
Renforcez la confiance dans vos modèles de codage
Éliminez de manière proactive les failles systémiques des données d'entraînement afin de former des modèles de base sécurisés dès leur conception.
Les grands modèles linguistiques sont puissants, mais ils héritent des défauts de leurs données d'entraînement. SonarSweep est un service conçu pour corriger, sécuriser et optimiser les ensembles de données de codage utilisés lors du pré-entraînement et du post-entraînement des modèles.

La qualité du code généré par l'IA dépend de la qualité des données sur lesquelles les grands modèles linguistiques ont été entraînés. Des recherches montrent que même une petite quantité de données de mauvaise qualité peut « empoisonner » un modèle de manière disproportionnée, l'amenant à générer du code bogué et non sécurisé.
Les vastes ensembles de données publics, qui constituent la base de la plupart des LLM, sont un mélange chaotique de bon code et d'extraits truffés de bogues et de failles de sécurité.
Pendant l’entraînement, le LLM intériorise ces schémas défectueux, incapable de distinguer le bon code du mauvais. Il apprend à reproduire les mêmes erreurs qu’on lui a enseignées.
Les LLM reproduisent à leur tour des bogues et des vulnérabilités lorsqu’ils génèrent du code, qui peut se retrouver dans le produit et nécessite une vérification rigoureuse.
L’IA générative transforme notre façon de coder, mais les LLM présentent une limite critique : ils produisent souvent du code contenant des bogues cachés, des failles de sécurité et une dette de maintenabilité. Pour les fournisseurs de LLM et les entreprises qui exigent un niveau de qualité supérieur, il existe un besoin évident d’affiner et de personnaliser les modèles. SonarSweep fournit la couche de qualité des données indispensable pour :

Construire des modèles sécurisés et fiables dès leur conception en améliorant les données d'entraînement à la source, offrant ainsi à leurs clients un avantage concurrentiel sur le marché.

Développer des modèles personnalisés en toute confiance dans des environnements privés, aidant ainsi leurs clients à respecter des exigences de conformité strictes et à protéger leur propriété intellectuelle sensible.
Créer des modèles linguistiques de petite taille (SLM) performants et rentables pour des flux de travail agentiques spécialisés sur des plateformes telles que Databricks et IBM.

Atteignez des performances de pointe avec un budget limité en optimisant les ensembles de données d'entraînement afin de créer des modèles plus puissants avec moins de données et de puissance de calcul.


SonarSweep analyse et corrige automatiquement des milliers de bogues, de vulnérabilités et de problèmes de qualité du code au sein de l'ensemble de données d'entraînement à grande échelle.

Un processus de filtrage rigoureux est appliqué pour éliminer le code de mauvaise qualité. L'ensemble de données raffiné est ensuite équilibré afin de garantir un apprentissage diversifié et représentatif pour des capacités de modèle robustes.

L'ensemble de données final, « nettoyé », est une ressource optimisée et de haute qualité prête pour l'entraînement des modèles, ce qui se traduit par une amélioration significative de la qualité du code généré.
Éliminez de manière proactive les failles systémiques des données d'entraînement afin de former des modèles de base sécurisés dès leur conception.
SonarSweep s’appuie sur les moteurs d’analyse de code de pointe de Sonar pour traiter automatiquement de grands volumes de code d’entraînement, corriger les problèmes et transformer les données défectueuses en exemples d’entraînement de haute qualité.

En corrigeant le code plutôt qu’en le supprimant, nous conservons des exemples d’apprentissage précieux pour le modèle, améliorant ainsi sa compréhension des schémas complexes.

Notre moteur transforme les mauvais exemples en bons exemples, améliorant systématiquement la qualité globale et le niveau de sécurité de l’ensemble du jeu de données.

