
코딩 모델에 신뢰성 구축
훈련 데이터에서 체계적인 결함을 사전에 제거하여 설계 단계부터 안전한 기초 모델을 훈련합니다.
대규모 언어 모델(LLM)은 강력하지만, 훈련 데이터의 결함을 그대로 물려받습니다. SonarSweep은 모델 사전 훈련 및 사후 훈련에 사용되는 코딩 데이터셋을 수정, 보안 강화 및 최적화하도록 설계된 서비스입니다.

AI가 생성한 코드의 품질은 LLM이 훈련된 데이터의 품질과 직결됩니다. 연구에 따르면, 소량의 저품질 데이터조차도 모델에 불균형적으로 “악영향”을 주어 버그가 많고 보안이 취약한 코드를 생성하게 할 수 있습니다.
대부분의 LLM의 기반이 되는 방대한 공개 데이터셋은 양질의 코드와 버그 및 보안 취약점으로 가득 찬 코드 조각이 뒤섞인 혼란스러운 집합체입니다.
훈련 과정에서 LLM은 이러한 결함 있는 패턴을 내면화하여 양질의 코드와 불량 코드를 구분하지 못하게 됩니다. 모델은 학습한 것과 동일한 실수를 반복하도록 학습합니다.
결과적으로 LLM은 코드를 생성할 때 버그와 취약점을 재현하게 되며, 이는 제품으로 유입될 수 있어 철저한 검증이 필요합니다.
생성형 AI는 코딩 방식을 혁신하고 있지만, LLM에는 치명적인 한계가 있습니다. 바로 숨겨진 버그, 보안 결함, 유지보수 부채가 포함된 코드를 생성하는 경우가 많다는 점입니다. 더 높은 품질 기준을 요구하는 LLM 제공업체와 기업에게는 모델을 미세 조정하고 맞춤화할 필요가 분명합니다. SonarSweep은 다음을 위해 필수적인 데이터 품질 계층을 제공합니다:

소스 단계에서 훈련 데이터를 개선하여 설계 단계부터 안전하고 신뢰할 수 있는 모델을 구축함으로써, 고객에게 시장에서 경쟁 우위를 제공합니다.

비공개 환경에서 자신 있게 맞춤형 모델을 개발하여, 고객이 엄격한 규정 준수 요건을 충족하고 민감한 지적 재산을 보호할 수 있도록 지원합니다.
Databricks 및 IBM과 같은 플랫폼에서 특화된 에이전트형 워크플로우를 위한 고성능의 비용 효율적인 소형 언어 모델(SLM)을 생성합니다.

훈련 데이터셋을 최적화하여 적은 데이터와 컴퓨팅 자원으로 더 강력한 모델을 구축함으로써, 제한된 예산 내에서 최첨단 성능을 달성합니다.


SonarSweep은 훈련 데이터셋 내의 수천 가지 버그, 취약점 및 코드 품질 문제를 대규모로 자동 분석하고 수정합니다.

엄격한 필터링 과정을 통해 저품질 코드를 제거합니다. 이후 정제된 데이터셋의 균형을 조정하여, 모델의 견고한 성능을 위해 다양하고 대표적인 학습 환경을 보장합니다.

최종 “정제된” 데이터셋은 모델 훈련에 바로 사용할 수 있는 최적화된 고품질 자산으로, 생성된 코드의 품질을 획기적으로 향상시킵니다.
훈련 데이터에서 체계적인 결함을 사전에 제거하여 설계 단계부터 안전한 기초 모델을 훈련합니다.
SonarSweep은 Sonar의 업계 선도적인 코드 분석 엔진을 활용하여 대량의 훈련 코드를 자동으로 처리하고, 문제를 수정하며, 결함이 있는 데이터를 고품질의 훈련 예제로 변환합니다.

코드를 삭제하는 대신 수정함으로써, 모델에 유용한 학습 예제를 보존하여 복잡한 패턴에 대한 모델의 이해도를 높입니다.

