

*Co-authored with Csaba Feher
In 2024, the Sonar engineering team worked on a several-month project to remove a performance bottleneck and transform our Processor service. The goal was to make it scalable, resilient, and cost effective while improving the user experience. This post details how we cut the file storage cost on SonarQube Cloud by 90 percent while extracting 3.4 TB of data from a relational database to a more suitable storage option.
Read on to learn more about our approach, how we looked at the problem, the techniques we used to validate our assumptions before delivering the change and the final solution.
Starting with “why”
SonarQube Cloud contains a component called the Processor service that is responsible for saving files into a relational database table running on PostgreSQL. This table stores two types of data: the content of the files in binary format and metadata associated with each file (like a hash of the content).
This table has an intense writing activity. Each time a row is updated or deleted, the previous version of the row is flagged as ready for physical deletion by the Postgres engine. Those lines are then purged by an automatic job, which sometimes causes the table to be locked and the platform to halt. By November 2024, we had reached the limits of storing files in a relational database—to avoid high maintenance costs of the current solution, we needed to reconsider the storage. Keeping the maintenance costs under control is vital to keep our budget available for innovation and improvements of our products, while preventing service disruptions or performance degradation.
Finding the right storage option
One of the lengthier operations performed by the Processor is saving and updating files, which put a heavy burden on the service. The speed of task processing is crucial for the user experience—the quicker it's executed, the quicker we can deliver results to the user. Changing the file storage solution is an opportunity to accelerate the process.
The File table contains around 3.4 TB of data and is constantly growing. Today, it comprises around 480 million rows, each representing a file and its metadata.
A new storage option had to be flexible, as various services will consume the data with different requirements. It needed to be fast and be scalable to accommodate the platform’s significant growth. Last but not least, it needed to be cost-efficient.
Finding the best possible storage service for our use case was the first step in defining the new solution. To begin, we knew we needed to answer two critical questions:
- How should we store the files to ensure cost efficiency and appropriate access speed?
- How can we ensure the service performs effectively within a reasonable timeframe, providing a good user experience and preventing users from waiting too long for their files?
The proof of concept
After an initial evaluation of options on the market, we determined our two best candidates were Amazon Simple Storage Service (Amazon S3) and Amazon Elastic File System (AWS EFS). As per our research, both of them satisfy the security requirements while offering scalable, durable, and fast file storage capabilities.
To choose the target solution, we need to ensure the performance of the service is satisfying our needs. We also want to compare S3 and EFS, and make sure the solution is cost effective.
Finally, we want to validate the access patterns for the metadata storage to make sure it suits the needs of the service.
To answer those questions, we put in place a proof of concept. We implemented it in the Processor to iterate faster and gather initial data. This strategy was faster than implementing a separate service. We also benefited from the existing monitoring of the service health and performance.
Here are the learnings of the first round of experimentation in a testing environment:
- Writing the files on Amazon S3 using the synchronous client is forty times slower than saving them on the database. This performance is not acceptable.
- By employing the Amazon S3 asynchronous client instead of the synchronous one, uploads can be processed in the background concurrently with other tasks. The overall duration is twice as long as saving the files in the database, which is within the acceptable margin.
- Amazon EFS is three times slower than the database, which is also within the acceptable range. It is also trickier to set up, since you have to mount the file system on each client service which is less convenient than the S3 API.
- Amazon DynamoDB performance is as fast as expected, even if the environment is neither warmed up nor loaded with data similar to production.
Those first results validated the approach but failed to exclude a candidate for the file storage. It was time to face reality, get data from actual production, and check how each option behaved under load.
The experiment
We refined the proof of concept to make it temporarily production-ready by implementing more tests, enhancing robustness, improving monitoring precision, and, most importantly, adding safeguards to ensure that our experiment wouldn't negatively impact the user experience if we encountered any issues.
To ensure our experiment wouldn't have any impact on our users, at first, the new storages were turned off and we used a feature flag to gradually increase the number of processing tasks using them.
