

TL;DR 概要
- Sonarの最新のLLMコード品質分析では、4,000以上のJavaタスクを対象に実施され、GPT-5.2 Highが最も優れたセキュリティ姿勢(MLOCあたり16のブロッカー脆弱性)を達成しましたが、最も多くのコード量(974,379 LOC)を生成し、メンテナンスの負担が大きいことが判明しました。
- Claude Sonnet 4.5は、パストラバーサルやインジェクションの欠陥を含むMLOCあたり198のブロッカー脆弱性を生成しましたが、Opus 4.5 ThinkingはこれをMLOCあたり44に減少させ、推論モードがセキュリティ制約の検証を意味のある形で改善することを示唆しています。
- コードの臭いはすべてのモデルで支配的で、検出された問題の92〜96%を占めており、AI生成コードのスケールでのメンテナンス性が普遍的なコストであることを確認しています。
- 結果はSonar LLMリーダーボードで利用可能で、エンジニアリングリーダーにAIモデル選択を情報に基づいて行うための透明な品質データを提供します。
機能ベンチマークはAIモデルを評価するための標準であり、生成されたコードがテストケースを通過できるかどうかを効果的に測定します。LLMが進化するにつれて、これらの機能的な課題を解決する能力がますます向上しています。しかし、このコードを本番環境に展開するエンジニアリングリーダーにとって、機能的な正確さは方程式の半分に過ぎません。
AIコーディングモデルの実際の効果を理解するには、その構造的品質、セキュリティ、およびメンテナンス性も理解する必要があります。幸いなことに、Sonarは毎日7500億行以上のコードを分析しているため、この作業を行うのに最適な立場にあります。
数ヶ月前、私たちはSonarQube静的解析エンジンを使用して、4,000以上の異なるJavaプログラミング課題でテストすることにより、主要なLLMで作成されたコードの品質、セキュリティ、およびメンテナンス性を分析し始めました。
今日、私たちはすべての評価を新しいSonar LLMリーダーボードで利用可能にし、GPT-5.2 High、GPT-5.1 High、Gemini 3.0 Pro、Opus 4.5 Thinking、およびClaude Sonnet 4.5に関する最新の発見を共有しています。
トレードオフの可視化
異なるモデルのトレードオフと動作を理解するために、3つの重要な次元でプロットしました: 合格率(X軸)、認知的複雑性(Y軸)、冗長性(バブルサイズ)。
モデルがより「パフォーマンスが高く」なり右に移動するにつれて、その出力はより冗長で複雑になり、コードをレビューし使用するエンジニアに対する負担が増します。
複雑性の相関
私たちの研究は、モデルの推論能力とコードの複雑性の間に相関があることを示しています。モデルがより難しい問題に対して洗練された状態を持つ解決策を試みると、しばしば単純なコードから離れていきます。この変化は、単純な構文エラーよりも検出が難しいエンジニアリングの課題を引き起こします。
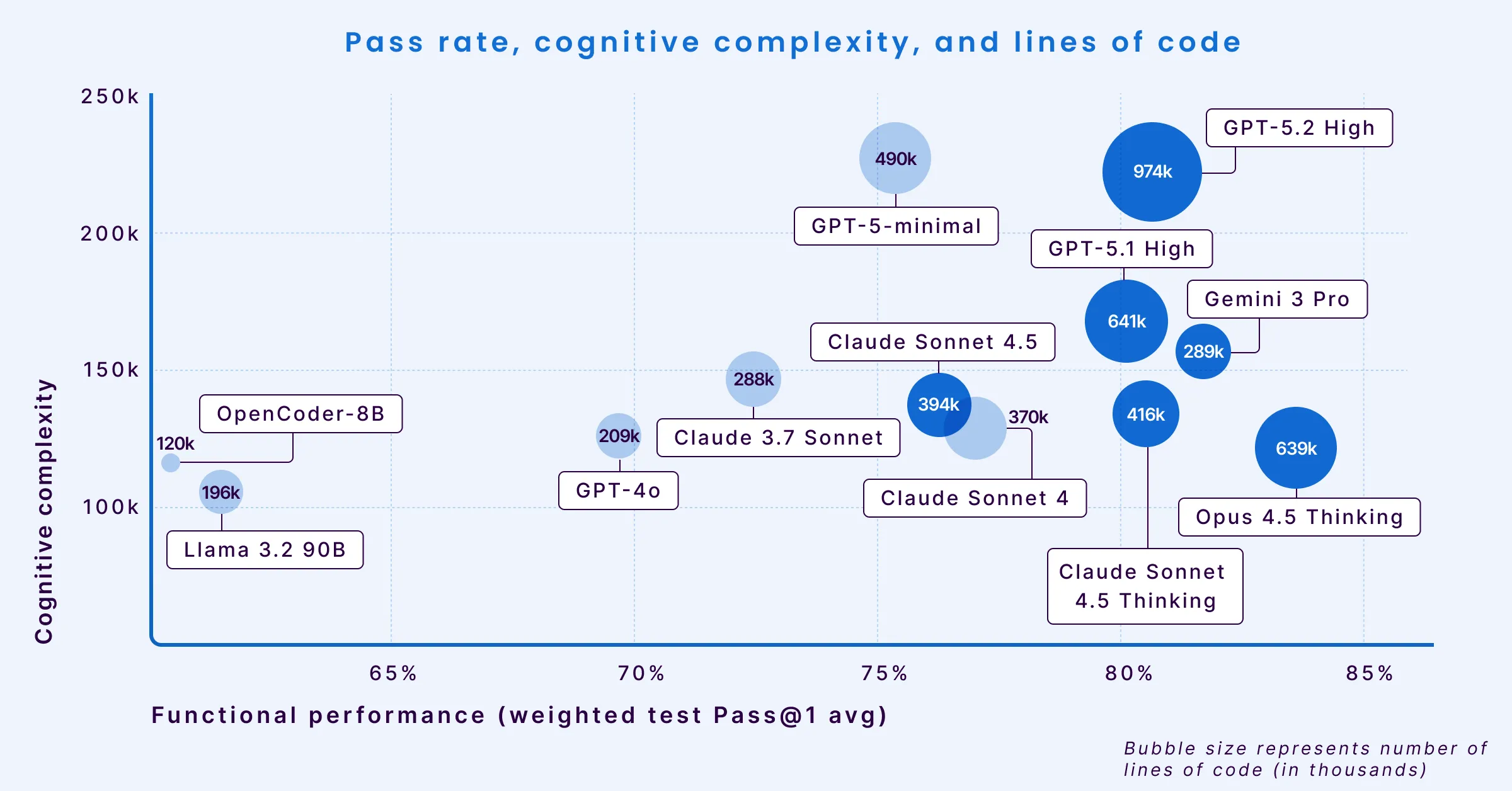
- Opus 4.5 Thinkingは機能的なパフォーマンスで83.62%の合格率を達成し(したがって上記のチャートで最も右に位置しています)、しかしこのパフォーマンスは高い冗長性を伴い、ベンチマークテストを解決するために639,465行のコード(LOC)を生成しています(これがチャート上で最も大きなバブルサイズの1つである理由です)。これは、より冗長でないモデルの2倍以上のボリュームです。
- Gemini 3 Proは効率性の異常値として際立っています。81.72%の合格率を達成しながら、低い認知的複雑性と低い冗長性(小さなバブルサイズ)を維持しています。この組み合わせは、簡潔で読みやすいコードで複雑な問題を解決する独自の能力を示唆しています。しかし、Geminiは他の最近のモデルと比較して最も高い問題密度を持っています。
