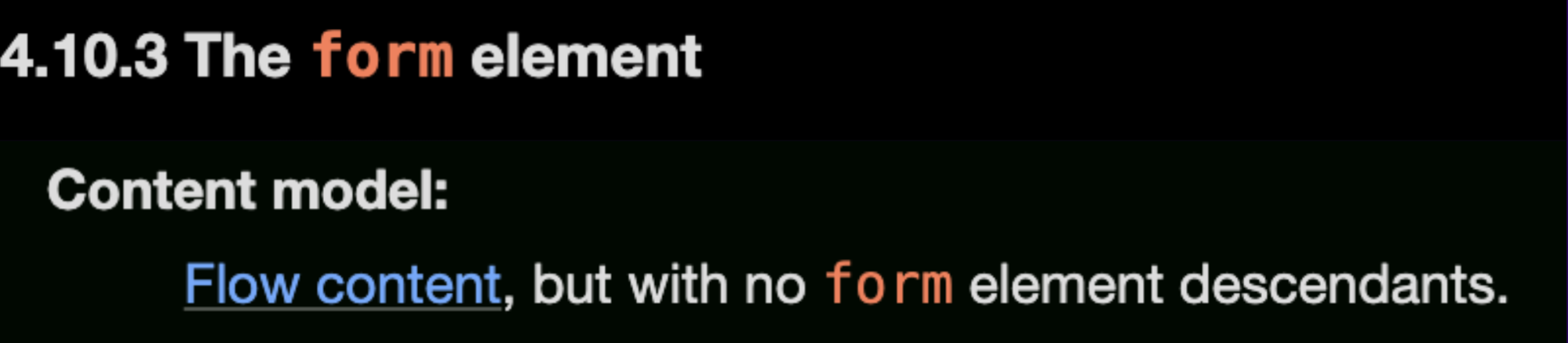
But if we just continue to read the documentation they give an example of how form elements can be nested, by the following markup:
<form id="outer"><div></form><form id="inner"><input>
html
├── head
└── body
└── form id="outer"
└── div
└── form id="inner"
└── inputThe </form> is ignored because of the unclosed div and the input element will be associated with the inner form element. Now, if this tree structure is serialized and reparsed, the <form id="inner"> start tag will be ignored, and so the input element will be associated with the outer form element instead.
<html><head></head><body><form id="outer"><div><form id="inner"><input></form></div></form></body></html>
html
├── head
└── body
└── form id="outer"
└── div
└── inputAttackers can use this behaviour to create namespace confusion between the sanitizer and the renderer resulting in bypasses such as:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
Credit @SecurityMB, covered in-depth here.
Desanitization
Desanitization is a crucial mistake made by applications when interfering with the sanitizer’s output before sending it to the client, essentially undoing the work of the sanitizer. Any small change to the markup could have a major impact on the final DOM tree, resulting in a bypass of the sanitization. We’ve discussed this issue before in a talk at Insomni’Hack and several blog posts, where we identified vulnerabilities in various applications, including:
- Pitfalls of Desanitization: Leaking Customer Data from osTicket
- Code Vulnerabilities Put Proton Mails at Risk
- Remote Code Execution in Tutanota Desktop due to Code Flaw
- Code Vulnerabilities Put Skiff Emails at Risk
Here is an example of desanitization, an application takes the sanitizer output and renames the svg element to custom-svg, this changes the namespace of the element and could cause XSS when re-rendering.
