

TL;DR overview
- Shifting right for secure platforms means extending security testing into runtime and production monitoring—not replacing shift-left practices but complementing them with observability that detects vulnerabilities and anomalies that only surface under real workloads.
- Shift-right security includes techniques like production security scanning, chaos engineering for security, canary deployments with security monitoring, and runtime application self-protection that enforce security policies in live environments.
- The most resilient DevOps security postures combine shift-left (catching issues at code time with SonarQube) with shift-right (detecting behavioral anomalies in production), reducing both the likelihood and impact of security incidents.
- Engineering teams adopting DevSecOps should treat shift-right not as a substitute for code-level security but as a final safety net that catches residual risks that static analysis cannot detect in advance.
I still remember in the early days of my software engineering career, working with the systems administrators to set up Subversion commit hooks to automatically reject commits that didn’t pass tests. Heck, I even wrote a tool that would convert spaces to tabs on commit, and back to spaces on check out, based on the preferences of the individual developer. As a recovering people-pleaser, I can admit that was probably overkill. (Oh, I might be showing my age; Subversion is what we used back before Git was a thing.)
But what was real overkill, was that the tests which ran on the code repository server took a few minutes, which would cause the commit process to hang until they were finished. I drank a lot of coffee on heavy-commit days!
I was trying to catch failures for tests that the developers didn’t run. And because these commit hooks had to be completed before you could carry on coding, the delays incurred were more frustrating than the inconvenience of having to wait to find out when staging environment builds failed.
Roll on 20 years, and we’re still trying to solve the same issues, albeit with much more success than in the early 2000s. We’re testing right in our development environments, and even have the ability to let a remote stakeholder look at the application running on our machine before even committing changes to the code repository.
We’ve been shifting left for decades. In fact, you might be surprised that “shift left” as a term was actually coined in 2001 when Larry Smith introduced the idea of testing early in the development lifecycle.
I'd like to propose the idea that, while we’ve been shifting left in the software development lifecycle for decades, developer tooling has more recently expanded its focus to include the righthand side of the software deployment lifecycle.
Defining “Shift Left”
In essence, “shift left” is a practice that aims to identify and fix defects as early as possible in the development process. This can be done by shifting testing, security, and other quality assurance activities earlier in the process. Shifting left lets you identify and fix defects early, leading to:
- Reduced costs
- Improved software quality
- Increased speed of software development
- Reduced risks of software failures
How can Code Quality help?
If you’re a frequent reader of the Sonar blog, you’ll probably know that we’re huge proponents of writing Code Quality. We don’t do this just to measure code quality as a way to increase maintainability and readability of the code for the future; we also love detecting bugs, code smells, and vulnerabilities before they get into production. This is the ultimate in shift-left approaches, but it’s not just about the code we write, it’s about what happens to that code next.
The Way We Deploy
What’s interesting today, compared to 20 years ago, is the way we deploy our code, from staging to production. I remember asking our systems administrator to provision a new virtual host on one of our Apache-based web servers. Sometimes, I’d even ask her for a whole new server! (And sometimes I’d do it myself on a server hiding under my desk. Hey, WWW stood for Wild West Web back then!)
And when it came to software deployment, continuous integration meant using WinFTP to transfer the files across manually. Having a server perform an `svn pull`, or even pull files automatically via FTP, was considered bleeding edge!
Of course, nowadays, we have little idea of what goes on under the hood. When I push code to a GitLab repository, and my Continuous Integration and Continuous Deployment (CI/CD) pipeline starts a new deployment process into a new virtual machine, I’d like to believe it’s completely autonomous and automated, but I have no idea if it’s actually kicked off by a caffeine-powered human somewhere in the world. It’s possible that I owe someone a lot of coffees.
But in all seriousness, in order to deploy autonomously and consistently, we’re using Infrastructure as Code (IaC) nowadays, from Kubernetes templates to Docker configuration. These can also be tested, reviewed, secured, and because they are considered code, can even be tested for “Code Quality”.
Testing the Code of Infrastructure
If we can define our infrastructure as code, we can test it. Perhaps not quite in the same way as we would test an NPM module or C++ class, but we can test it for cleanliness. By testing this type of code, we can also detect bugs and vulnerabilities in the resulting software.
While this can be done during the coding phase of the development lifecycle, the benefit still firmly sits on the righthand side. Compare this to testing, for example, which is both performed earlier in the process, and also benefits the earlier stages of the process, CI/CD code checking can be performed earlier, but doesn’t benefit us until later.