Optimisé par la même analyse à laquelle font confiance plus de 7 millions de développeurs pour sécuriser 700 milliards de lignes de code à travers le monde.
SonarSweep est désormais disponible en accès anticipé. Collaborez avec Sonar pour être parmi les premiers à créer la prochaine génération de modèles de codage sûrs, fiables et sécurisés.
4.6 / 5
SonarSweep is a product from Sonar that remediates, secures, and optimizes coding datasets used to train AI language models. It is designed for AI companies and model builders — not for software development teams managing their own codebases.
Coding LLMs are typically trained on large volumes of publicly available open-source code, which frequently contains bugs, security vulnerabilities, and poor patterns. Models learn from these flawed examples and reproduce — and in many cases amplify — those flaws in the code they generate. SonarSweep addresses this at the root by cleaning and improving the training data before it is used to train or fine-tune a model.
SonarSweep shares its underlying code analysis engines with SonarQube and SonarQube Cloud, but it is a completely separate service and does not integrate with either product. It is not an add-on, extension, or feature of any SonarQube edition.
Where SonarQube and SonarQube Cloud help development teams detect quality and security issues in their own application code during development and CI/CD, SonarSweep processes large code datasets that AI companies use to train models. The relationship is a shared technological foundation — Sonar's analysis engines — applied to an entirely different use case and a different customer.
Coding LLMs are pre-trained on raw public open-source code — code that's full of bugs, vulnerabilities, and poor patterns. Models don't just absorb these flaws; they amplify them in everything they generate. SonarSweep fixes this at the source by cleaning training data before a model ever sees it.
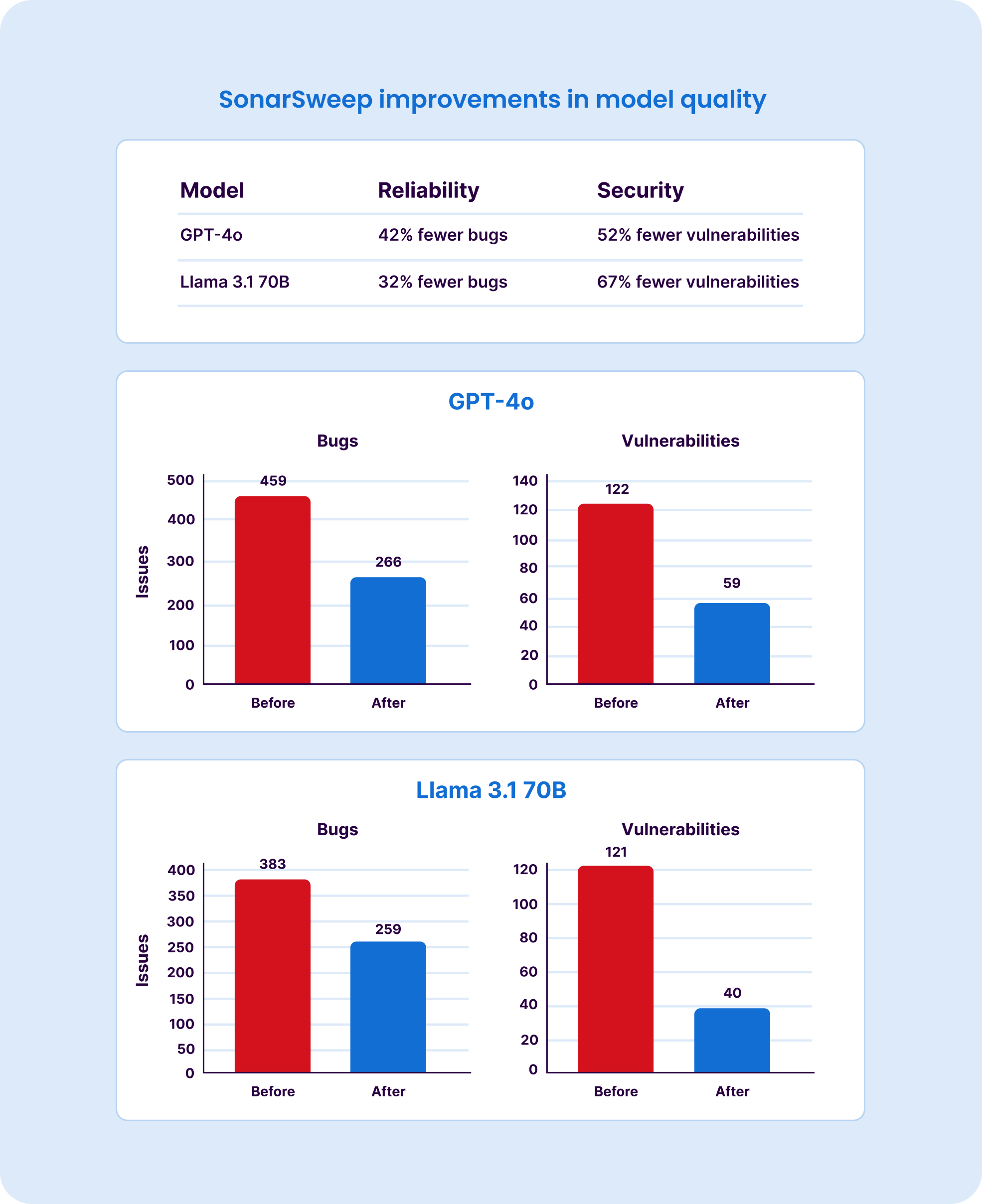
It reduces security vulnerabilities in model output by up to 67% and cuts bugs by up to 42%. It also handles a subtler problem: naively removing flawed code can skew language distribution in a dataset, so SonarSweep rebalances after cleaning to preserve model proficiency across all languages. And by addressing quality upfront, it eliminates the need for costly post-training correction passes.
