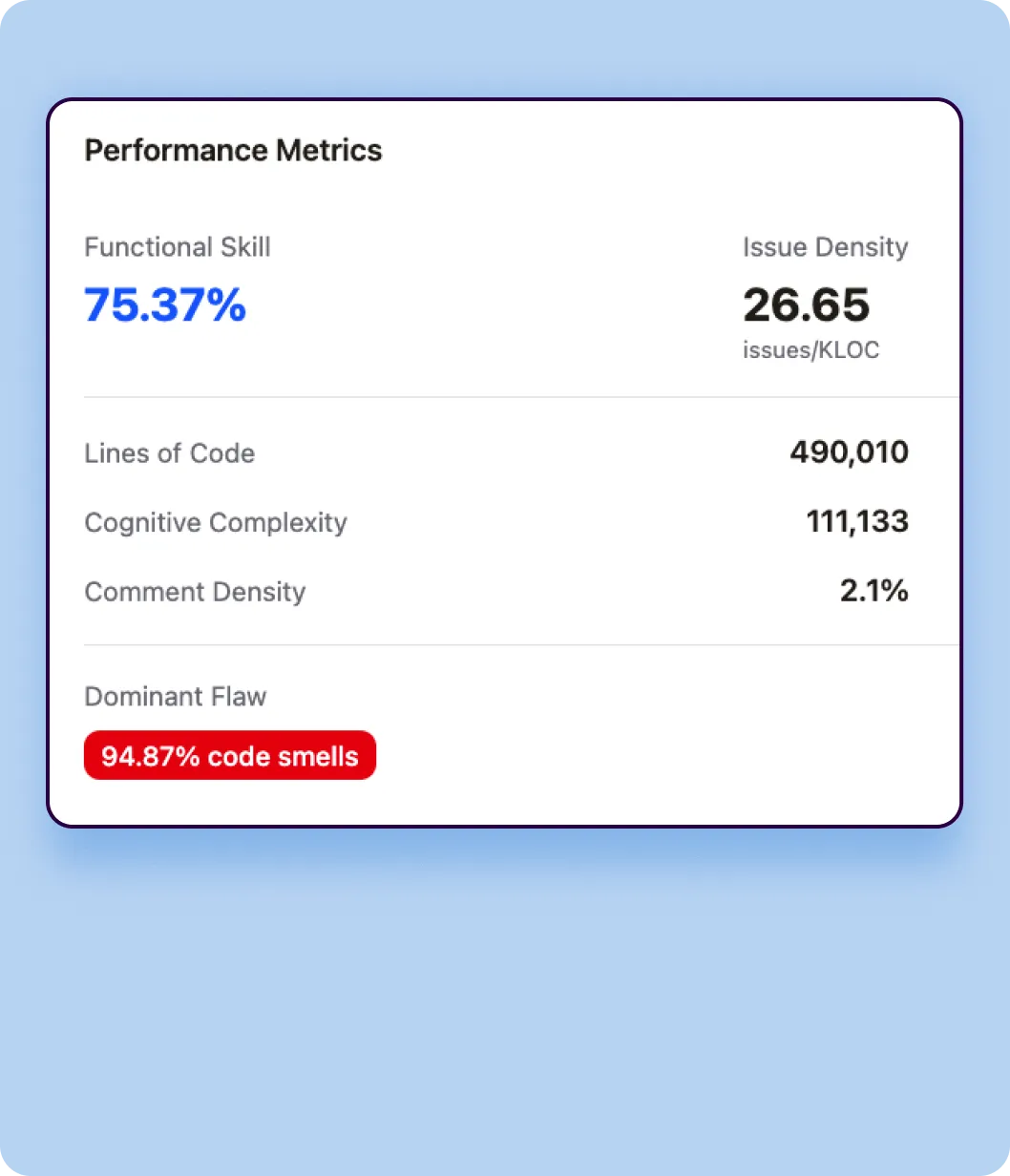
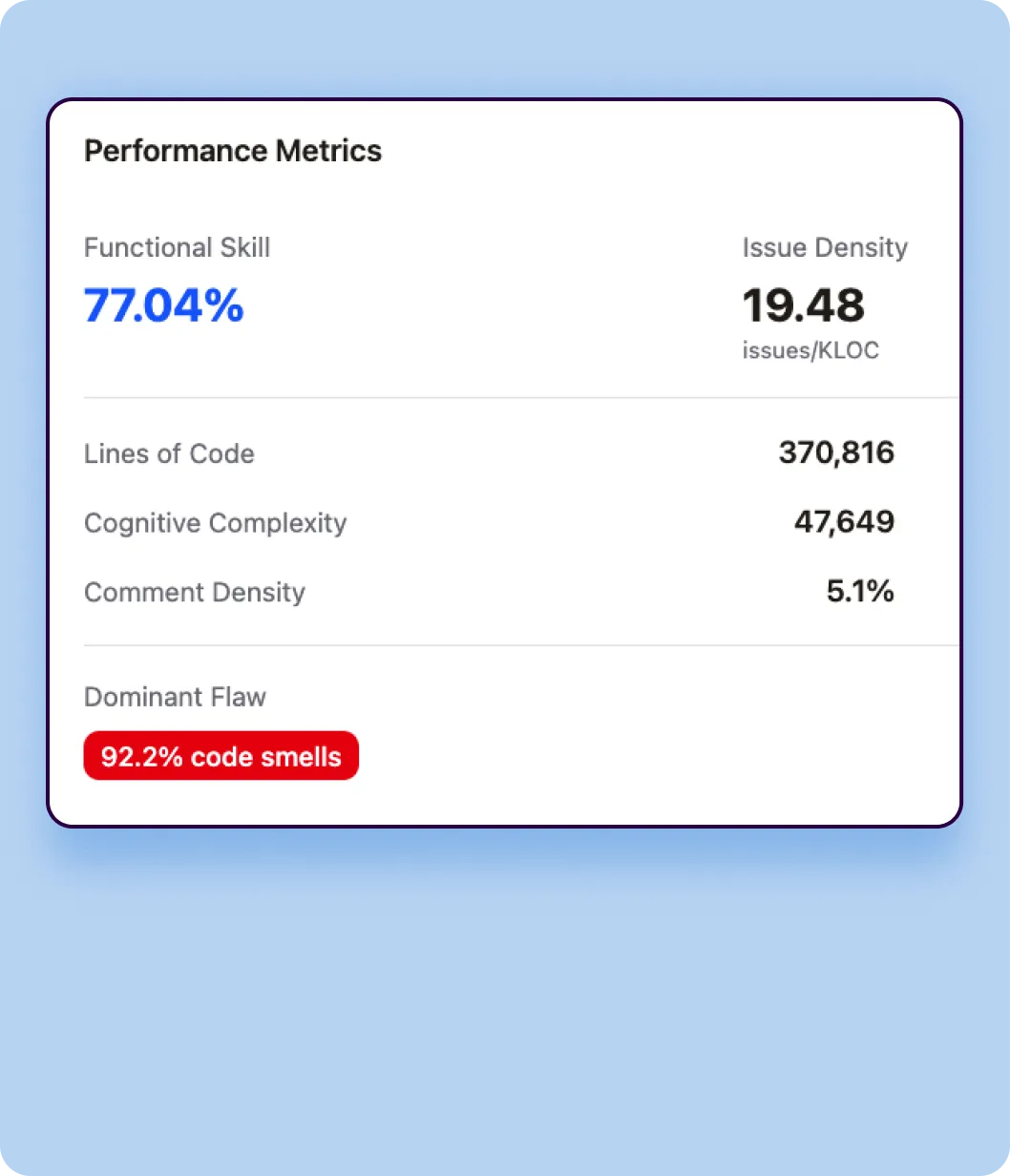
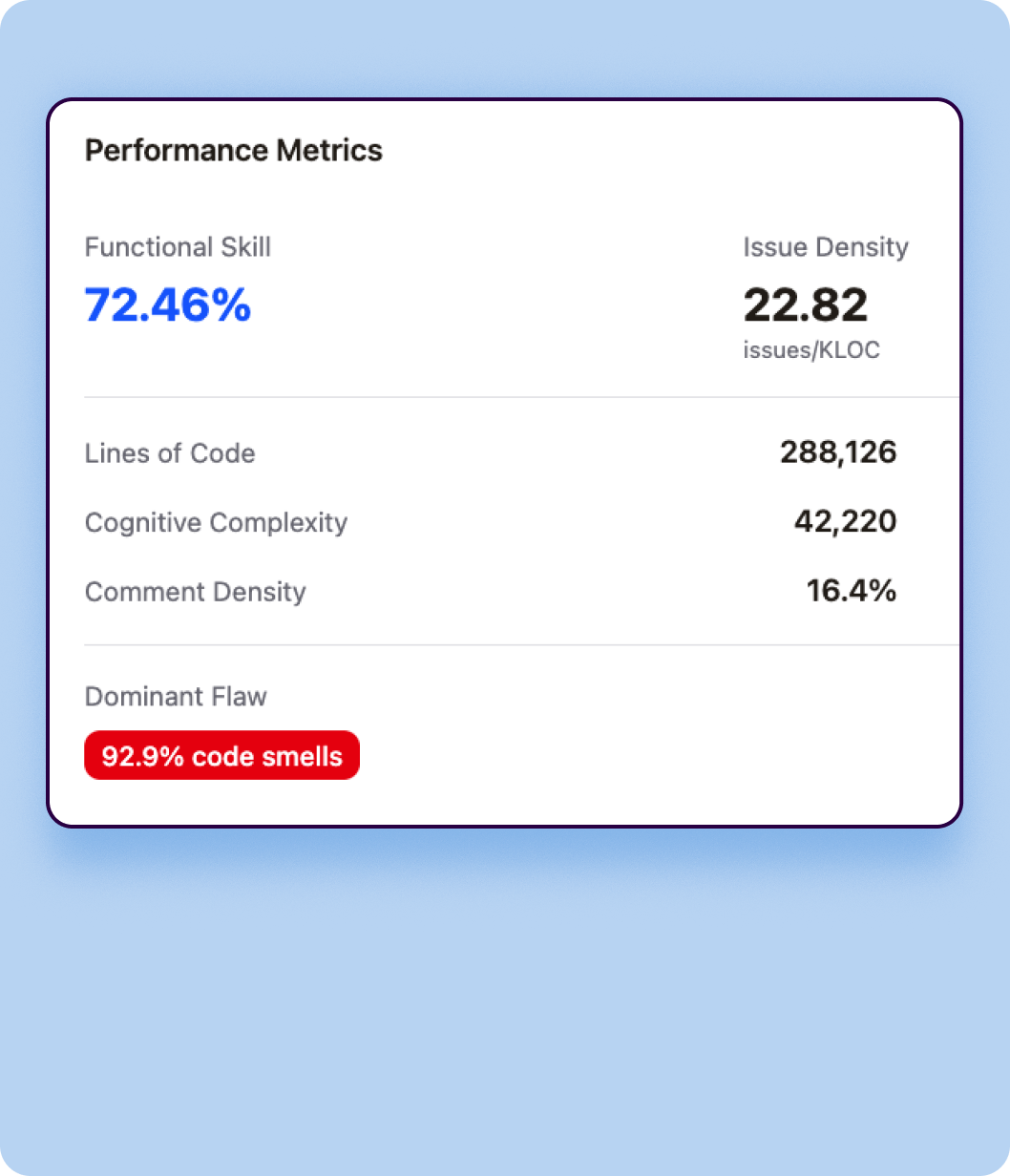
