
Schaffen Sie Vertrauen in Ihre Codierungsmodelle
Beseitigen Sie proaktiv systemische Fehler aus den Trainingsdaten, um grundlegende Modelle zu trainieren, die von Grund auf sicher sind.
Große Sprachmodelle sind leistungsstark, übernehmen jedoch Mängel aus ihren Trainingsdaten. SonarSweep ist ein Dienst, der darauf ausgelegt ist, die für das Vor- und Nachtraining von Modellen verwendeten Codierungsdatensätze zu bereinigen, zu sichern und zu optimieren.

Die Qualität von KI-generiertem Code hängt von der Qualität der Daten ab, mit denen LLMs trainiert wurden. Untersuchungen zeigen, dass schon eine geringe Menge an Daten minderer Qualität ein Modell unverhältnismäßig stark „vergiften“ kann, was dazu führt, dass es fehlerhaften, unsicheren Code generiert.
Umfangreiche öffentliche Datensätze, die Grundlage für die meisten LLMs, sind eine chaotische Mischung aus gutem Code und Code-Schnipseln, die voller Fehler und Sicherheitslücken sind.
Während des Trainings verinnerlicht das LLM diese fehlerhaften Muster und ist nicht in der Lage, guten von schlechtem Code zu unterscheiden. Es lernt, dieselben Fehler zu wiederholen, die ihm beigebracht wurden.
Die LLMs geben ihrerseits Fehler und Schwachstellen bei der Codegenerierung weiter, die ihren Weg in das Produkt finden können und eine gründliche Überprüfung erfordern.
Generative KI verändert die Art und Weise, wie wir programmieren, doch LLMs haben eine entscheidende Einschränkung: Sie produzieren oft Code mit versteckten Fehlern, Sicherheitslücken und Wartungsaufwand. Für LLM-Anbieter und Unternehmen, die einen höheren Qualitätsstandard benötigen, besteht ein klarer Bedarf an der Feinabstimmung und Anpassung von Modellen. SonarSweep bietet die unverzichtbare Datenqualitätsschicht für:

Erstellen Sie von Grund auf sichere und zuverlässige Modelle, indem Sie die Trainingsdaten an der Quelle verbessern und Ihren Kunden so einen Wettbewerbsvorteil auf dem Markt verschaffen.

Entwickeln Sie maßgeschneiderte Modelle sicher in privaten Umgebungen und helfen Sie Ihren Kunden dabei, strenge Compliance-Anforderungen zu erfüllen und sensible geistige Eigentumsrechte zu schützen.
Erstellen Sie leistungsstarke, kosteneffiziente Small Language Models (SLMs) für spezialisierte agentische Workflows auf Plattformen wie Databricks und IBM.

Erzielen Sie mit begrenztem Budget Spitzenleistung, indem Sie Trainingsdatensätze optimieren, um leistungsfähigere Modelle mit weniger Daten und Rechenaufwand zu erstellen.


SonarSweep analysiert und behebt automatisch Tausende von Fehlern, Schwachstellen und Problemen mit der Codequalität innerhalb des Trainingsdatensatzes in großem Maßstab.

Ein strenger Filterprozess entfernt Code von geringer Qualität. Der bereinigte Datensatz wird anschließend ausgeglichen, um ein vielfältiges und repräsentatives Lernen für robuste Modellfähigkeiten sicherzustellen.

Der endgültige, „bereinigte“ Datensatz ist ein optimiertes, hochwertiges Asset, das für das Modelltraining bereit ist und eine deutliche Verbesserung der Qualität des generierten Codes bewirkt.
Beseitigen Sie proaktiv systemische Fehler aus den Trainingsdaten, um grundlegende Modelle zu trainieren, die von Grund auf sicher sind.
SonarSweep nutzt die branchenführenden Code-Analyse-Engines von Sonar, um große Mengen an Trainingscode automatisch zu verarbeiten, Probleme zu beheben und fehlerhafte Daten in hochwertige Trainingsbeispiele umzuwandeln.

Indem wir Code korrigieren, anstatt ihn zu löschen, bewahren wir wertvolle Lernbeispiele für das Modell und verbessern so dessen Verständnis komplexer Muster.