This is the “shift right” aspect to which I’m alluding in this article. While we’ve benefitted from “shift left” for quite some time now, we’re also seeing the tools we use broadening their focus to include the right side of the deployment lifecycle. That is, we’re still performing the development and testing up-front, but we’re also seeing IDE plugins like SonarQube for IDE, and CI/CD pipeline tools like SonarQube Server and SonarQube Cloud help identify issues that won’t actually manifest until the software is deployed in staging or production.
Let’s have a look at two examples of such issues that wouldn’t have a big impact during the local development process: secrets detection and platform configuration.
Secrets Detection
Secrets are typically pieces of confidential data that should be kept secure, such as API keys, passwords, cryptographic keys, access tokens, and other credentials.
The primary goals of secrets detection in the testing phase are:
- To prevent sensitive information from being inadvertently exposed or leaked, which could lead to security breaches or unauthorized access to systems and data.
- To ensure that software applications comply with security best practices and regulatory requirements, such as the General Data Protection Regulation (GDPR) or the Payment Card Industry Data Security Standard (PCI DSS).
- To reduce the risk associated with secrets exposure, which can have significant financial and reputational consequences for organizations.
It’s common sense that you should never store secrets in your code, even temporarily in your local development environment, as the likelihood of us forgetting and committing to a code repository are high. That said, it still happens from time to time, and that’s where issues can quickly bubble up to production, or even into third-party tools that are involved in the CI/CD pipeline.
SonarQube for IDE can help identify these situations while you’re coding, whether they’re application-specific secrets, or access keys for authorizing the application to a third party. Take the following screenshot for example, in which AWS access keys and secrets could have been inadvertently committed and propagated to many other systems. Detecting these while you’re coding is an invaluable tool to protect against future security concerns.
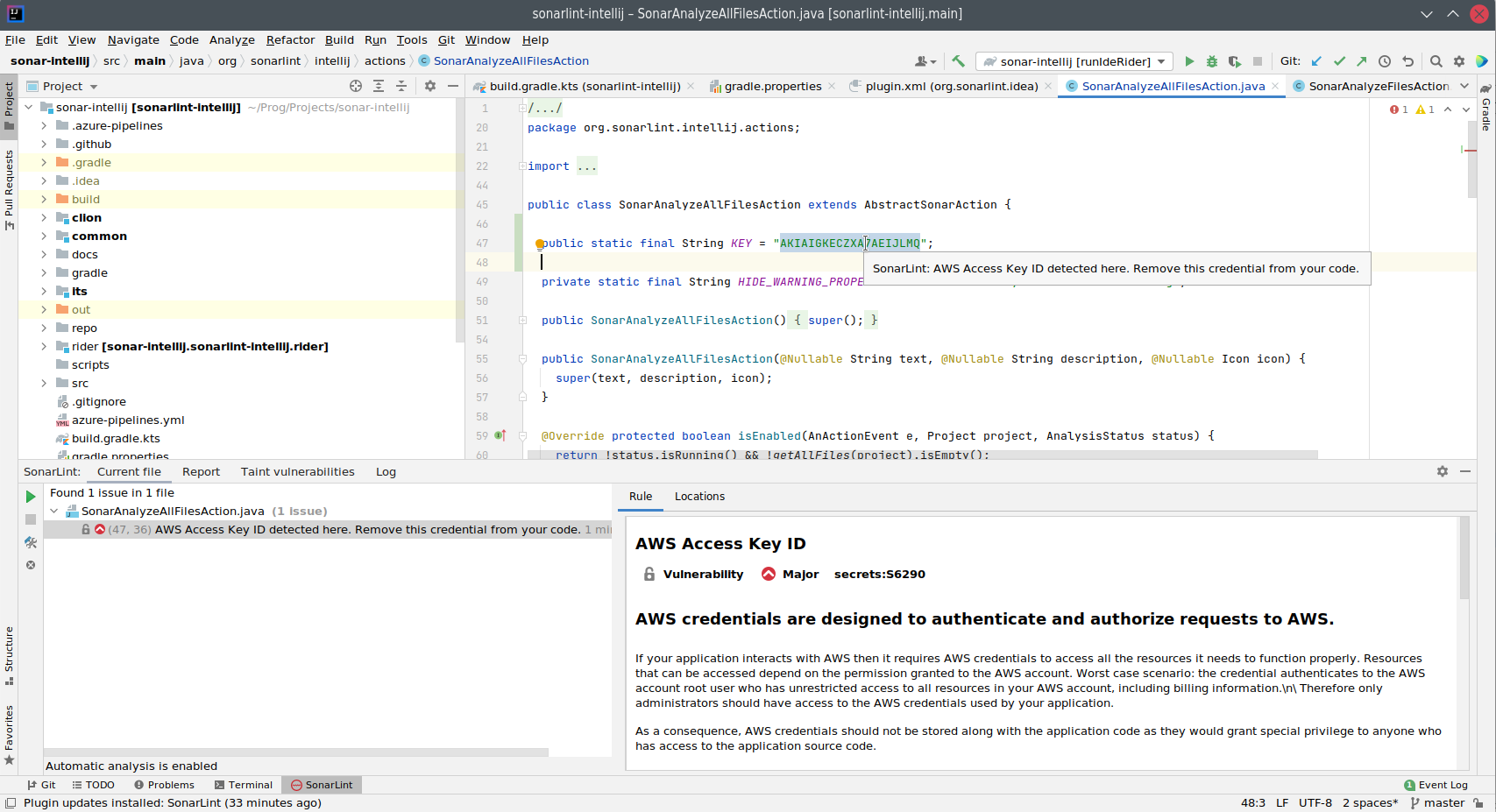
Platform Configuration Issues and Security Code Smells
When building a house, you might choose to install the most advanced security systems, fortified doors, and unbreakable windows. But if your foundations aren’t solid, stable, and built on reliable ground, the entire structure is vulnerable to collapse, rendering all those security measures futile.