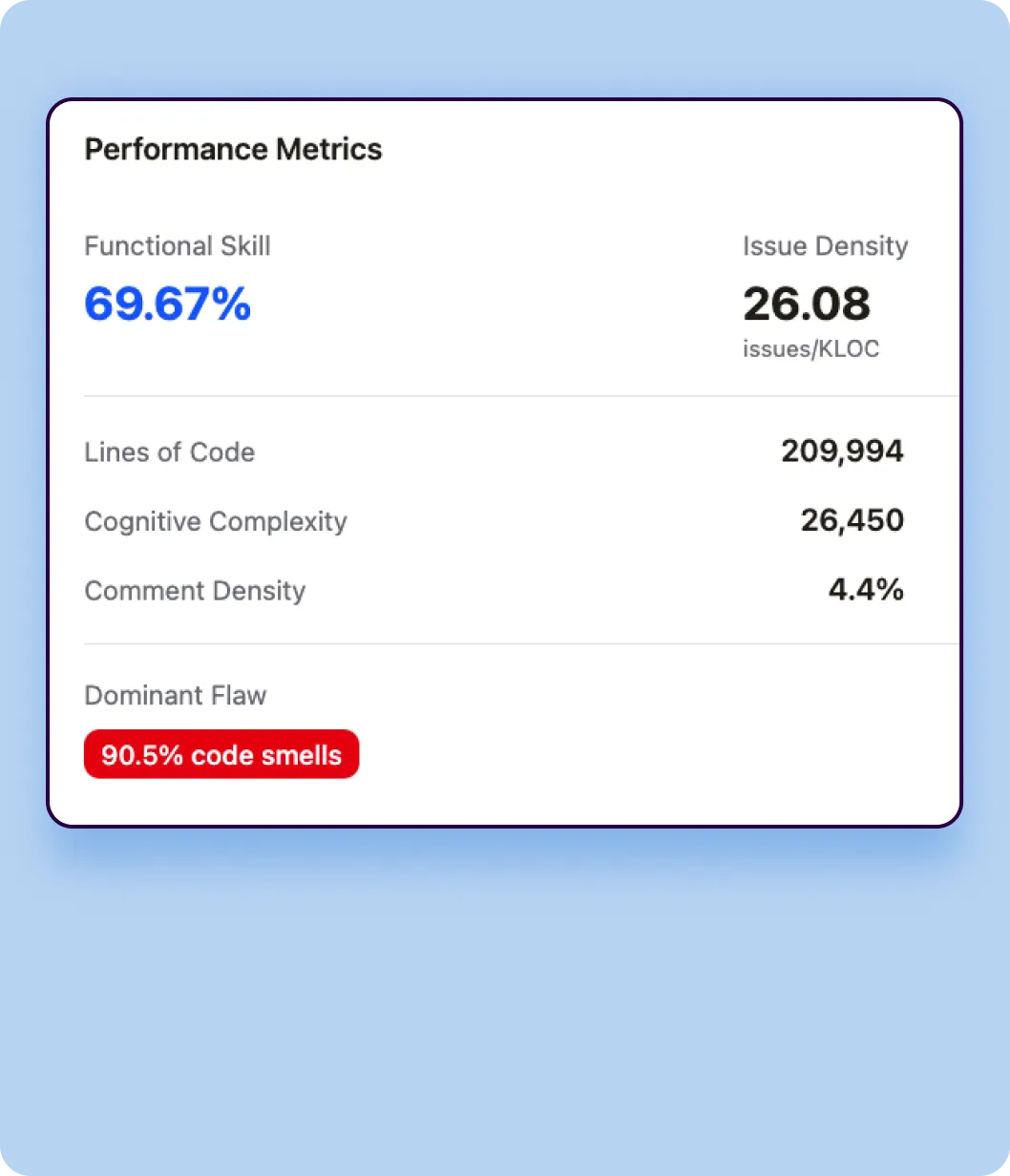
Verbosity Measurement
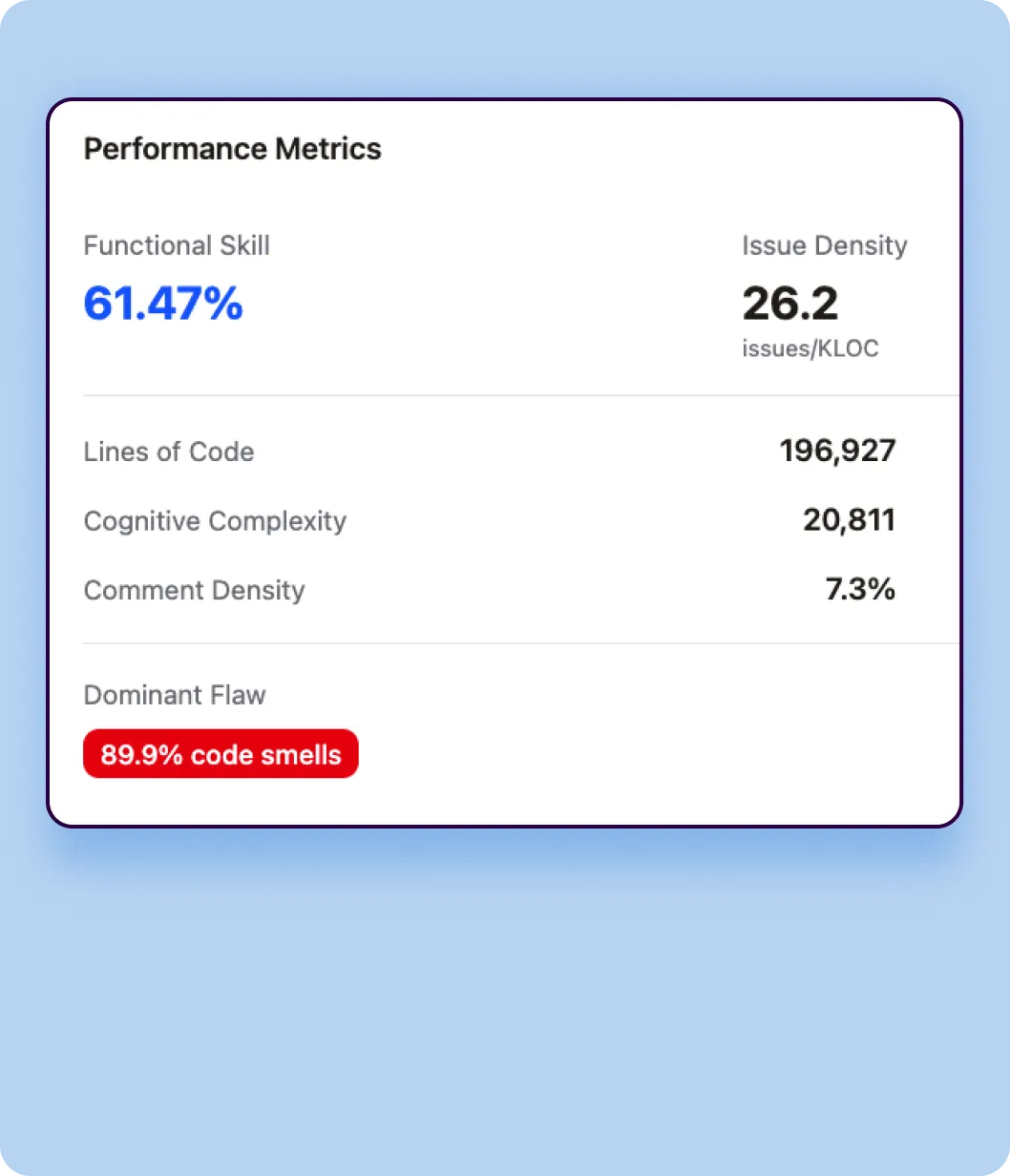
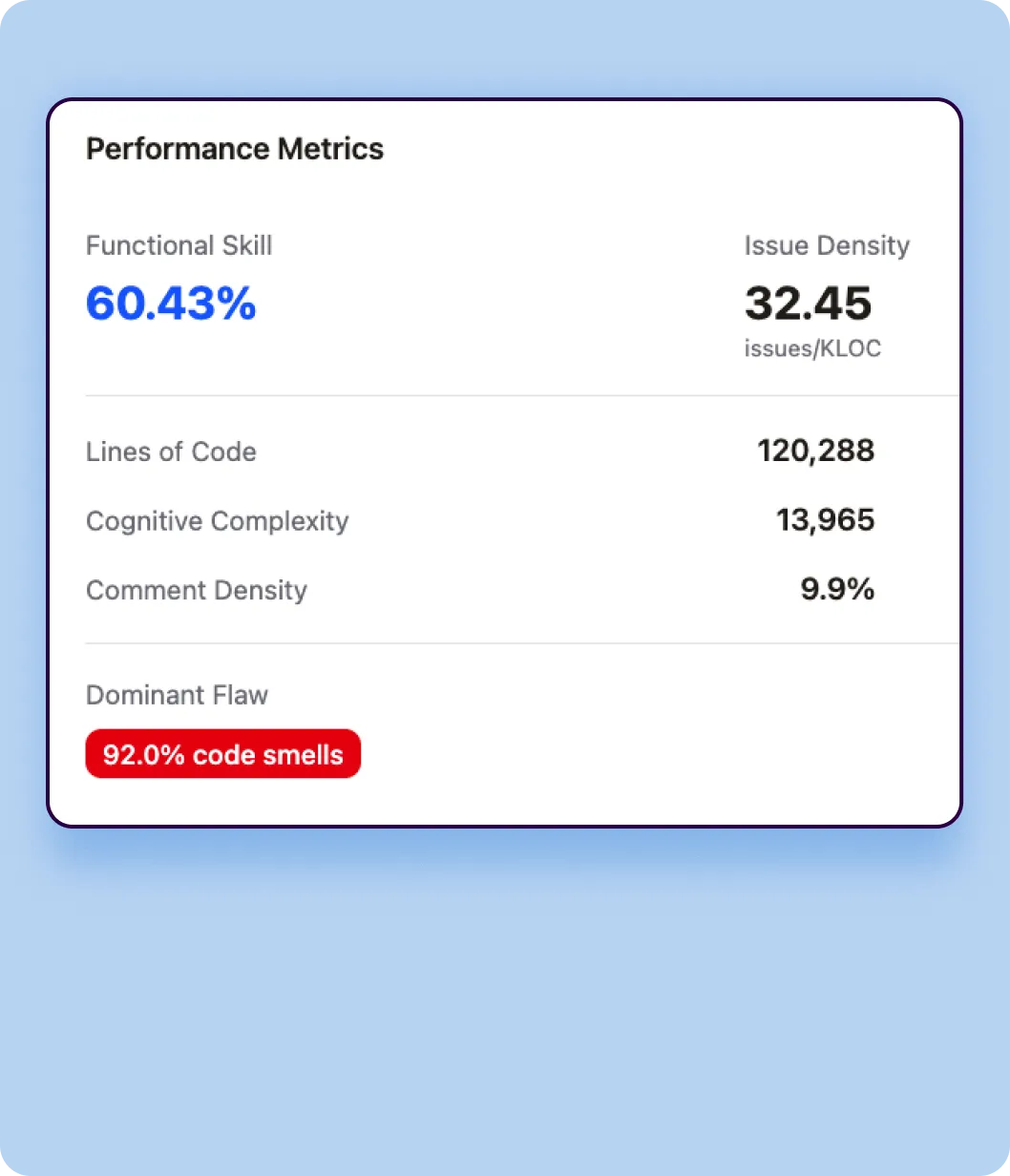
Verbosity quantifies the sheer volume of code each model generates to solve identical tasks.
- Lines of Code (LOC)
Total number of lines of code generated across all 4,442 tasks, including blank lines and comments. This metric reveals whether a model tends toward concise or elaborate implementations. - Token Count
Total tokens generated in the code output, providing a language-agnostic measure of code volume that accounts for the actual content density. - Code Density
Ratio of executable statements to total lines, indicating how compact or spread out the code structure is.