

TL;DR 概要
- AI加速された開発は、コード品質の負債(バグ、セキュリティ脆弱性、構造的複雑性、技術的負債)の蓄積を避けられずに増加させます。これはAIモデルが欠陥を持っているからではなく、生成されたコードの膨大な量が手動レビューの能力を圧倒するからです。
- LLMが単位あたりのコード品質を向上させても、速度の向上は手動コードレビューと検証のボトルネックを引き起こします。未検証のAI出力を大規模に受け入れるチームは、品質の低下が累積し、最終的にはAIツールが速度を上げる以上に納品を遅らせることになります。
- SonarQubeは、AI生成と生産の間の自動検証レイヤーとして機能し、コードの臭い、重複、構造的不整合などの構造的問題を文脈に応じて分析し、AI生成が体系的に導入する問題をキャッチします。
- 戦略的な対応はAIの使用を制限することではなく、同じ規模で自動検証を確立することです。SonarQubeをすべてのブランチ、プルリクエスト、マージに統合し、高速なAI生成に対して同等の速度で品質を確保します。
現代のソフトウェア開発の実践は根本的に変化し、市場の速度をソフトウェアの価値の主要な推進力として優先しています。大規模言語モデル(LLM)とAIコーディングアシスタントの採用は開発ライフサイクルを急速に加速させ、開発者が生産性を最大55%向上させ、タスクを2倍の速さで完了する可能性を提供しています。この大幅な機能提供速度の向上は、トップクラスの組織にとって競争上の必須事項となっています。
しかし、この加速は根本的なリスクをもたらします:エンジニアリング生産性のパラドックスです。膨大な速度の向上は、バグ、セキュリティ脆弱性、構造的複雑性、技術的負債などのコード品質の負債の蓄積を必然的に増加させます。この品質の低下は開発者の怠慢によるものではなく、AIコード生成の速度とメカニズムの事実上の結果です。LLMが生成するコードの品質が向上しても、膨大な量が手動コードレビューと検証のボトルネックを引き起こします。この速度へのシフトにより、コードベースに新たな問題が大量に増加し、全体的な品質が低下します。この低下を受け入れることは、市場への迅速な進出の利点のための計算された戦略的なトレードオフと見なされることがよくあります。
戦略的な目標はAIの使用を排除することではなく、増加したコード量によって引き起こされる品質問題を管理し軽減するための自動コードレビューとガバナンスメカニズムを確立することです。
コード品質の転換点の定量化
生成AIの影響はソフトウェア開発ライフサイクル(SDLC)のすべてのフェーズを加速させています。AI支援のプルリクエスト(PR)は中央値の解決時間を60%以上短縮しましたが、このスループットの増加は開発者にレビューを行うための負荷を増やし、品質問題の表面積を指数関数的に増加させます。
構造的劣化のメカニズム
技術的負債は、高い循環的複雑性、過剰な重複、保守性の欠如などの問題によって定義され、急速に蓄積しています。この構造的負債は、LLMが局所的な機能的正確性を優先し、グローバルなアーキテクチャの一貫性や長期的な保守性を犠牲にするために発生します。
経験的証拠はこの劣化を確認しています:
- 加速された重複: AIが機能的なスニペットを瞬時に生成する能力は、開発者が複雑なリファクタリングを行うよりも迅速で重複したコードを受け入れる構造的なインセンティブを生み出します。GitClearの2020年から2024年の分析は、5行以上の重複したコードブロックの頻度が8倍に増加したことを追跡し、コードの再利用の大幅な低下を確認しました。さらに、2024年はコピー/ペーストされた行数が移動(リファクタリング)された行数を超えた初めての年でした。
- 複雑性の増加: 循環的複雑性は、保守の難しさと相関する指標であり、LLM生成コードでは一般的に高くなっています。AIがコード行数、ハルステッドメトリクス、循環的複雑性を増加させるため、保守性の問題の増加が構造的に弱いコードの蓄積を確認しています。
納品の不安定性の隠れたコスト
コード負債の急増は、レビューと修正の作業負荷を直接的に増加させます。Harnessの調査によると、67%の開発者がAI生成コードのデバッグにより多くの時間を費やしていると報告しています。この膨大なAI生成コードは、保守と統合が本質的に難しく、コストがかかります。