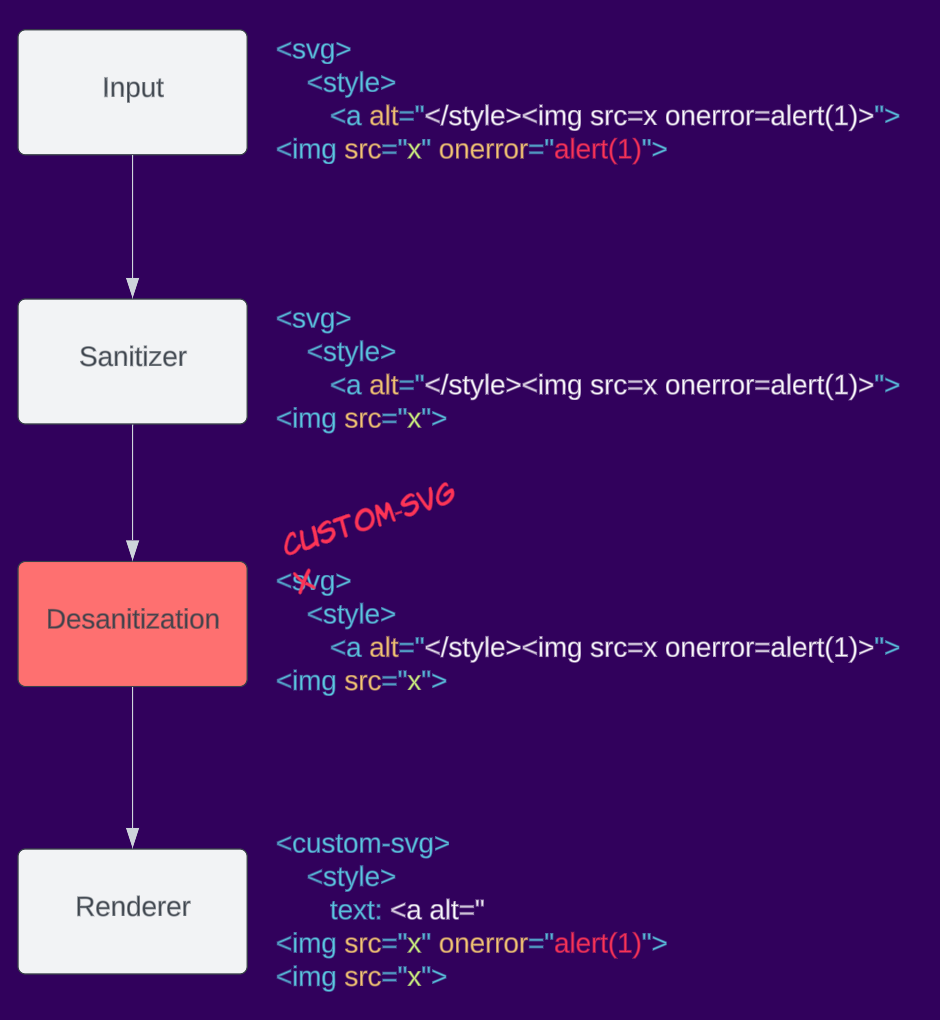
Context-dependent
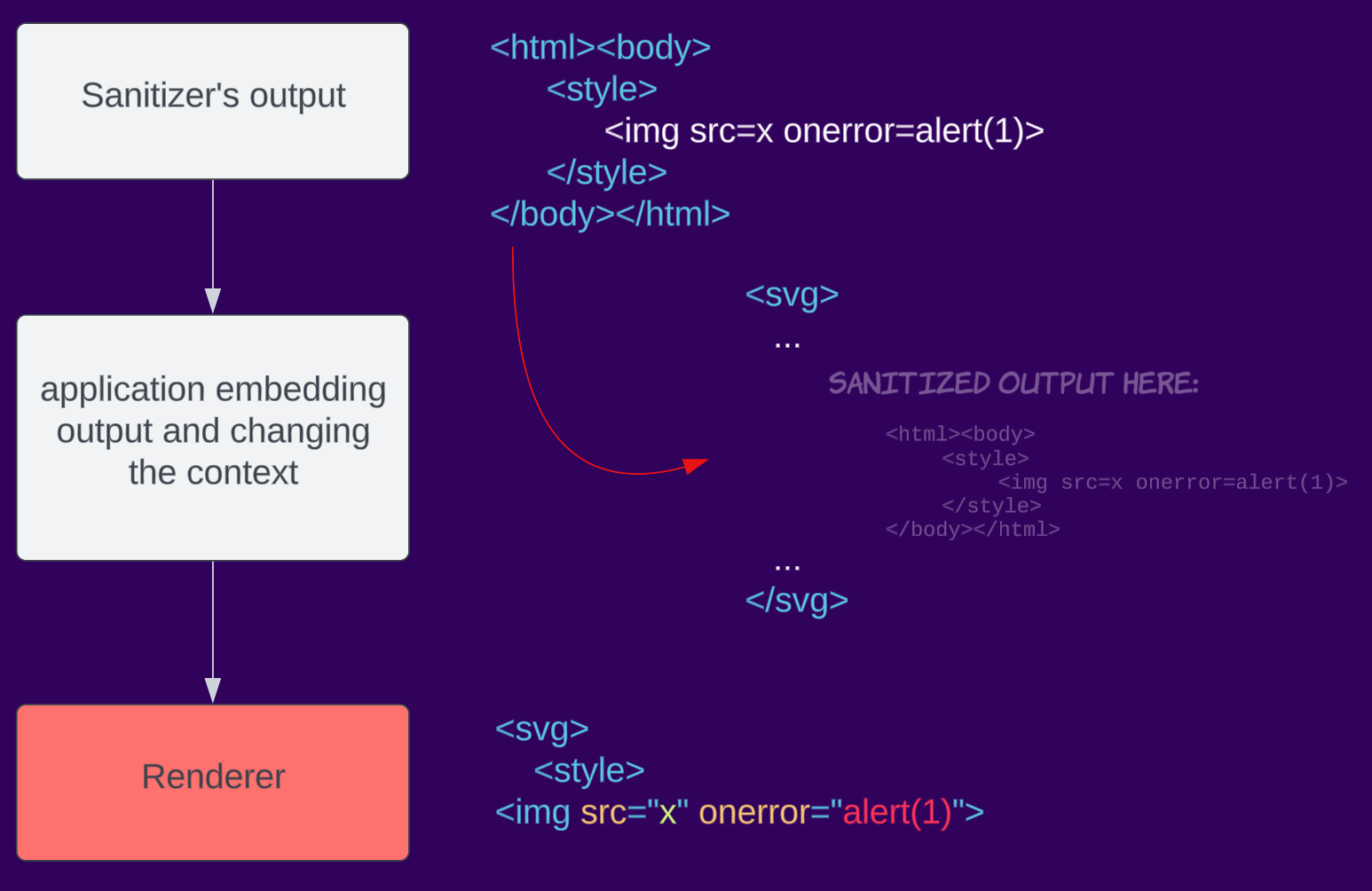
HTML parsing is complex and can be different depending on the context. For example, parsing a whole document is different from fragment parsing in Firefox (see Browser Specific section on the cheatsheet). Dealing with the change from sanitizing to rendering in the browser, developers might mistakenly change the context in which the data is rendered causing parsing differential and eventually bypassing the sanitizer. Because third-party sanitizers are not aware of the context in which the result will be put, they cannot address this problem. This is aimed to be solved when browsers implement a built-in sanitizer (Sanitizer API effort).
For example, an application sanitizes an input, but when embedding it into the page, it encapsulates it in SVG, changing the context to an SVG namespace.
mXSS Case Studies
While we have published blog posts in the past covering mXSS vulnerabilities, such as Reply to calc: The Attack Chain to Compromise Mailspring, we have also reported various sanitizer bypasses, such as mganss/HtmlSanitizer (CVE-2023-44390), Typo3 (CVE-2023-38500), OWASP/java-html-sanitizer, and more.
