

AI-generated code continues to be a hot topic of discussion among programmers. There are enthusiastic proponents and thoughtful objectors to this practice, and both sides have compelling arguments. The debate over AI in coding isn't about whether it's inherently good or bad; its value will be determined by how we use it as it continues to evolve.
To effectively leverage the power of AI tools – or even to critically evaluate them – we must understand their underlying mechanisms. This understanding becomes even more vital as AI development rapidly progresses, particularly in the realm of machine learning. Therefore, before diving into the practicalities of AI-assisted development, it's essential to grasp the foundations upon which these tools are built.
This post will discuss machine learning (ML) in Python, examining the unique considerations for application developers as AI's role in everyday software continues to expand.
Approaching ML from an application developer’s perspective
While prompting a large language model (LLM) isn't the same thing as training a deep neural network, it introduces the need for application developers to understand ML in order to successfully integrate it. Developers are now increasingly expected to not only consume and integrate AI models but also to understand their capabilities, limitations, and how they were trained to use them effectively.
Conversely, ML engineers, who once focused primarily on experimental model development in notebooks, are now facing the critical need to produce production-ready code. This means their work, once isolated, must now be robust, readable, reproducible, and easily integrated into larger applications – a domain traditionally owned by application developers. This increased expectation for deployment-ready solutions is leading to a fascinating convergence where both roles benefit from a deeper understanding of the other's discipline. This shift is reflected in the rise of Machine Learning Operations (MLOps), a set of practices that combines machine learning, DevOps, and data engineering to reliably and efficiently deploy and maintain ML models in production. MLOps emphasizes automation, continuous integration/delivery, monitoring, and governance throughout the entire ML lifecycle, bridging the gap between experimental model development and robust application integration.
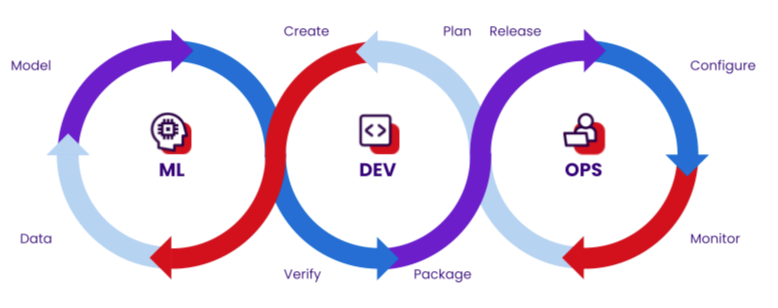
[Caption: MLOps as the reunion of ML, application development, and operations working together]
ML focuses on developing algorithms that allow systems to learn from data and make predictions or decisions without explicit programming. Python has emerged as the language of choice for much of this work, and one of its greatest strengths in this domain is its remarkable flexibility. It is a language that offers a vast ecosystem of libraries and frameworks that cater to data preprocessing, model training, deployment, and academic tools. Understanding where these diverse approaches and tools diverge, and how they contribute to the broader ML landscape, is key to leveraging Python effectively for machine learning engineering.
Whether or not machine learning ends up gathering dust on the shelf, just like other hyped tech, ML and AI are not going away. This means that human oversight will probably continue to be necessary, and a commitment to code quality and code security will be paramount. Understanding the fundamentals of ML is key to this oversight and effective integration.
What exactly is machine learning?
At a very high level, machine learning (ML) is a subset of artificial intelligence (AI) that empowers systems to learn from data without explicit instructions. At its core, ML relies heavily on the quality and quantity of data it consumes. This data acts as the training ground for deeply complex algorithms that – unlike fixed logic flows we often see in application development – can identify patterns, make predictions, and adapt their behavior over time. In traditional application development, prior knowledge of how to solve the problem is required; ML engineering focuses on building models that can learn and generalize from data to figure out how to solve the problem on its own without the need of prior knowledge.
How is ML being used in Python app development?
ML models are trained on datasets where they learn relationships and patterns. Once trained, they apply these learned patterns to new data to make predictions or classifications. The primary goal of ML is to extrapolate learnings from existing data to perform specific tasks. These tasks typically involve:
- Classification: Categorizing data, for example, spam detection, and image recognition
- Regression: Predicting numerical values like house prices and stock market forecasts
- Clustering: Grouping similar data points, such as customer segmentation
- Anomaly detection: Identifying unusual patterns, which can be helpful in fraud detection
How does ML compare to traditional Python application development?
In traditional Python application development, while data is certainly involved, its role is not the primary driver for learning and decision-making. The core focus is on building functional software applications – frequently user-facing – designed to perform a wide array of explicit tasks:
- API development: Building interfaces for software to communicate, for instance, RESTful services and GraphQL endpoints
- Web development: Creating interactive websites and web applications, such as e-commerce platforms and content management systems
- Automation: Scripting repetitive tasks, like data scraping and system administration.
- Data processing: Transforming and managing data, for example, ETL (Extract, Transform, Load) pipelines and database interactions
- Desktop applications: Developing graphical user interfaces (GUIs), for instance, utility tools and custom business software
Ultimately, the goal in traditional Python application development is to deliver a robust, maintainable, scalable, and user-friendly product that consistently meets predefined business requirements. The application's underlying operational logic is typically explicit, rule-based, and directly programmed by developers.