- GPT 5.2 Highは機能的なパフォーマンスで3位(80.66%)にランクインし、Opus 4.5とGemini 3 Proに続いています。高い合格率にもかかわらず、コホートの中で最も多くのコード量(974,379 LOC)を生成しました。前任者(GPT 5.1 High)と比較して、GPT 5.2はメンテナンス性が低下し、すべての重大度でバグ密度が増加していますが、全体的なセキュリティとブロッカーレベルの脆弱性においてわずかな改善を示しています。
- GPT-5.1 Highも80%の合格率を達成していますが、認知的複雑性が増加しています(Y軸上で高い位置)。これは、問題を解決する一方で、構造的に読みやすく維持しやすいロジックを生成していることを示しています。
エンジニアリングの規律と信頼性
モデルは強力な論理能力を示していますが、私たちの分析は、リソース管理やスレッドセーフティなどのソフトウェアエンジニアリングの基本をどのように扱うかにおいて明確なパターンを明らかにしています。これらの数値を文脈化することで、同様の合格率を持つモデル間で信頼性に大きな格差があることが明らかになります。
1. 同時実行の課題: GPT-5.2 Highは強力な推論を示していますが、同時実行エラーが他のモデルよりも多く発生しやすいです。MLOCあたり470の同時実行問題を生成しており、次に近いモデルのほぼ2倍、Gemini 3 Proの6倍以上の率です。
2. リソース管理: Claude Sonnet 4.5は、MLOCあたり195のリソース管理リークを生成し、より高い率を示しました。比較すると、GPT-5.1 Highは同じタスクでMLOCあたり51のリークを生成しました。
3. 制御フロープレシジョン: Gemini 3 Proは制御フローミスの最高率(MLOCあたり200)を記録し、Opus 4.5 Thinking(MLOCあたり55)の約4倍です。GPT 5.2 Highは高い精度を示し、コホート内で最も低いエラーレートを達成し、MLOCあたりわずか22の制御フローミスを記録しました。
セキュリティ検証
セキュリティは検証のための重要な領域です。私たちの分析は、モデルが信頼できないユーザー入力をソースからシンクまで常に確実に追跡するわけではないことを確認しています。
Claude Sonnet 4.5は、パストラバーサルやインジェクションの欠陥を含むMLOCあたり198のブロッカー重大度の脆弱性を登録しました。この率は同クラスの他のモデルよりも高いです。Opus 4.5 ThinkingはMLOCあたり44のブロッカーで大幅に優れたパフォーマンスを示し、その「思考」プロセスが出力を生成する前にセキュリティ制約の検証を改善する可能性があることを示唆しています。GPT 5.2 Highは、MLOCあたり16のブロッカー脆弱性でコホート内で最も優れたセキュリティ姿勢を達成しました。他の指標ではこのモデルがコード量と一般的なバグ密度に苦労していることを示していますが、重要なセキュリティホットスポットの処理においては現在最高クラスです。
メンテナンス性の課題
重大なバグを超えて、メンテナンス性はAIコードの総所有コストにおける主要な要因であり続けます。「コードの臭い」問題はメンテナンス性を低下させ、評価されたモデル全体で検出された問題の92%から96%を占めています。
GPT-5.1 HighはMLOCあたり4,400以上の一般的な臭いを生成しました。
Claude Sonnet 4.5はより多くの設計ベストプラクティスを回避しました。
Sonar LLMリーダーボードについて
私たちはSonar LLMリーダーボードを作成し、モデルがコードをどのように構築するかだけでなく、何を構築するかについての透明性を提供しています。数千のAI生成ソリューションをSonarQubeを通じて実行することで、エンジニアリングリーダーにとって重要な指標でモデルを評価しています: セキュリティ、信頼性、メンテナンス性、複雑性。
Sonar LLMリーダーボードで完全なデータセットを探索してください。