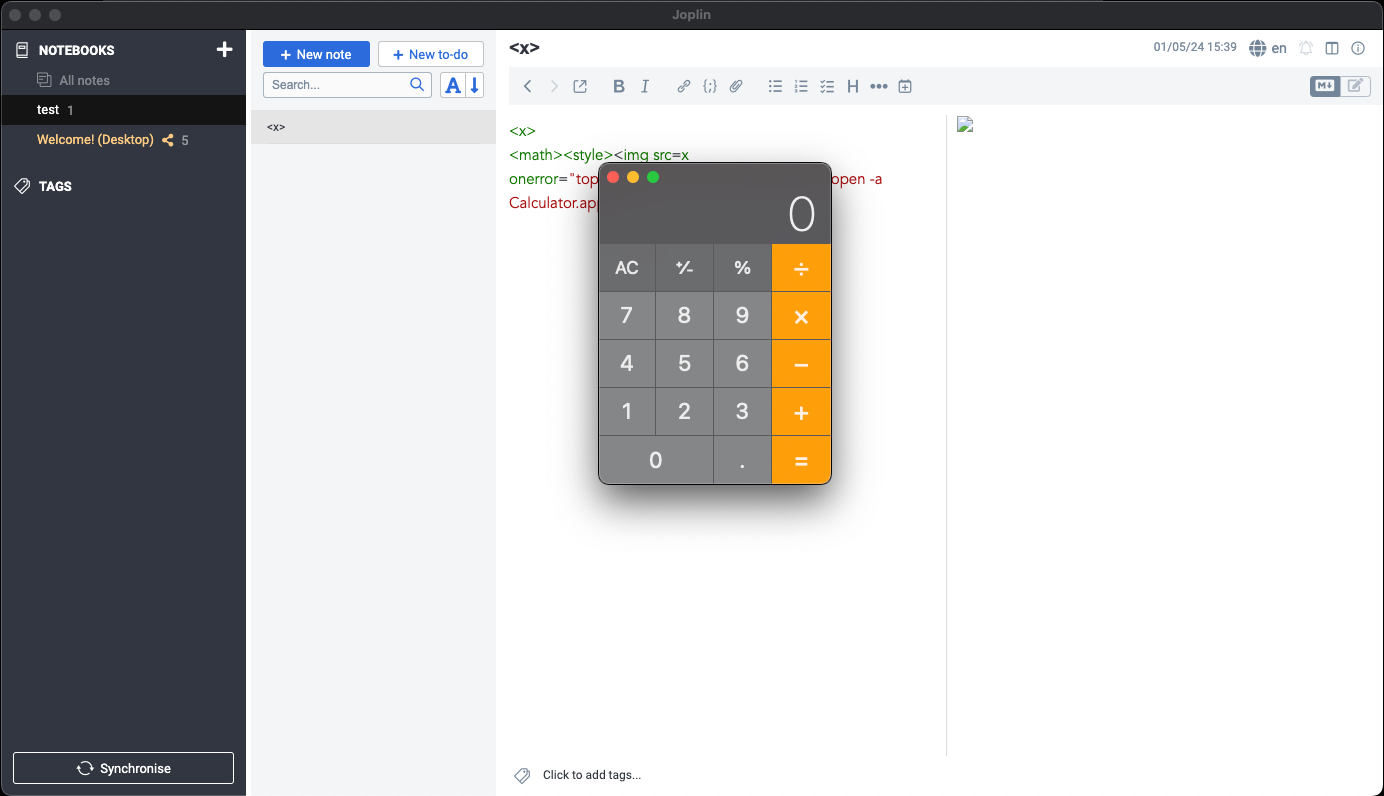
But let's take a look at one simple case study in a software named Joplin (CVE-2023-33726), a note-taking desktop app written in electron. Due to unsafe electron configurations, JS code in Joplin can use Node internal functionalities enabling an attacker to execute arbitrary commands on the machine.
The origin of the vulnerability resides in the sanitizer’s parser, which parses untrusted HTML input via the htmlparser2 npm package. The package itself claims that they don’t follow the specification and prefers speed over accuracy: “If you need strict HTML spec compliance, have a look at parse5.”
Very quickly we noticed ways that this parser doesn’t follow the specification. With the following input, we can see that the parser is oblivious to different namespaces.

While the sanitizer’s parser doesn’t render the img element, the renderer does. This is an example of Parser Differential, an attacker can simply add onerror event handler which will execute arbitrary code when a victim opens a malicious note.