당사의 엔진은 잘못된 예제를 올바른 예제로 전환하여 전체 데이터 세트의 전반적인 품질과 보안 수준을 체계적으로 향상시킵니다.

전 세계 700억 줄의 코드를 보호하기 위해 700만 명 이상의 개발자가 신뢰하는 동일한 분석 기술을 기반으로 합니다.
SonarSweep이 이제 얼리 액세스(Early Access)로 제공됩니다. Sonar와 협력하여 안전하고 신뢰할 수 있으며 보안이 강화된 차세대 코딩 모델을 가장 먼저 구축해 보세요.
4.6 / 5
SonarSweep is a product from Sonar that remediates, secures, and optimizes coding datasets used to train AI language models. It is designed for AI companies and model builders — not for software development teams managing their own codebases.
Coding LLMs are typically trained on large volumes of publicly available open-source code, which frequently contains bugs, security vulnerabilities, and poor patterns. Models learn from these flawed examples and reproduce — and in many cases amplify — those flaws in the code they generate. SonarSweep addresses this at the root by cleaning and improving the training data before it is used to train or fine-tune a model.
SonarSweep shares its underlying code analysis engines with SonarQube and SonarQube Cloud, but it is a completely separate service and does not integrate with either product. It is not an add-on, extension, or feature of any SonarQube edition.
Where SonarQube and SonarQube Cloud help development teams detect quality and security issues in their own application code during development and CI/CD, SonarSweep processes large code datasets that AI companies use to train models. The relationship is a shared technological foundation — Sonar's analysis engines — applied to an entirely different use case and a different customer.
Coding LLMs are pre-trained on raw public open-source code — code that's full of bugs, vulnerabilities, and poor patterns. Models don't just absorb these flaws; they amplify them in everything they generate. SonarSweep fixes this at the source by cleaning training data before a model ever sees it.
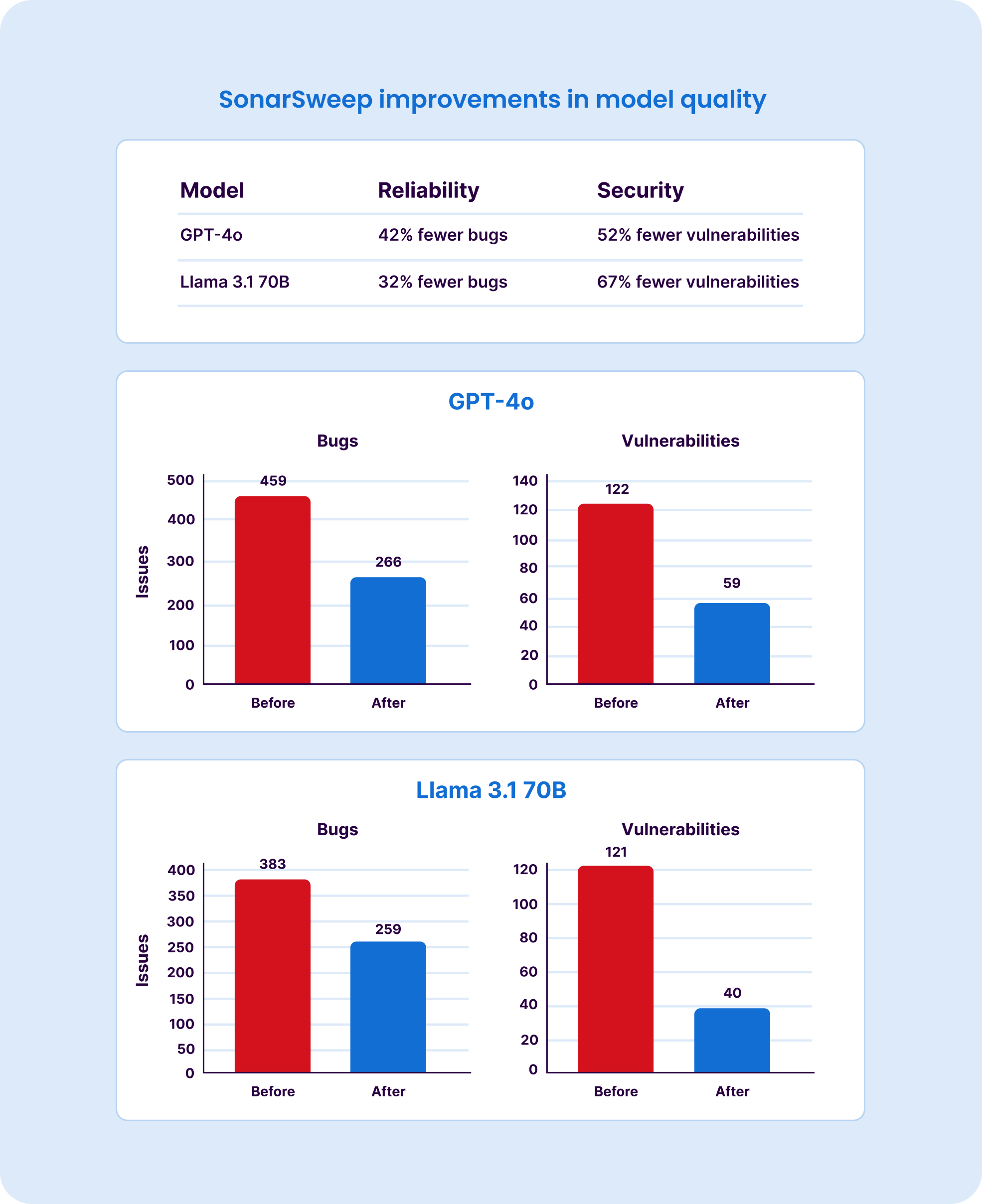
It reduces security vulnerabilities in model output by up to 67% and cuts bugs by up to 42%. It also handles a subtler problem: naively removing flawed code can skew language distribution in a dataset, so SonarSweep rebalances after cleaning to preserve model proficiency across all languages. And by addressing quality upfront, it eliminates the need for costly post-training correction passes.
SonarQube for IDE (formerly SonarLint) is a developer productivity tool that runs inside editors like VS Code, IntelliJ, and Eclipse, giving individual developers real-time feedback on quality and security issues as they write code. It operates at the developer level, in the IDE, during active development.
