
TL;DR overview
- LLM code generation uses generative AI, natural language processing, and machine learning to write software code from natural language descriptions.
- Key quality dimensions for evaluating AI-generated code include accuracy, correctness, efficiency, maintainability, readability, and security.
- Research findings show that LLM-generated code introduces quality and security risks that require independent static analysis to detect reliably.
- SonarQube provides the verification layer to assess and enforce quality standards on code produced by large language models.
Large language model (LLM) code generation involves using generative AI (GenAI) to write software code.
By leveraging natural language processing (NLP), machine learning (ML) algorithms, and deep learning, these models are trained on vast amounts of existing programming code.
When given a brief description of functionality in natural human language, the LLM can generate the source code for complex computer programs with speed and accuracy.
Often integrated into IDEs, these LLMs can help with code completion, refactoring, and optimization.
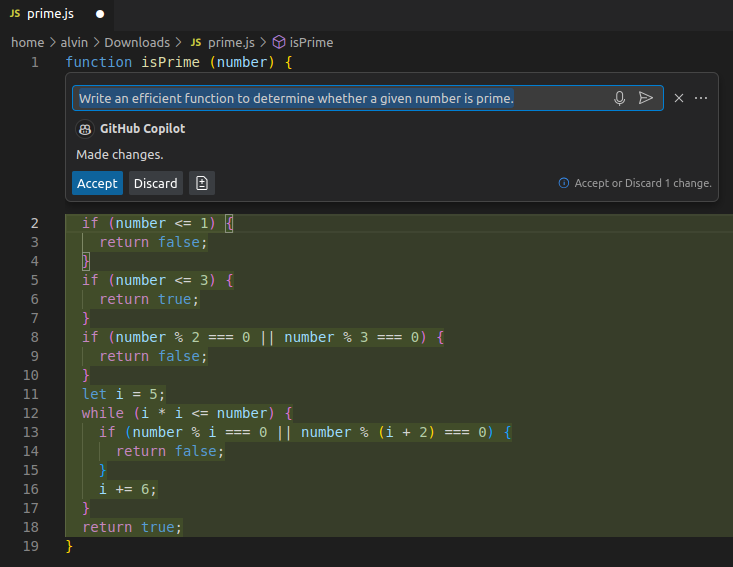
Using GitHub Copilot within VSCode to generate JavaScript based on natural language instructions
The Importance of Code Quality in Software Development
High-quality code is crucial for the success of software projects. It ensures reliability, reduces maintenance costs, and improves user experience by minimizing bugs and enhancing performance.
"Quality" in the Context of Generated Code
Code quality reflects how well software meets both the functional requirements set by stakeholders—including its performance specifications—and non-functional standards like security and usability.
When evaluating AI-generated code, developers should consider several specific aspects of quality to ensure that the software is up to par. The key areas to focus on are:
- Accuracy: Does the code do what it's supposed to?
- Correctness: Are there any bugs?
- Efficiency: Does the code execute tasks without wasting resources?
- Maintainability: How easy is it to update and modify?
- Readability: Is the code easy to understand?
- Security: How well does the code protect against vulnerabilities?
Summary of the Findings of Quality of LLM-generated Code
In the realm of code generation, a few code LLMs have garnered significant attention due to their capabilities and the quality of code they produce. Among the most well-known are:
- Codex: Created by OpenAI, the maker of ChatGPT, and used originally to power GitHub Copilot
- StarCoder: Created by Hugging Face
- Code Llama: Created by Meta (formerly Facebook)
- PaLM 2: Create by Google AI
In this section, we’ll explore the intersection between code-generating LLMs and code quality.
Source of data
Looking at the four widely adopted LLMs we listed above, we see that each was developed using vast datasets of existing code. However, their approaches have nuances:
- Codex: Began with GPT-3 and then further trained on a large dataset of diverse code samples from GitHub (159 GB of Python code and 54 million GitHub repositories), ensuring a broad understanding of software engineering paradigms.
- StarCoder: Also trained on a vast dataset from GitHub that covered over 80 programming languages, and then further trained on Python.
- Code Llama: Began with Llama 2, applied fine-tuning with additional training on code-specific datasets.
- PaLM 2: Uses an multilingual dataset mixture that includes hundreds of human and programming languages, mathematical equations, and scientific papers.
It should be noted that, by the middle of 2023, OpenAI began to deprioritize Codex in favor of GPT-4, which was said to outperform Codex in code generation.
Documentation for each of these LLMs provides more details about training datasets, methods, and performance against industry-accepted benchmarks.
Human-written vs. AI-generated code
When comparing code written by humans with code generated by artificial intelligence, several differences become apparent.
AI often excels in completing straightforward, repetitive coding tasks quickly—and without fatigue—surpassing typical human efficiency.
However, for complex, nuanced tasks that require deep understanding or creative problem-solving, LLMs occasionally generate incredibly incorrect solutions, presenting “equal confidence regardless of the certainty of the answer.”