Unsere Engine verwandelt schlechte Beispiele in gute und erhöht so systematisch die Gesamtqualität und die Sicherheitslage des gesamten Datensatzes.

Basierend auf derselben Analyse, der über 7 Millionen Entwickler vertrauen, um weltweit 700 Milliarden Zeilen Code zu sichern.
SonarSweep ist jetzt im Early Access verfügbar. Arbeiten Sie mit Sonar zusammen, um zu den Ersten zu gehören, die die nächste Generation sicherer, zuverlässiger und geschützter Codierungsmodelle entwickeln.
4.6 / 5
SonarSweep is a product from Sonar that remediates, secures, and optimizes coding datasets used to train AI language models. It is designed for AI companies and model builders — not for software development teams managing their own codebases.
Coding LLMs are typically trained on large volumes of publicly available open-source code, which frequently contains bugs, security vulnerabilities, and poor patterns. Models learn from these flawed examples and reproduce — and in many cases amplify — those flaws in the code they generate. SonarSweep addresses this at the root by cleaning and improving the training data before it is used to train or fine-tune a model.
SonarSweep shares its underlying code analysis engines with SonarQube and SonarQube Cloud, but it is a completely separate service and does not integrate with either product. It is not an add-on, extension, or feature of any SonarQube edition.
Where SonarQube and SonarQube Cloud help development teams detect quality and security issues in their own application code during development and CI/CD, SonarSweep processes large code datasets that AI companies use to train models. The relationship is a shared technological foundation — Sonar's analysis engines — applied to an entirely different use case and a different customer.
Coding LLMs are pre-trained on raw public open-source code — code that's full of bugs, vulnerabilities, and poor patterns. Models don't just absorb these flaws; they amplify them in everything they generate. SonarSweep fixes this at the source by cleaning training data before a model ever sees it.
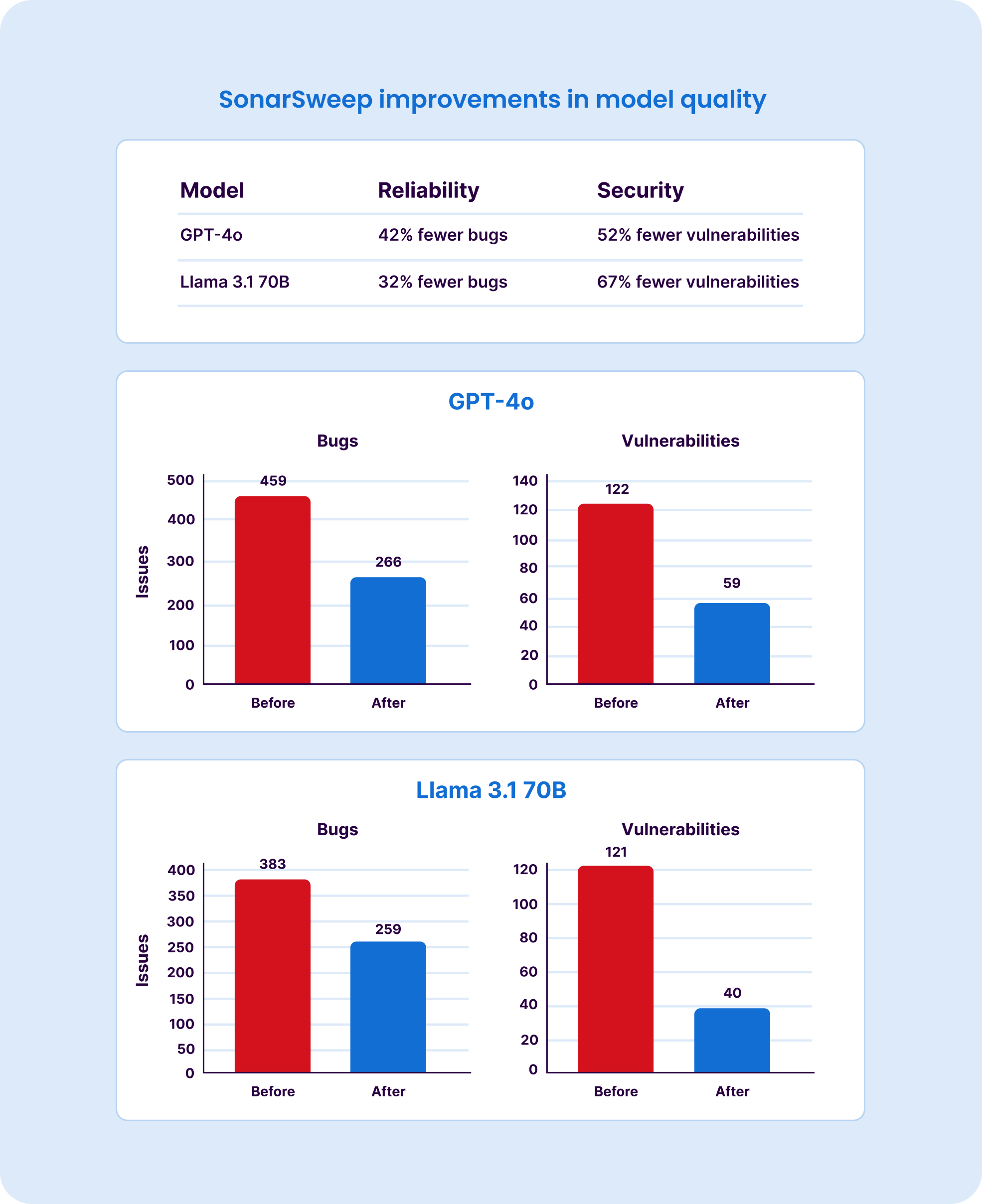
It reduces security vulnerabilities in model output by up to 67% and cuts bugs by up to 42%. It also handles a subtler problem: naively removing flawed code can skew language distribution in a dataset, so SonarSweep rebalances after cleaning to preserve model proficiency across all languages. And by addressing quality upfront, it eliminates the need for costly post-training correction passes.