And so it is that, whether you’re deploying to AWS, Azure, or Google platforms, the security of your platform is paramount to the security of your application.
When configuring the platform on which your application is going to reside, it can often be tempting to simplify the security aspects in order to speed up the development process. But, all too often, such shortcuts in the beginning can be overlooked when pushing the application to QA and production.
In other cases your production ready configuration might inadvertently contain a human-created error, or a recent change or newly discovered vulnerability is now activated and your previously safe configuration is now insecure.
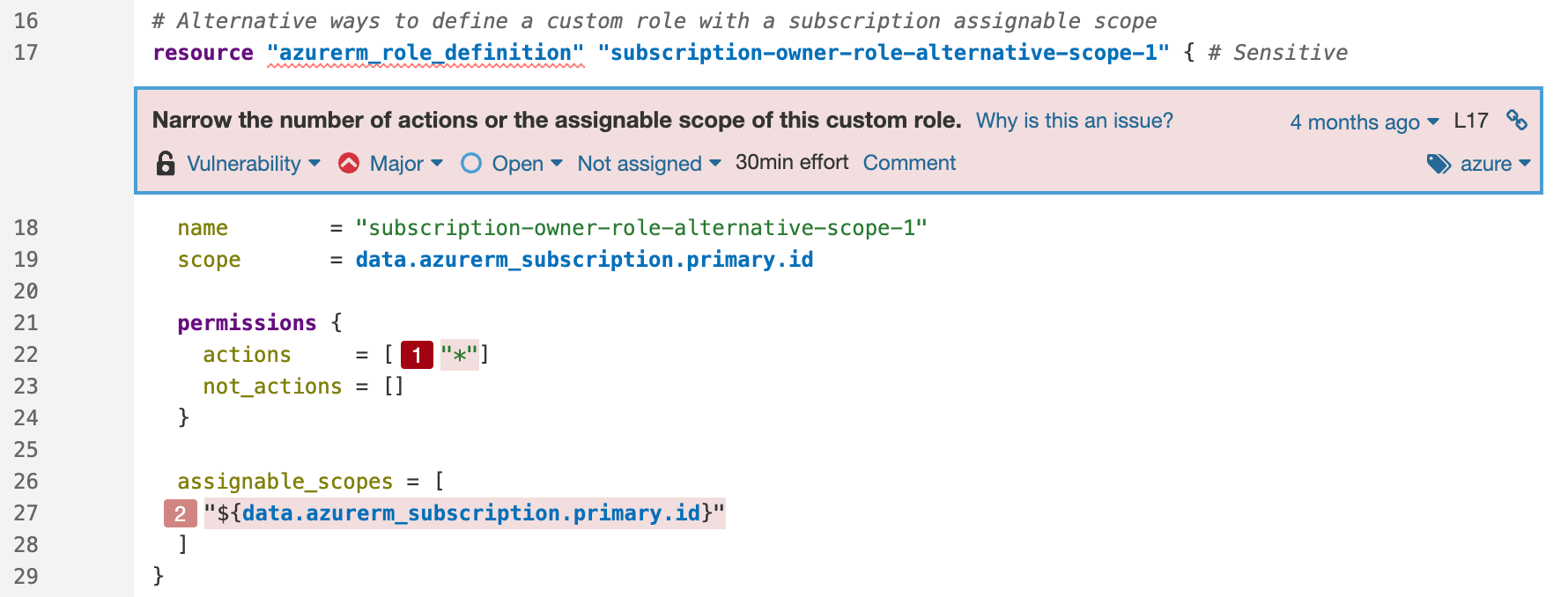