Therefore, while its code’s readability, maintainability, and efficiency has significantly improved in recent years, AI code still often requires human oversight for optimization and refinement.
Coding standards used
Adherence to coding standards is critical for ensuring that the generated code not only functions correctly but also seamlessly integrates into existing systems.
Because these LLMs have been trained on vast datasets that include large, open-source codebase repositories, their experiences with different coding standards, conventions, and syntax formatting across all major programming languages are broad.
Security
Security in AI-generated code remains a paramount concern.
While LLMs can generate code quickly, ensuring that this code is secure from vulnerabilities requires ongoing careful review and refinement.
LLMs tend to reflect the security practices present in their training data, meaning that any systemic weaknesses in training-set source code can propagate into the generated results.
Therefore, continuous updates and security audits are essential to improve the robustness of LLM-generated code against potential threats.
LLM Code Generation Challenges and limitations
Code-generating LLMs are state-of-the-art technology, which also means they are still evolving.
While they have tremendous potential for making programmers more efficient, several of the models’ challenges and limitations should be considered.
Debugging and complexity
Debugging AI-generated code can present some unique challenges.
These AI models can produce complex code blocks that, while functionally correct, may be difficult for developers to understand and troubleshoot.
When the code involves intricate logic or integrates with existing systems, this problem may be compounded even further.
In all things GenAI, end-users continue to grapple with the apparent opacity of AI decisions.
Code generation is no exception.
At times, a developer may find it difficult to trace why a model generated specific code snippets.
Source and training data
The quality and scope of training data used for an LLM significantly influence the performance of LLMs.
For any LLM, biased or incomplete training data will lead to flawed results.
Because the high-profile code-generating LLMs we’ve highlighted in this article have been trained on vast, comprehensive, and diverse datasets, the issues of bias or incompleteness may not be as much of a concern.
However, if a developer chooses to adopt an LLM that has been trained on smaller or incomplete datasets, the potential for coding flaws should be given serious attention.
Also, bear in mind the large volumes of data required to train these code models.
This may raise concerns about data privacy and the potential inclusion of proprietary or sensitive information.
Ensuring that data is representative, ethically sourced, and free of biases is a continual challenge.
LLMs designed by large enterprises for global-scale use often address these data issues.
For example, Google AI makes this statement about PaLM2:
We apply our Responsible AI Practices, filter duplicate documents to reduce memorization, and have shared analysis of how people are represented in pre-training data…. We evaluate potential harms and bias across a range of potential downstream uses for PaLM 2 and its version updates, including dialog, classification, translation, and question answering. This includes developing new evaluations for measuring potential harms in generative question-answering settings and dialog settings related to toxic language harms and social bias related to identity terms.
Code generation for specific use cases or niches
LLMs are adept at handling general programming tasks.
However, their performance when tasked with specialized or niche apps can vary dramatically.
For example, generating code for highly specialized hardware or software platforms or industries with strict regulatory requirements might be problematic.
These scenarios require not just technical accuracy but also deep contextual understanding, which LLMs may lack.
Sonar and LLM Code Generation
Incorporating Sonar into your LLM-based code generation pipeline ensures that the code is of the highest quality, secure, reliable, and maintainable.
The comprehensive analysis, continuous integration capabilities, actionable insights, and support for compliance make Sonar an indispensable tool for modern software development.
By leveraging Sonar, you not only enhance the quality of your code but also streamline your development process, leading to more efficient and effective software delivery.
SonarQube Server
SonarQube Server is a powerful, on-premise code quality and security management tool that provides comprehensive analysis to ensure high standards in code generated by LLMs.
It performs static analysis on the entire codebase to identify issues related to quality, security, reliability, and maintainability.
By integrating SonarQube Server into CI/CD pipelines, organizations can automate continuous code analysis, gaining actionable insights and detailed reports that help maintain compliance with coding standards and industry regulations.
This leads to robust, secure, and maintainable code that meets organizational requirements.
SonarQube Cloud
SonarQube Cloud offers the same robust code quality and security analysis of SonarQube Server with the added benefits of cloud scalability and accessibility.
It seamlessly integrates with popular cloud-based CI/CD platforms, enabling continuous analysis and feedback.
SonarQube Cloud's intuitive interface and real-time insights help development teams quickly identify and resolve issues, ensuring that the code generated by LLMs is always of the highest quality and security.
Its ability to manage multiple projects in the cloud makes it an ideal solution for organizations with distributed teams and diverse project needs.
SonarQube for IDE
SonarQube for IDE is an IDE plugin that works alongside the developer writing code to provide instant feedback on the quality and security of code.
By offering real-time analysis and suggestions as developers write code, SonarQube for IDE helps prevent issues from being introduced in the first place.
This immediate feedback loop ensures that the code generated by LLMs adheres to best practices for quality, security, and maintainability from the very beginning of the development process.
SonarQube for IDE's seamless integration with SonarQube Server and SonarQube Cloud further ensures consistency and alignment across all stages of development.