



The promise of AI-assisted coding is immense, but it rests on a simple, fundamental reality: the quality and security of the code generated by a Large Language Model (LLM) depends on the quality of the data that it was trained on. Recent research from Anthropic has shown that even a small amount of malicious or poor quality training data can have a massively negative impact on a model’s performance, exposing users to significant security and quality issues.
This isn’t just a theoretical problem. It is a trend confirmed by our recent research. The large and small language models that developers rely on generate code that contains bugs and critical security vulnerabilities. This is the natural outcome of models trained on vast public datasets where bad code is inevitably mixed with good. The adage of “garbage in, garbage out” has never been more relevant—or more costly.
At Sonar, we have found that the inverse is also true. If poor data has an exponentially negative effect, then high-quality data can deliver an exponentially positive one.
Our research has demonstrated that systematically improving the quality of model training data leads to a substantial improvement in the quality and security of the code an LLM produces.
That is why we built SonarSweep.
SonarSweep is a service designed to remediate, secure, and optimize the coding datasets used in model pre-training and post-training (including via supervised fine-tuning and reinforcement learning).
It employs Sonar’s industry-leading code analysis engines and expertise to “sweep,” the code datasets used in model training at scale. This ensures the datasets contain far fewer examples of quality and security issues and more examples of high-quality code.
In short, SonarSweep proactively ensures that models learn from high-quality and secure examples throughout their training, from pre-training to model alignment. This is an essential step to building reliable and trustworthy AI coding models.
The SonarSweep impact: Proven results
SonarSweep’s effectiveness comes from Sonar’s unique ability to identify and automatically fix over 6,700 different types of quality and security issues in the training datasets. It can operate highly effectively at large scale, as it is built on the same SonarQube technology that analyzes over 750 billion lines of code each day, across over 35+ different programming languages.
To validate our approach, we conducted extensive tests across a wide spectrum of models, from 1.5 billion parameters to hundreds of billions (including Llama 3.1 70B and GPT-4o). Through Sonar’s comprehensive analysis on over 4,442 unique Java coding assignments, we found that models fine-tuned with SonarSweep-processed data generated code with:
- Up to a 67% reduction in security vulnerabilities
- Up to a 42% reduction in bugs

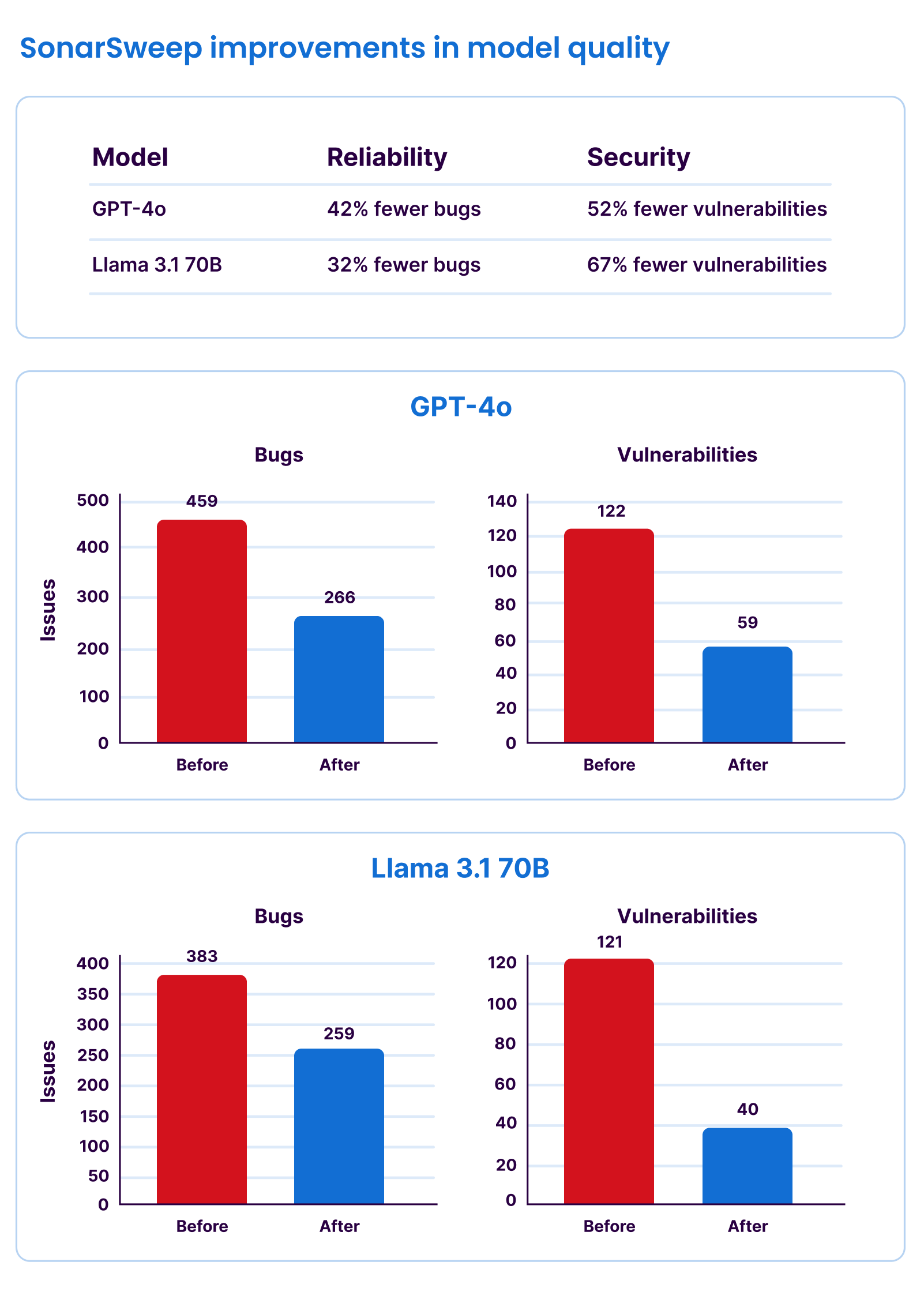
Crucially, these significant gains in code quality and security were achieved without degradation in the functional correctness of the output.
Where sweeping adds value
Coding is one of the killer apps of the generative AI world. But, while the current generation of large foundation models from companies like OpenAI and Anthropic provide increasingly functionally correct code (though still with significant bugs, security issues, and maintainability concerns), they are not a fit for every situation. Enterprises and LLM providers have the need to improve or customize their models for a range of purposes including:
- Foundation model companies looking to improve their models to make them more security, quality, and maintainability conscious.
- Open source model developers looking to drive improved performance with smaller budgets and less training data access than the competition.
- Enterprises such as financial institutions, public and defense sectors, who need to develop or tailor custom models to run in their private environments.
- Agentic AI companies and enterprises leveraging distillation techniques to develop Small Language Models (SLMs) that can operate at a lower cost and higher performance for specific tasks. These models are often developed on platforms such as those provided by Databricks and IBM.
Today, companies have to hire hundreds or thousands of contract software developers to vet their code training datasets. This is expensive, not scalable, and hard to deploy for all but the largest companies. SonarSweep transforms these initiatives, ensuring high functional performance at lower risk and substantially lower cost.
Now available in early access
We are excited to announce that SonarSweep is now available in early access. As part of this program, we are engaging with the world’s leading companies to train both general and specialized LLMs that excel in generating performant, reliable, and secure code.