

TL;DR overview
- Setting correct regex boundaries—using ^ and $ anchors—is a critical security requirement for input validation regexes: without proper anchoring, a regex may match a valid pattern anywhere in a malicious string rather than requiring the entire input to conform.
- A common mistake is enabling the MULTILINE flag without understanding that ^ and $ then match line boundaries instead of the full string, allowing bypass of single-line validation patterns.
- Unanchored or incorrectly anchored validation regexes allow bypass attacks where an attacker includes a valid-looking substring within a longer malicious payload, passing the regex check while delivering harmful content.
- SonarQube detects regex validation patterns missing proper anchoring as security hotspots, helping developers catch input validation bypasses in authentication, file type checking, and URL validation code.
We've been working recently on writing rules for detecting errors in regular expressions in Java code. Regular expressions are a common feature of modern programming languages, and it's easy to take them for granted. By their very nature they pack a lot of power into terse little packages and unfortunately that introduces a lot of room for error. In my last post I talked about the kinds of errors our newly implemented rule about character classes found in open source code. Today, I’ll talk about boundaries, another regex feature that can lead to bugs when used incorrectly, and a rule of ours that can help you avoid such issues. I’ll also talk about complexity and maintainability in regular expressions and our rule that can help you find regular expressions that are too complex.
Boundaries
Boundary markers such as ^ and $ allow you to anchor the regex pattern to the beginning and end of the line (or string depending on which flags you use) respectively. This means that when you want to match a literal ^ or $, you need to escape these special characters with a backslash.
And if you fail to escape ^ or $ then you may end up with a pattern that doesn't match anything at all. In order to detect such problems, we offer a rule (java:S5996 - Regex boundaries should not be used in a way that can never be matched) pointing out cases where a boundary is used in a way such that it can never produce a successful match. Here’s one example of this problem that we found while checking code on GitHub:
Pattern.compile("^[a-zA-Z][a-zA-Z0-9_.][@.](!#$%&*()-+=^){8,30}$")Another case where this rule applies is if you use an end-of-line/string boundary at the beginning or a beginning-of-line/string at the end. This could be a case of confusing the meaning of ^ and $ :
Pattern.compile(".*A^")Source (MongodbDocumentSerializerTest.java)
Complexity
Regular expressions are powerful and often terse. Unfortunately, that terseness often makes them hard to read and understand for your teammates, for readers of your code and even for your future self. Ultimately, they often become a maintainability nightmare. Consider for example the following regex for matching dates:
"^(?:(?:31(\\/|-|\\.)(?:0?[13578]|1[02]))\\1|(?:(?:29|30)(\\/|-|\\.)(?:0?[13-9]|1[0-2])\\2))(?:(?:1[6-9]|[2-9]\\d)?\\d{2})$|^(?:29(\\/|-|\\.)0?2\\3(?:(?:(?:1[6-9]|[2-9]\\d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:0?[1-9]|1\\d|2[0-8])(\\/|-|\\.)(?:(?:0?[1-9])|(?:1[0-2]))\\4(?:(?:1[6-9]|[2-9]\\d)?\\d{2})$"Can you tell what kinds of dates would be matched by this?
Would you easily be able to add additional types of dates to it or remove types?
Me neither.
Another example, one might say the example, of a complicated regex is one that is commonly used to match email addresses, which can be found here (and you’ll see lots of versions of it flying around on the internet). I won’t include it in this blog post for space reasons, but it’s more than 6,000(!) characters long. And perhaps the worst part is that we’ve been guilty of using this regex internally.
To us, reusing an overly complicated regex without understanding it sounds like a trap. Whether it works or not may depend on your situation, including which email addresses you want to consider valid and which invalid. For example if you wanted to write an email to yourself at your local mail server, the mail application shouldn't stop you from addressing the mail to `host@localhost` (a.k.a. Local Host), but when validating email addresses for a web form, you might want to restrict addresses to non-local domains. Now there probably aren’t many people who would be able to tell whether the "standard" email regex would accept `host@localhost` or not by just looking at the code. And certainly it would be a decidedly non-trivial engineering effort to change it to not accept an @localhost address if it does (or vice-versa).