Take this example of a scope permission vulnerability in Azure with a secondary location:
Or this authentication vulnerability in AWS:
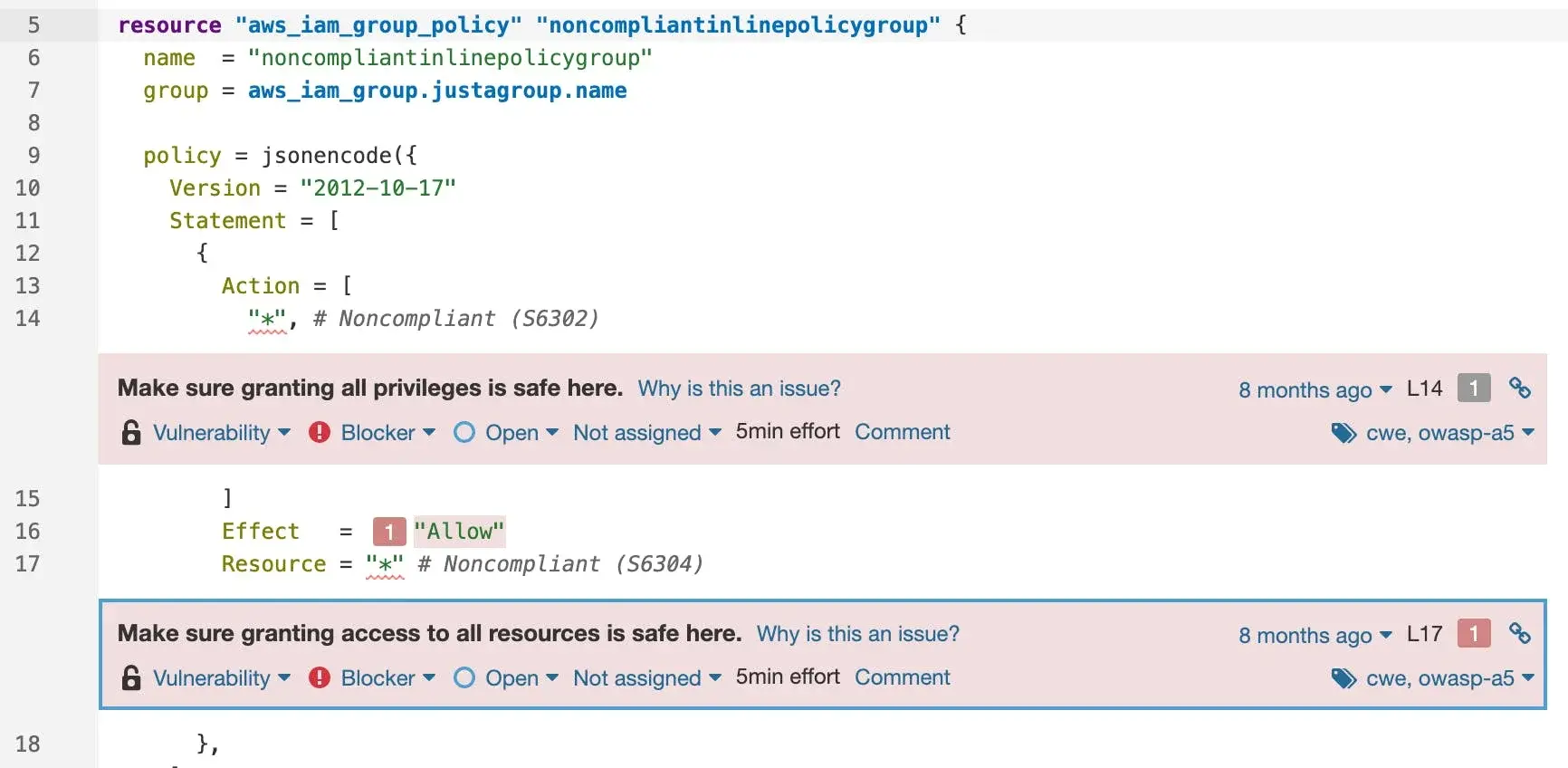
Discovering these as early as possible is what “shift left” is all about. That you’re protecting yourself against issues that won’t eventuate until later in the deployment lifecycle is what I’m referring to as “shift right”.
Why Not Try For Yourself?
Getting started is easy. Checkout our Documentation to see our supported languages for CloudFormation, Docker, Kubernetes, Terraform, and more. Or better yet, try them out yourself in SonarQube for IDE, SonarQube Server or SonarQube Cloud. Please visit our Community to give us feedback and to grab the latest product news.