SonarSweep is not a developer tool at all. It is a data processing service for AI companies that are training or fine-tuning coding LLMs. It does not run in an IDE, does not provide feedback to developers, and is not part of a development workflow.
Yes — this is the core purpose of SonarSweep. The quality of code a language model generates is directly shaped by the quality of the data it trained on. A model that learned from code full of vulnerabilities and bugs will reproduce those patterns at scale. SonarSweep intervenes at the data stage, before training, to raise the quality floor of what the model learns from.
Models trained on SonarSweep-prepared datasets have demonstrated up to 67% fewer security vulnerabilities and up to 42% fewer bugs in their generated code compared to models trained on unswept data — with no degradation in functional performance. This was validated on the GPT-OSS-20B model.
SonarSweep supports 35+ programming languages, drawing on the full breadth of Sonar's code analysis engines — the same engines that power SonarQube and SonarQube Cloud.
In the context of LLM training data, this means SonarSweep can analyze, filter, and remediate code across all the languages that typically appear in large public code datasets: common back-end languages, front-end languages, scripting languages, systems languages, and more. Across these languages, it can identify and automatically fix over 6,700 distinct types of quality and security issues.
SonarSweep doesn't produce code changes for developers to review in pull requests. It processes and delivers cleaned training datasets to AI companies. Governance in this context sits with the AI team — validating dataset quality and model output before using the swept data in a training run.
No. SonarSweep has no connection to any SonarQube edition. It is a separate product for companies building or fine-tuning coding LLMs — not a feature unlocked through any SonarQube subscription tier.
The ROI is for AI companies, not development teams. Models trained on SonarSweep-processed data produce up to 67% fewer security vulnerabilities and up to 42% fewer bugs — with no loss in functional performance. It also reduces training cost by addressing data quality upfront, eliminating expensive post-training correction cycles.