To help you keep track of complicated regular expressions you’re using, SonarQube Server, SonarQube Cloud and SonarQube for IDE offer a dedicated rule for finding regular expressions with complexity that exceeds a configurable threshold: java:S5843 - Regular expressions should not be too complicated. This rule is inspired by the cognitive complexity concept, developed by SonarSource, and takes into account how all the regex operators, combined with each other, raise the complexity of a given regex. Here’s what it says about the date regex from above:
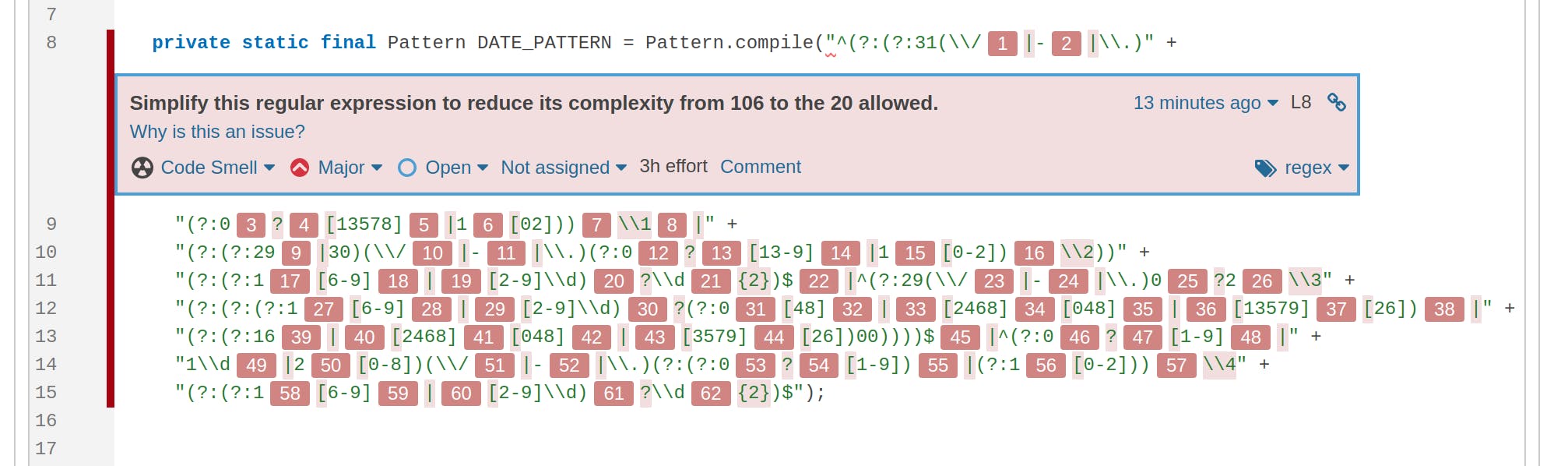
Now what makes this regex so complicated? The fact that it verifies that the date doesn’t just fit the general format of a date, but is a valid date to the point that it only allows the 29th of February if the year is a leap year. In this case it’d be preferable to use a simpler regex to only match the general format and then write a plain Java method to check that the numbers make sense and whether it’s a leap year. An even better solution would be to delegate that logic to a dedicated library, and use it from there.
When you find yourself in the process of writing (or reusing) such a complicated regex, you should first ask yourself whether you couldn’t easily solve the problem without using regular expressions at all. The next best option is using a combination of multiple simpler regular expressions applied in chain, one after another (such as first using one regex to split the input string and then using others to process each part of the string). If that’s not possible, try to split the regex into multiple parts and document each part or at least assign it to a variable with a meaningful name.
Then, once you’ve gotten your regular expression(s) down to a manageable size, the rules for specific features like character classes and boundary markers can help you make sure your pattern matches what you think it does.
At that point, with complexity and accuracy handled, you're nearly done. All that's left to worry about is stability - as in the stability of your application. That's right, a regex gone bad can bring down your application. So next time, I'll talk about the humble regex's potential for stack overflows, and what we've done to help you prevent it.
---
This is the second installment in a series on what can go wrong in writing Regular Expressions:
- Regular expressions present challenges even for not-so-regular developers
- Setting the right (regex) boundaries is important
- Crafting regexes to avoid stack overflows
Something to add? Join us in the community!