We started at 1 percent and increased to 10 percent after one day, then 50 percent after one more day since the measures were good. Finally, we ran the experiment at 50 percent for a little over a day and stopped it as we gathered enough data. We processed 1 million tasks during this experiment, with 500,000 tasks utilizing the new feature.
What did we learn by doing this?
- Amazon S3 is the fastest option with the asynchronous client, but saving each file individually is costly due to the high number of requests, which significantly impacts Amazon S3's pricing.
- Amazon EFS also demonstrated fast performance and is more cost effective than S3.
- Throughout the experiment, we encountered zero errors.
- We have a comfortable margin of one minute on average between the end of the file-saving process and the end of the Processor. During the experiment, less than fifty Processor tasks (over half a million) had to wait for the file-saving process to complete.
Regarding cost, obtaining accurate numbers from production helped us refine our simulation. It validated that the Amazon DynamoDB estimates were reasonably accurate.
On the file storage side, we saved an average of twenty-four files per task, which leads to slightly more than 12 million files saved during the experiment. Amazon EFS was half the price of Amazon S3 for our use case.
Amazon S3 is our preferred option for several technical reasons:
- It is a fully-managed service, therefore more flexible for future use cases to consume data from other services,
- more scalable, and
- offers a better price evolution when our platform grows.
Since cost efficiency is an important part of running a sustainable cloud platform, we had to evaluate options to make the Amazon S3 bill for our use case more competitive. Our use cases are compatible with bundling several files in one archive. Saving the files in bundles of twenty files would reduce the cost of S3 to only 10 percent of the EFS cost.
From being twice the price to just 10 percent of the price...We have a winner!
Running this experiment helped us feel confident about choosing a solution without making assumptions about our most important criteria: user experience (hence service performance) and cost.
Going further
While exploring the chosen storage type, we realized the change could significantly alter our architecture. Replacing the storage solution might necessitate batching or impact performance. We initially set out to select one technology over another, but this is not the end of our journey. To fully leverage the new storage’s potential, we needed to step back and challenge the current design.
Let’s examine how the module looked before the change to understand how the architecture was impacted. A processing unit handles incoming requests and all their data sequentially, saving their content to the database. The requests contain several different pieces of information including the files themselves and their metadata.
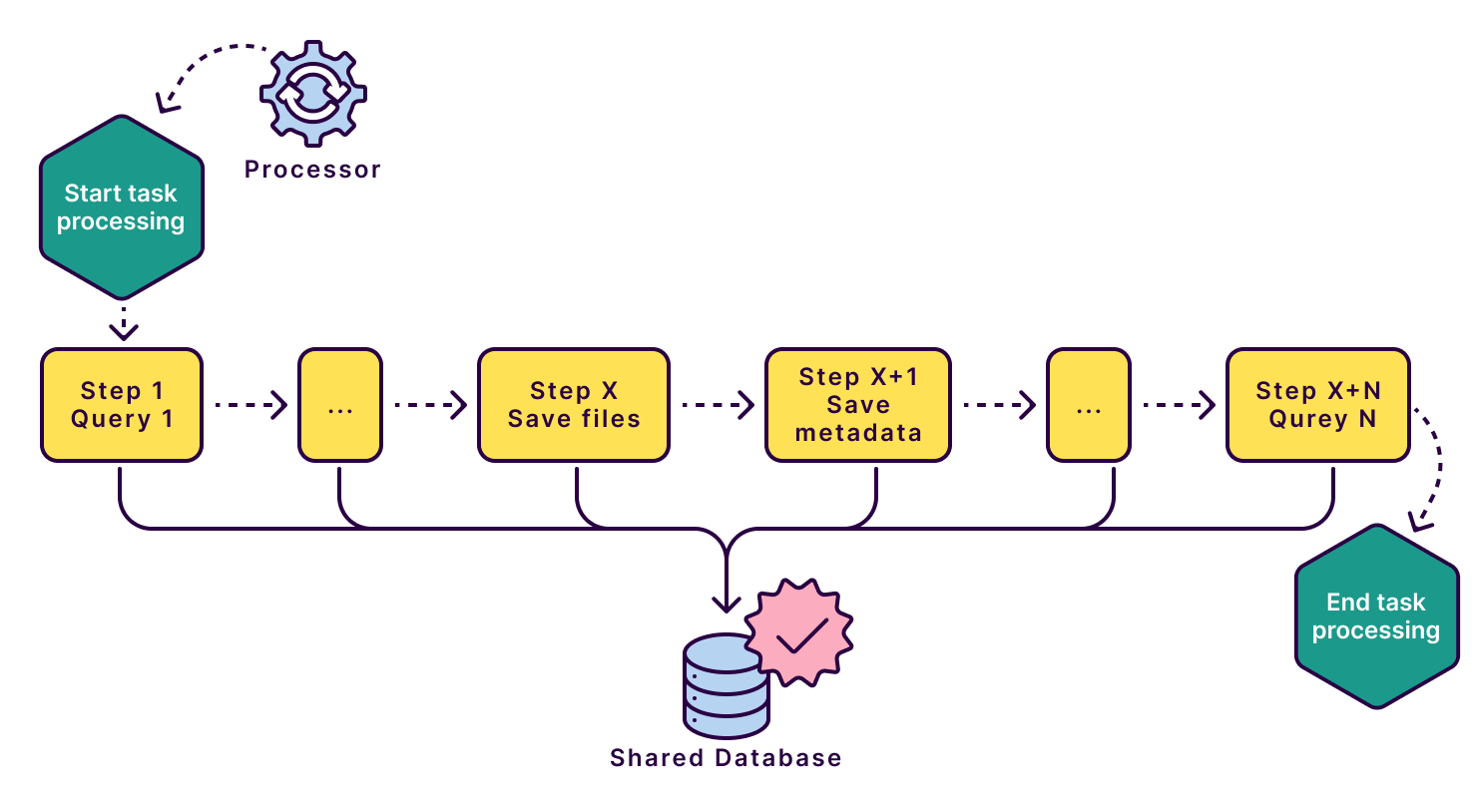
If we continue with the sequential processing approach, introducing a data storage module with different read-write performance could profoundly impact the duration of the task processing. Performance is one of our top priorities, and we cannot afford to compromise on the Processor service’s runtime.