速度と品質のトレードオフを確認する重要な証拠は、Google 2025 DORAレポートから得られました。AIの採用が90%増加したことが、バグ率の9%増加、コードレビュー時間の91%増加、プルリクエストサイズの154%増加と関連していると推定されました。これは、高速コードにおける潜在的な欠陥密度の増加を確認しています。
これらのデータポイントの収束と大規模な重複の急増、DORAの安定性の低下は、2024年がコード品質の転換点であり、AI支援のコーディングプラクティスの業界全体の採用と一致して、全体のコードベースのボリュームの割合としての低品質コードの蓄積が指数関数的に加速し始めたことを確認しています。2025年の予測ガイドで、Forresterは2026年までに技術的意思決定者の75%が中程度から深刻な技術的負債に直面すると予測しています。
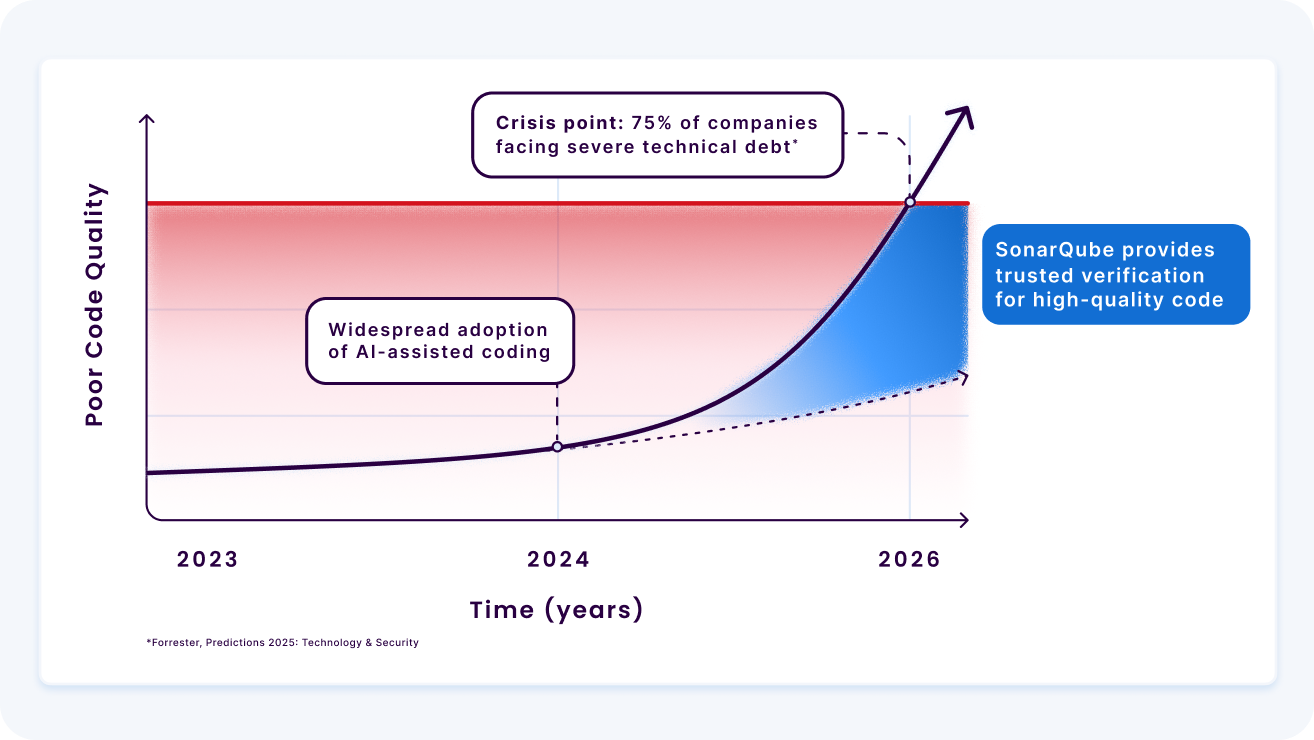
SonarQubeは高品質コードのための業界標準の信頼と検証レイヤーです。
エンジニアリング生産性のパラドックスを解決することは戦略的な必須事項です
技術的負債の指数関数的な軌道は、ジレンマを生み出します。企業は競争上の速度のためにAIを採用しなければなりませんが、この採用は技術的負債を増加させ、管理するためにさらに多くのリソースを必要とします。
DORA増幅仮説
Googleの2025年DORAレポートは決定的な仮説を導入しました:AIはチームを修正するのではなく、既にあるものを増幅します。
- 強力な制御システム(例:堅牢なテスト、成熟したプラットフォーム)を持つチームは、AIを利用して安定した納品で高いスループットを達成します。
- 緊密に結合されたシステムに制約されている苦戦するチームは、変更量の増加が既存のコーディング問題をさらに悪化させることを発見します。
これは核心の前提を確認します。核心の問題は、AIの速度をコードベースの劣化を伴わずに活用するために必要なツールを実装していないことです。AIが提供する大規模な生産性向上を確保するために、組織は反応的な手動レビューとデバッグから、コードがマージされる前に品質の整合性を強制するプロアクティブな自動コードレビューと品質ゲートに移行する必要があります。
SonarQube: 管理された加速のための検証レイヤー
高速採用フェーズで生成された技術的負債の蓄積は、自動コードレビューと修正がなければ構造的および財政的に持続不可能になります。解決策は、文脈に応じた専門的なツールにあり、"ラストマイル"の品質チェックを提供します。
SonarQubeは、この危機に直接対処する業界標準の自動コードレビュープラットフォームです。
SonarQubeがエンジニアリング生産性のパラドックスを解決する方法
エンジニアリング生産性のパラドックスは、未検証のAI使用から管理された加速への移行によって解決されます。SonarQubeは、すべてのブランチ、プルリクエスト、マージで開発ワークフローに直接コード品質とコードセキュリティチェックを統合することにより、必要な検証と信頼のレイヤーとして機能します。
- 文脈に応じた自動レビュー: 標準的なAIツールは、深い重複に根ざした微妙な品質問題を検出するための必要な範囲を欠いていることがよくあります。SonarQubeは、重複、古い構造、アーキテクチャの不整合を大規模なコードベース全体で特定し、人間の開発者が手動で実行するには複雑すぎるまたは高価すぎるタスクを実行します。
- 劣化指標の軽減: SonarQubeは、保守性指数を数学的に低下させる構造的問題(高い循環的複雑性や重複など)を積極的に検出し修正します。
- 指数関数的な利益の維持: 堅牢なプラットフォームとテストを持つエリートチームにとって、SonarQubeの実装は高い負債の蓄積を積極的に軽減します。これにより、制御された予測可能なコストで速度を最大化し、指数関数的な利益を達成します。SonarQubeのような自動化された文脈に応じたAI検証システムを活用することで、低品質コードの蓄積の傾向が下向きに曲がります。
SonarQubeの開発者ワークフローへの統合は、将来の価値提案を生の出力量からインテリジェントなコード作成へとシフトさせます。厳格なコードガバナンスと専門的な文脈に応じた自動コードレビューを実施することで、企業は管理された加速に移行し、技術投資に対する持続的で指数関数的なリターンを達成できます。