SonarQube for IDE (formerly SonarLint) is a developer productivity tool that runs inside editors like VS Code, IntelliJ, and Eclipse, giving individual developers real-time feedback on quality and security issues as they write code. It operates at the developer level, in the IDE, during active development.
SonarSweep is not a developer tool at all. It is a data processing service for AI companies that are training or fine-tuning coding LLMs. It does not run in an IDE, does not provide feedback to developers, and is not part of a development workflow.
Yes — this is the core purpose of SonarSweep. The quality of code a language model generates is directly shaped by the quality of the data it trained on. A model that learned from code full of vulnerabilities and bugs will reproduce those patterns at scale. SonarSweep intervenes at the data stage, before training, to raise the quality floor of what the model learns from.
Models trained on SonarSweep-prepared datasets have demonstrated up to 67% fewer security vulnerabilities and up to 42% fewer bugs in their generated code compared to models trained on unswept data — with no degradation in functional performance. This was validated on the GPT-OSS-20B model.
SonarSweep supports 35+ programming languages, drawing on the full breadth of Sonar's code analysis engines — the same engines that power SonarQube and SonarQube Cloud.
In the context of LLM training data, this means SonarSweep can analyze, filter, and remediate code across all the languages that typically appear in large public code datasets: common back-end languages, front-end languages, scripting languages, systems languages, and more. Across these languages, it can identify and automatically fix over 6,700 distinct types of quality and security issues.
SonarSweep doesn't produce code changes for developers to review in pull requests. It processes and delivers cleaned training datasets to AI companies. Governance in this context sits with the AI team — validating dataset quality and model output before using the swept data in a training run.
No. SonarSweep has no connection to any SonarQube edition. It is a separate product for companies building or fine-tuning coding LLMs — not a feature unlocked through any SonarQube subscription tier.
The ROI is for AI companies, not development teams. Models trained on SonarSweep-processed data produce up to 67% fewer security vulnerabilities and up to 42% fewer bugs — with no loss in functional performance. It also reduces training cost by addressing data quality upfront, eliminating expensive post-training correction cycles.