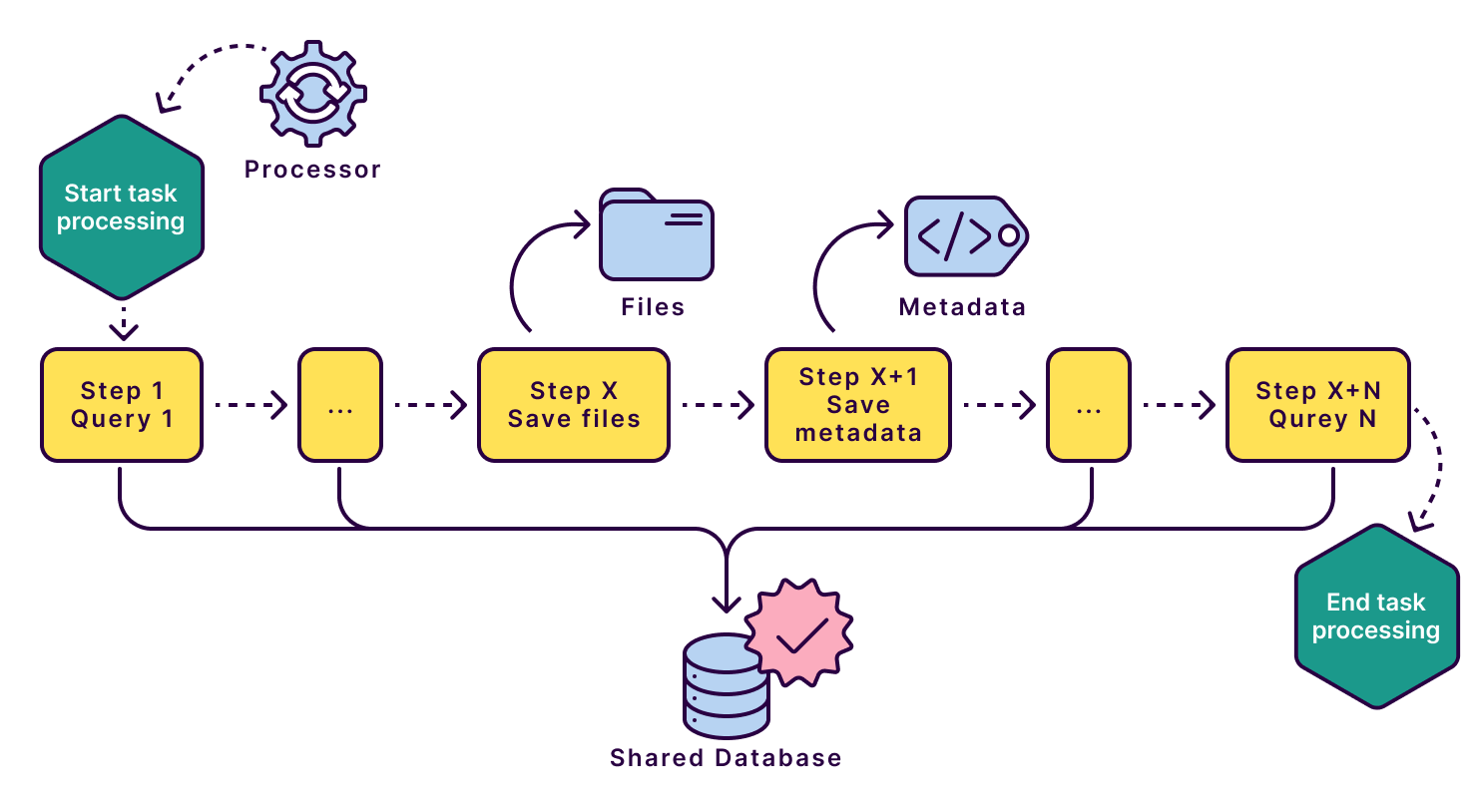
The original monolithic architecture of this service limited SonarQube Cloud's ability to become a global service, scale, and serve clients in multiple countries and regions. It enabled us to grow, and now we face limitations on vertical scalability, meaning we can’t scale the system by simply upgrading the hardware under our services. SonarQube Cloud needs to be decomposed into smaller microservices to overcome these limitations. At the same time as this transformation, we also leveraged the benefits of a distributed architecture. It was easier to slice the architecture and have clear ownership and team autonomy for each subsystem than on a monolithic design.
We can extract the file handling from the main processing flow to enable parallel execution; this also opens the door to moving all the logic related to the files out of the monolithic system. This new architecture not only overcomes the limitations of the original monolithic design but also offers scalability and flexibility. Creating an event-driven architecture for processing requests allowed efficient handling of large volumes of data. The REST API designed to access the data provides a simple and consistent way to interact with the system.
During our discovery, we could separate the data necessary only for the Processor from the data related to the “file” resource. Keeping the data local to the microservice is essential to enable efficient communication and respect boundaries. We created a Processor metadata storage, which holds part of the data that used to be bundled with files in the monolith.
