

TL;DR overview
- False positives in static analysis are findings that flag safe code as problematic, eroding developer trust and increasing the cost of code review when teams must triage noise.
- While false positives are a known challenge, their presence can sometimes point to legitimate code quality concerns—unclear logic, unusual patterns, or ambiguous intent that merits a second look.
- Sonar invests heavily in reducing false positive rates through interprocedural analysis, data flow tracking, and semantic understanding of code behavior beyond simple pattern matching.
- Teams can tune rules, mark accepted false positives with documented rationale, and configure quality profiles to balance sensitivity against noise for their specific codebase.
When writing a rule for static analysis, it’s possible that in some cases, the rule does not give the results that were expected. Unfortunately, naming a false positive is often far easier than fixing it. In this post, I’ll discuss how the different types of rules give rise to different types of false positives, which ones are easier to fix than others, and how you can help. I’ll end with insight into how issues that are false positives can still be true indicators that the code needs to change.
First let's take a look at what "false positive" means. There are two questions which shape the definition. First, is there a real issue in the code? Second, is an issue detected in the code? Combining them gives us a 2x2 Cartesian matrix:
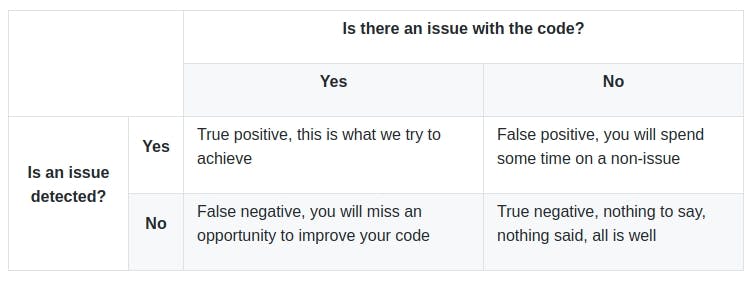
Why are there false positives?
There are several kinds of rules, that rely on different analysis techniques. It therefore comes as no surprise that there are different reasons for false positives.
One important distinction is whether the rule needs to compute the semantic properties of your program (For instance: Can this `string` be empty? Is it possible for a call to function `b` to happen before a call function `a`? …), or if it just needs to rely on syntactic properties (Is the program using `goto`? Does this `switch` handle all possible values of an `enum`? …). Let’s look at the impact this difference has.
Rice’s theorem
Rice’s theorem says that any non-trivial semantic property of a program is undecidable. A very well-known special case of this theorem is the halting problem, which was proven impossible to solve by Alan Turing. There is no way to write a rule that can detect, given the source code of another program, whether this other program will stop or run indefinitely.
Fortunately, these theorems don’t mean that static analysis is doomed to fail. There are heuristics that work reasonably well in many useful cases. It’s just not possible to write something that will work in all cases. Rules that rely on semantic properties will always be subject to false positives.
Non semantic rules
Not all rules are based on semantic properties; some are much simpler, but may still raise false positives. That may be because the implementation is buggy, or because the exact specification is hard to get right.
Let’s look at an example for a simple rule: Octal values should not be used. Octal literals start with a `0` in C and C++. They are not used very often, and there is a risk that someone reading the code confuses them with a decimal literal:
int const secretCode1 = 1234;
int const secretCode2 = 0420; // In fact, this number is 272 in decimal
So we created a rule to detect this situation. We correctly excluded some special cases from the start (for instance, the literal `0` is an octal literal, but it’s the only sane way to write 0, and in this case, the octal value and the decimal one are the same). So far, so good, the rule was added to the analyzer.
Alas, this rule had what we consider a false positive in its specification. In POSIX filesystems, permissions are set for user/group/others, and these permissions are a case where using octal notation really makes sense, because each digit then exactly matches one scope of permission (permission `0740` means `7` for user, `4` for group and `0` for others). We therefore decided that in this specific context, an octal literal should not raise an issue.
The astute developer may wonder: But what if I use an octal literal to indirectly set a permission?
void f(bool b) {
int mask = 0770;
if (b) {
mask |= 0007;
}
open("some_path", O_WRONLY, mask);
}In this situation, should we allow the 2 octal literals, or not? There is no perfect answer:
- We can err on the side of avoiding false positives by deciding that all octal values with 3 digits are acceptable. By doing so, we introduce false negatives, which is often the case when trying to avoid false positives
- We can track whether or not the value is used for a POSIX permission. This makes the rule more complex (and therefore slower), and it also makes this rule a subject of Rice’s theorem, when it was not before
- We can decide to report those cases, on the assumption (checked by looking at a lot of open-source code) that this is not a common pattern.
In this case, we decided that a low rate of false positives was more acceptable than the other options, and chose the third path.
Unfortunately, it was not the end of the story. Several months later, we discovered that if a POSIX function is called with several octal parameters, a bug in our implementation caused an issue to be raised. We corrected it.
Small taxonomy
We have seen three kinds of false positives. While there can be more accurate categorization, those three types are different enough that they might require different actions (the terms are mine, I’m not aware of a common terminology):
Semantic false positives - These are the false positives related to Rice’s theorem. They happen when we need to know some semantic properties of a program. For instance if a variable can be null at a certain point in the code, or if an index is within the bounds of an array.
