

Vibe, then verify
Build trust into every line of code with SonarQube
Learn more🎧 Listen to a 2-minute summary of this article.
AI is rewriting the traditional software development playbook. Developers are adopting AI on the ground, output is exploding, and leaders are being asked to convert promise into predictable velocity. In our recent webinar, “A qualitative analysis of six leading LLMs,” we went beyond functional performance benchmarks to analyze the quality, security, and maintainability of code produced by top models. Here’s what matters for both technology leaders and developers—and how to operationalize it.
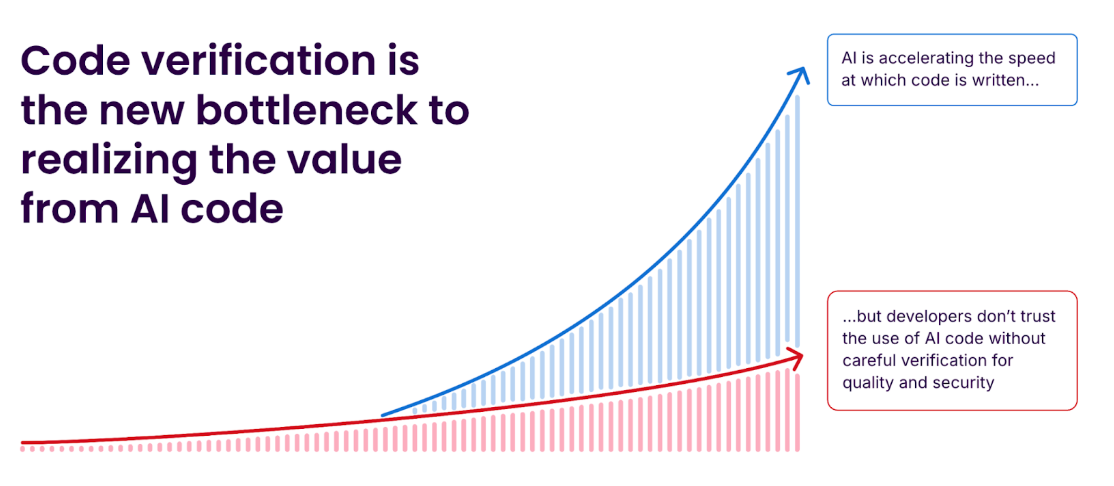
What’s really driving the “engineering productivity paradox:”
- Adoption is bottom-up and fast. A recent survey cited in the session shows 76% of developers are using or planning to use AI tools—this is a grassroots transformation, not a mandate.
- Output is unprecedented. Cursor alone accounts for nearly a billion lines of accepted code every day—more than all human developers combined.
- But productivity lags. Even with 30%+ of new code generated by AI in some organizations, estimated engineering velocity gains are closer to 10%, because humans must still review for security, reliability, and maintainability. That verification workload is the bottleneck—and the risk zone where subtle bugs and vulnerabilities accumulate.
A better lens than benchmarks: coding personalities
Our recent report “The Coding Personalities of Leading LLMs” evaluated thousands of Java tasks per model and inspected the code with production-grade criteria: complex bugs, critical vulnerabilities, and maintainability defects. The upshot: every model exhibits a distinct “coding personality” with predictable tradeoffs.
- Performance vs. simplicity is a real trade. Higher functional pass rates often come bundled with more verbose, more complex code—raising downstream review and maintenance costs.
- Security blind spots differ by model. All models struggled with injection and path traversal classes, but each showed signature weaknesses—for example, one trend we highlighted was a model skewing toward hard-coded secrets while another skewed toward cryptographic misconfigurations and inadequate I/O error handling.
- Reliability profiles are model-specific. We saw stark differences—from models that repeatedly fumble control flow to models that trade those basic slips for harder concurrency and threading defects. Your review strategy should follow the personality: basic logic checks for one model, security vulnerability fixes for another.
Why do these patterns emerge? Training data quality drives behavior. Models learn from a vast mix of excellent, mediocre, and flawed code—so they pick up bad habits alongside good ones. Vulnerable patterns and subtle logic bugs in the training corpus get reproduced in generated code. These personalities aren’t random; they’re learned.
The reasoning dial: helpful, but it shifts risk
Our data identified a "sweet spot" for AI performance at a medium reasoning setting. While turning up reasoning further can raise success rates, it also produces longer, denser code, which in turn increases cost and complexity. Crucially, reasoning doesn’t remove risk; it moves it. You trade obvious, high-severity blockers for subtler, harder-to-find bugs like concurrency and I/O error-handling defects.
What leaders should do now:
- Establish an independent verify layer. You need one dedicated tool that checks all your code for problems, no matter which AI model or human programmer wrote it. SonarQube is built to be that verification backbone, with consistent analysis across 35+ languages and developer-first workflows.
- Close the gap in your SDLC. Automated PR checks, quality gates, and portfolio-level visibility shrink the verification bottleneck without diluting standards—solving the paradox of more code but modest velocity gains.
- Govern AI coding explicitly. Make clear rules for how your team uses AI to write code. Make sure everyone follows those rules and have one clear standard for what “good code” looks like. It's a top priority for leaders to have a separate, unbiased system for checking all this new code.
What developers can do today:
- Calibrate review to the model’s personality. If your AI coding assistant tends to generate control-flow mistakes, emphasize branch/edge-case tests and static checks for conditionals. If it leans into concurrency, then prioritize thread-safety reviews, resource handling, and deterministic tests for race conditions.
- Keep the codebase simple and explainable. Complexity compounds risk. Use guardrails on function length, cognitive complexity, and duplication; comment sufficiently for future humans and tools to reason about the code.
- Eliminate stray code and risky dependencies. AI can introduce dead code, unused imports, or unnecessary packages—each a maintainability or supply-chain hazard. Scrub relentlessly and scan dependencies with policy in mind.
Vibe, then verify: How Sonar can help
Embracing the "vibe, then verify" philosophy doesn't mean sacrificing speed for safety. With Sonar, development teams can fuel their creativity without friction. By integrating directly into IDEs and CI/CD pipelines, Sonar provides real-time guidance on the quality and security of both human and AI-written code. This allows teams to maintain their creative momentum, catching and resolving issues as they arise, long before they become critical problems.
This seamless integration allows you to build trust into every line of code. Sonar's powerful analysis is specifically designed to detect the very classes of bugs and vulnerabilities that our research has shown are common in AI-generated code—from injection flaws and cryptographic missteps to concurrency issues and code smells. By enforcing quality gates before code is merged or released and offering AI CodeFix suggestions directly where developers work, Sonar accelerates remediation and shrinks the verification backlog, turning the promise of AI-driven velocity into a reality.
The takeaways
- There is no “safest” model. All leading LLMs generate severe vulnerabilities and maintainability issues; their personalities simply shift where the risks land.
- Functional benchmarks alone are insufficient. You must analyze the code’s quality, security, and maintainability profile—and tune your verification to each model’s tendencies.
- Independent assurance is non-negotiable. The fastest path to durable productivity is a developer-first verify layer that scales with AI output and standardizes trust across all code sources.
Leaders: set the strategy and guardrails. Developers: shape your prompts and reviews to the model in front of you. Together: vibe at AI speed—then verify with Sonar.