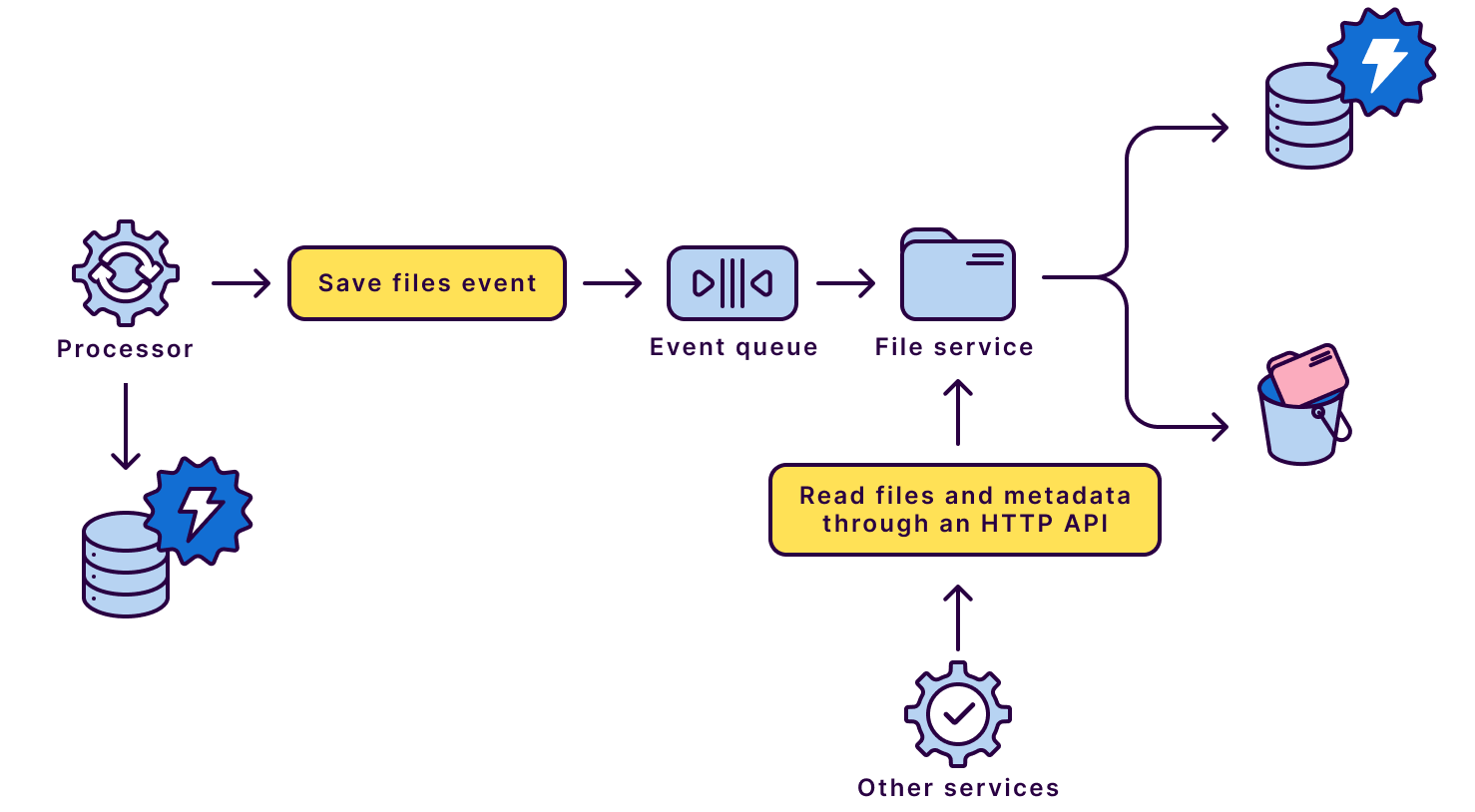
This design offers several advantages. By ensuring files are ready only after the Processor completes its data handling, we can relax performance requirements from milliseconds to seconds. Furthermore, we can consolidate duplicated code and centralize distributed logic, leading to improved maintainability and easier management of future changes. The asynchronous nature of this approach also provides better control over scaling, while the REST API enables versioning of any system modifications and establishes a clear contract for interacting with the file domain.
The results
In conclusion, the architectural changes we implemented reduced users' perceived task duration by 10 percent. By lowering the wait time for results, users can benefit from SonarQube Cloud analysis sooner. Consequently, this leads to a quicker feedback cycle and promotes the development of well-structured, maintainable code.
Through experimentation and analysis, we determined that using Amazon S3 with bundled files offers the best balance of performance and cost for our file storage needs, for 10 percent of the cost of Amazon EFS. This experiment emphasized the importance of testing and collecting data from production environments to make well-informed decisions.
In the long run, these improvements eliminated a significant performance and scalability bottleneck for SonarQube Cloud. By enhancing the platform's scalability and resilience, we are ensuring its capacity for future growth, maintaining a positive user experience under increasing workloads, and supporting the addition of new high-value features. This also prepares the ground for future improvements on SonarQube Server.
Find out how you can drive efficiencies with Sonar. Check out our Developer Guides.