This specific finding was also found independently by @maple3142
Mitigation
Unfortunately, there is not one simple mitigation solution. We encourage developers to understand this bug class in depth so that they can make a better decision about how to mitigate this issue according to their application.
During our research, we came across a number of mitigation approaches and security measures that developers took in order to tackle the issue of mXSS (also available in the cheatsheet):
Sanitize client side
- This is probably the most important rule to follow. Using sanitizers that run on the client side, such as DOMPurify, avoids parser differentials risk. Due to the complexity of parsing and most likely serving content to different parsers (Firefox vs Chrome vs Safari etc…), it is impossible to avoid differentials when HTML is parsed not in the same place where the content is eventually rendered. For that reason, server-side sanitizers are prone to fail.
- When using Server-Side Rendering (SSR) with a client-side JS framework, it can be easy to drop in libraries like isomorphic-dompurify. They let client-side sanitizers like DOMPurify “just work” in SSR mode. But to achieve this, they also introduce a server-side HTML parser like jsdom, which introduces parser differential risks. The safest option for web apps using SSR is to disable SSR for user-controlled HTML and defer the sanitization and rendering to the client-side only.
Don’t reparse
- In order to avoid “Round trip mXSS” the application can insert the sanitized DOM tree directly into the document unlike serializing and re-rendering the content.
Note that this approach can be done only when the sanitizers are implemented on the client side and might cause unexpected behaviors (such as rendering content differently due to not adapting to the context of the page).
Always encode or delete raw content
- Because the idea of mXSS is to figure out a way for a malicious string to be rendered as raw text in the sanitizer but parsed as HTML later, not allowing/encoding any raw text in the sanitizer stage would make it impossible to re-render it as HTML.
Note that this could break some things such as CSS code.
Not supporting foreign content elements
- Not supporting foreign content elements (deleting svg/math elements and their content not renaming) in your sanitizers reduces complexity significantly.
Note this doesn’t mitigate mXSS but offers a precaution step.
Future
Such a complex subject with no simple solution, is there a bright future?
The answer is yes, luckily there are a number of proposals and actions taken in order to put this bug class to an end or at least address it officially.
The biggest problem today is that the responsibility of sanitizing untrusted HTML input falls on third-party developers, whether it's the application devs or sanitizer devs. This is impractical due to the complexity of the task and the fact that they would need to address different renderer parsers (different users use other browsers) and keep up to date with the evolving HTML specifications. A more correct way to approach this is making it the renderer’s responsibility to make sure there is no malicious content in the markup. Having a built-in sanitizer in the browser for example could eliminate most if not all bypasses we see up to this day.
The Sanitizer API initiative is exactly that. It is currently under development by the Web Platform Incubator Community Group (WICG) and is meant to provide developers with an integrated, robust, and context-aware sanitizer written by browsers themselves (no more parser differentials nor reparsing). Wider browser adoption of the Sanitizer API would likely lead to developers' increased use of it for safer HTML manipulation.
Another effort taken to tackle this issue is specs updates, for example, Chrome now encodes < and > characters in attributes
<svg><style><a alt="</style>"> → <svg><style><a alt="</style>">
Evolving the fundamentals of the HTML definitions to a safer future.
mXSS cheatsheet 🧬🔬
We have created mXSS cheatsheet meant to be a one-stop shop for anyone who is interested in learning, researching, and innovating in the world of mXSS. Helping users to see unexpected HTML behavior in a simplified list, unlike reading 1500~ pages of documentation. We encouraged users to contribute and help drive this effort forward together.
Summary
mXSS (mutation cross-site scripting) is a security vulnerability that arises from the way HTML is handled. Even if a web application has strong filters in place to prevent traditional XSS attacks, mXSS can still sneak through. This is because mXSS exploits quirks in the HTML behavior, blinding the sanitizer to malicious elements.
This blog dove into mXSS, providing examples, splitting this big “mXSS” name into subsections, and covering developer mitigation strategies. By equipping you with this knowledge, we hope developers and researchers can confidently address this issue in the future.