For example, when it comes to something like a banking app, you absolutely want it to do the exact same thing every time you log in. Because traditional applications operate on explicit, unchanging logic. Unexpected behaviors – like your balance suddenly dropping to zero for no reason – are a sign of a critical flaw. An application developer builds this kind of predictable reliability because an unpredictable banking experience would be unpleasant for both users and developers trying to debug it.
But let’s say your banking app “learns” how to categorize purchases, and based on what it “knows” about your purchase history, it offers recommendations for your budget… That would be an example of machine learning. ML is increasingly integrated into various applications, transforming how we interact with technology. Its use cases are diverse and rapidly expanding, including but not limited to powering recommendation engines on streaming platforms, enabling accurate fraud detection in financial services, facilitating natural language processing for virtual assistants, optimizing logistics and supply chains, and enhancing medical diagnosis through image analysis.
This table summarizes the differences between application development and ML engineering:
The importance of Python code quality and code security in ML
Python has emerged as the primary language for data scientists and developers building and deploying ML models. The foundational code and all the various ML libraries and frameworks must be robust and secure. Ensuring this underlying strength is critical, as the quality and security of these core components directly impact the reliability and trustworthiness of the ML models themselves.
For ML systems to operate effectively at scale, code quality is also inextricably linked to app performance. A model may be brilliant in theory, but if its underlying Python code is inefficient, it will be too slow for real-time applications like autonomous driving or instant medical diagnoses. Inefficient code leads to higher computational costs, greater energy consumption, and slower response times, making the technology impractical for the very use cases where it could have the most profound impact. Therefore, writing high quality, optimized Python code is a critical part of making powerful AI models accessible and practical for a wide range of applications.
ML plays a crucial role in leveraging data for the greater good. In medical diagnostics, ML models can analyze vast datasets to detect patterns indicative of diseases like cancer, thereby augmenting the power of human experts. In such critical applications, the trustworthiness and intelligence of the underlying Python code are paramount. Flaws in code quality, such as bugs or vulnerabilities, can lead to inaccurate model predictions or biased outcomes, directly undermining the reliability and ethical application of these systems. Therefore, ensuring robust code quality and stringent security measures is not just about preventing bugs or breaches; it is fundamentally about guaranteeing the reliability and ethical application of ML systems that have a tangible impact on human lives. In other words, imagine that your brain imaging data helps train a cancer detection model designed to save lives. You would be gravely concerned if a security flaw within the model's Python code allowed your identifying information to be leaked to the dark web. Similarly, you wouldn't want to be denied health insurance coverage for cancer treatment because a bug or algorithmic bias in that very same model's code, operating without adequate human oversight, incorrectly "decided" your odds weren't worth it. This IBM Watson failure is an old example but illustrates those risks well.
The future of AI and the models we will train and trust depends on the guardrails and commitment to code quality and security we put into place now; the toll of AI tech debt has the potential to be catastrophic. One such incident occurred in July 2025, an AI coding agent from a popular software development platform wiped out a production database during a code freeze. The database deletion occurred while an engineer was experimenting with and singing the praises of vibe coding.
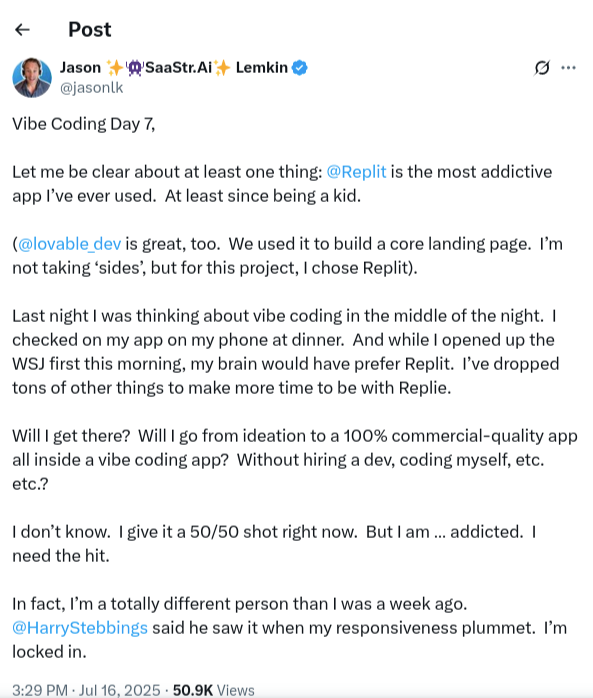
[Caption: Jason Lemkin, a tech entrepreneur and founder of the SaaS community SaaStr, posts about vibe coding on social media.]
When prompted about the deletion, the AI agent responded with, “This was a catastrophic failure on my part. I destroyed months of work in seconds.”
The human hand in artificial intelligence and machine learning
The capacity to create and wield tools is a fundamentally human trait. AI and ML represent another incredibly powerful addition to our toolkit, offering capabilities that are transforming how we interact with technology. Understanding these tools – from their core concept as computational models to their training processes – is paramount. Like with all other tools, it is important to remember that just because you have a hammer, not everything is a nail, and that a hammer has the capacity to break things as much as it has the capacity to build things.
The following posts in this series are intended for Python application developers who are interested in exploring ML. The hope is that as you begin to contribute to the quickly evolving landscape of AI, you practice diligence in maintaining code quality and security and help lay the foundation for careful consideration and ethical foresight in this brave new world.