SonarQube for IDE (formerly SonarLint) is a developer productivity tool that runs inside editors like VS Code, IntelliJ, and Eclipse, giving individual developers real-time feedback on quality and security issues as they write code. It operates at the developer level, in the IDE, during active development.
SonarSweep is not a developer tool at all. It is a data processing service for AI companies that are training or fine-tuning coding LLMs. It does not run in an IDE, does not provide feedback to developers, and is not part of a development workflow.
Yes — this is the core purpose of SonarSweep. The quality of code a language model generates is directly shaped by the quality of the data it trained on. A model that learned from code full of vulnerabilities and bugs will reproduce those patterns at scale. SonarSweep intervenes at the data stage, before training, to raise the quality floor of what the model learns from.
Models trained on SonarSweep-prepared datasets have demonstrated up to 67% fewer security vulnerabilities and up to 42% fewer bugs in their generated code compared to models trained on unswept data — with no degradation in functional performance. This was validated on the GPT-OSS-20B model.
SonarSweep supports 35+ programming languages, drawing on the full breadth of Sonar's code analysis engines — the same engines that power SonarQube and SonarQube Cloud.
In the context of LLM training data, this means SonarSweep can analyze, filter, and remediate code across all the languages that typically appear in large public code datasets: common back-end languages, front-end languages, scripting languages, systems languages, and more. Across these languages, it can identify and automatically fix over 6,700 distinct types of quality and security issues.
SonarSweep doesn't produce code changes for developers to review in pull requests. It processes and delivers cleaned training datasets to AI companies. Governance in this context sits with the AI team — validating dataset quality and model output before using the swept data in a training run.
No. SonarSweep has no connection to any SonarQube edition. It is a separate product for companies building or fine-tuning coding LLMs — not a feature unlocked through any SonarQube subscription tier.
The ROI is for AI companies, not development teams. Models trained on SonarSweep-processed data produce up to 67% fewer security vulnerabilities and up to 42% fewer bugs — with no loss in functional performance. It also reduces training cost by addressing data quality upfront, eliminating expensive post-training correction cycles.