Specification false positives - They happen most often for Code Smell rules. A Code Smell is merely an indicator, not a clear-cut Bug, so there are no clear-cut criteria. That means deciding if the code smells good or bad leaves some room for interpretation. There is always a gray area between good and bad, and it takes some time and lots of code examples to get good rules that work in most common cases.
Bugs causing false positives - Sometimes, we just have a bug in our implementation. We don’t detect what we are supposed to detect.
Why do we try to avoid false positives?
We’ve seen that avoiding false positives is not an absolute. It usually comes as a compromise, the trade-offs being more complex (slower and more error-prone) implementation, and the emergence of false negatives. Taken to the extreme, we can create a product with a rate of false positives of 0. We just have to never report anything. But such a product would not be very useful, would it?
On the other hand, there could be good reasons to select a position at the opposite of the spectrum: report everything. For instance, if we were focusing on safety-critical software, where a bug can have dire consequences, we would probably favor a strategy where we minimize false negatives, at the cost of requiring more time from developers to manually filter out the false positives produced by an analysis.
As an example, in our analyzer for C and C++, we include a set of rules that we did not design ourselves, but which come from the MISRA guidelines for safety-critical software. These rules were designed with a mindset where false positives are not such a big deal if they can help avoiding bad behaviors - even when the threat is rare. And we implemented them as is.
At SonarSource, we nevertheless believe that, when possible, we should favor minimizing false positives as much as possible. Why? From our experience, a tool that reports too much is a tool that will not be listened to after a short period of time. We really don’t want to cry wolf.
Additionally, we want to allow static analysis to be part of the development workflow, with the possibility for a team to decide to block a pull request if it does not pass some minimal quality criteria. Doing so would be painful if we raised many false positives.
Coming back to how we deal with MISRA rules, there are cases where we implemented two versions, one of which is a strict implementation of the MISRA rule, and one which is closer to our preferred philosophy: it will report fewer issues, retaining only the more important ones. For these MISRA-inspired rules we believe that we can reasonably reduce the noise without losing too much value. You can select which version you prefer depending on your context.
To sum it up, we try very hard to avoid false positives. And we need your help to accomplish that goal: If you discover a false positive in your analysis, please report it, so we can improve our products for everybody.
So, what can you do about false positives?
In the SonarQube Server & SonarQube Cloud UIs, you can mark them as such, so that we will no longer bother you with this issue. But this is just a short-term solution. There are probably better actions to take.
Report them
As was said earlier, we are eager to decrease the rate of false positives in our products. So if you see one, please report it in our community forum. If you have an idea why the code is triggering a false positive, that’s even better! We’ll be able to correct it faster. We are currently adding some features in our products to allow you to report false positive easily and accurately. Please use them if you can.
In some cases, especially with semantic false positives, it will be hard for us to remove a false positive. Theorems are like final bosses in a video game, they are very tough to defeat. But we’ll try to do our best anyway. For specification false positives we will have to see if we agree with your evaluation of the situation, and then we’ll correct them. And finally, Bugs causing false positives have a high priority in our backlogs, and are usually dealt with rapidly.
Post-mortem of a false positive
Before reaching the conclusion of this article, let’s take a side track and analyze a very nice false positive report we got on our community forum. This is the example that gave me the idea to write this article in the first place. It is about the rule Identical expressions should not be used on both sides of a binary operator, whose purpose is to detect buggy code such as if `( a == b && a == b )` which is probably the results of a copy/paste error. The user code was the following:
if (!DoSomething()) return xml->GoToParentNode() && xml->GoToParentNode();With the following comment:
As you can probably tell, this return jumps up twice in the XML structure, if the first jump is successful. Otherwise it will return `false` (`GoToParentNode` has `bool` return type).
While it might be debatable if this is ideal and whether it wouldn’t be clearer to write this in multiple lines with individual ifs etc., this is valid and the most succinct way.
We totally agree that this is a false positive for this rule (in the category bugs causing false positives), and we created a ticket in order to correct it. Nevertheless, I believe the second paragraph is very interesting: this code is probably not the best possible. While we can guess what this code means, we have to raise our level of awareness to read and understand this code.
Navigating the XML tree that way might be a common pattern in this codebase, in which case, it is perfectly fine, because maintainers of this code have been trained to read such code. But otherwise, while correct and succinct, I believe that this code is too clever, and is a Code Smell. Not the one that we indicated, but an issue nevertheless.
I would rather write this code in this dumb way, which clearly shows that we’re trying to navigate to the grandparent:
if (!DoSomething()) {
if (!xml->GoToParentNode()) { return false;}
return xml->GoToParentNode();
}Use them as a hint
Even though we have vowed to reduce the number of false positives in our analyzers, when you encounter one, you may still pause and ponder about why it happens.
A static analyzer is a tool that tries to understand source code. Which is what developers do all the time. Obviously, developers are much more accurate than any static analyzer, when they put their minds to it. But at the same time, they tend to get tired after a while. Source code should be easy to understand, and to reason about.
If a tool can’t do it, are you confident that developers can do it consistently, even on a Friday afternoon after a good tartiflette?
Conclusion
In this document I explained what false positives are, and why they are an inherent component of static analysis that can never be truly eliminated. And why we try to reduce them nevertheless.
When you encounter one, mark it as such and report it to us. And at the same time, take it as a hint. A hint that there is probably some issue with the code that triggered the false positive (even though the real issue might be totally unrelated to the issue we report). A hint that this code has the potential to be improved.
If you would like to comment or discuss this subject, you can do it in our community forum.