
Fomente la confianza en sus modelos de codificación
Elimine de forma proactiva los fallos sistémicos de los datos de entrenamiento para entrenar modelos fundamentales que sean seguros desde el diseño.
Los modelos de lenguaje a gran escala son potentes, pero heredan los defectos de sus datos de entrenamiento. SonarSweep es un servicio diseñado para corregir, proteger y optimizar los conjuntos de datos de codificación utilizados en el preentrenamiento y el postentrenamiento de los modelos.

La calidad del código generado por IA está ligada a la calidad de los datos con los que se entrenaron los LLM. Las investigaciones demuestran que incluso una pequeña cantidad de datos de mala calidad puede «contaminar» de forma desproporcionada un modelo, lo que le lleva a generar código defectuoso e inseguro.
Los vastos conjuntos de datos públicos, que constituyen la base de la mayoría de los LLM, son una mezcla caótica de código de buena calidad y fragmentos plagados de errores y vulnerabilidades de seguridad.
Durante el entrenamiento, el LLM interioriza estos patrones defectuosos, incapaz de distinguir el código bueno del malo. Aprende a replicar los mismos errores que se le enseñaron.
A su vez, los LLM reproducen errores y vulnerabilidades al generar código, lo que puede acabar en el producto y requiere una verificación rigurosa.
La IA generativa está transformando la forma en que programamos, pero los LLM tienen una limitación crítica: a menudo producen código con errores ocultos, fallos de seguridad y deuda de mantenimiento. Para los proveedores de LLM y las empresas que requieren un estándar de calidad más alto, existe una clara necesidad de ajustar y personalizar los modelos. SonarSweep proporciona la capa esencial de calidad de datos para:

Crear modelos seguros y fiables desde el diseño mejorando los datos de entrenamiento en el origen, lo que proporciona a sus clientes una ventaja competitiva en el mercado.

Desarrollar modelos personalizados con confianza en entornos privados, ayudando a sus clientes a cumplir estrictos requisitos de cumplimiento normativo y a proteger la propiedad intelectual sensible.
Crear modelos de lenguaje pequeños (SLM) de alto rendimiento y rentables para flujos de trabajo agenciales especializados en plataformas como Databricks e IBM.

Consigue un rendimiento de vanguardia sin salirse del presupuesto optimizando los conjuntos de datos de entrenamiento para construir modelos más potentes con menos datos y recursos de computación.


SonarSweep analiza y corrige automáticamente miles de errores, vulnerabilidades y problemas de calidad del código dentro del conjunto de datos de entrenamiento a gran escala.

Se aplica un estricto proceso de filtrado para eliminar el código de baja calidad. A continuación, el conjunto de datos refinado se equilibra para garantizar un aprendizaje diverso y representativo que permita obtener capacidades sólidas del modelo.

El conjunto de datos final, «limpio», es un activo optimizado y de alta calidad listo para el entrenamiento del modelo, lo que produce una mejora significativa en la calidad del código generado.
Elimine de forma proactiva los fallos sistémicos de los datos de entrenamiento para entrenar modelos fundamentales que sean seguros desde el diseño.
SonarSweep aprovecha los motores de análisis de código líderes en el sector de Sonar para procesar automáticamente grandes volúmenes de código de entrenamiento, corregir problemas y transformar datos defectuosos en ejemplos de entrenamiento de alta calidad.

Al corregir el código en lugar de eliminarlo, conservamos valiosos ejemplos de aprendizaje para el modelo, mejorando su comprensión de patrones complejos.

Nuestro motor convierte los ejemplos defectuosos en buenos, elevando sistemáticamente la calidad general y la postura de seguridad de todo el conjunto de datos.

Impulsado por el mismo análisis en el que confían más de 7 millones de desarrolladores para proteger 700 000 millones de líneas de código en todo el mundo.
SonarSweep ya está disponible en acceso anticipado. Asóciate con Sonar para ser de los primeros en crear la próxima generación de modelos de codificación seguros, fiables y protegidos.
4.6 / 5
SonarSweep is a product from Sonar that remediates, secures, and optimizes coding datasets used to train AI language models. It is designed for AI companies and model builders — not for software development teams managing their own codebases.
Coding LLMs are typically trained on large volumes of publicly available open-source code, which frequently contains bugs, security vulnerabilities, and poor patterns. Models learn from these flawed examples and reproduce — and in many cases amplify — those flaws in the code they generate. SonarSweep addresses this at the root by cleaning and improving the training data before it is used to train or fine-tune a model.
SonarSweep shares its underlying code analysis engines with SonarQube and SonarQube Cloud, but it is a completely separate service and does not integrate with either product. It is not an add-on, extension, or feature of any SonarQube edition.
Where SonarQube and SonarQube Cloud help development teams detect quality and security issues in their own application code during development and CI/CD, SonarSweep processes large code datasets that AI companies use to train models. The relationship is a shared technological foundation — Sonar's analysis engines — applied to an entirely different use case and a different customer.
Coding LLMs are pre-trained on raw public open-source code — code that's full of bugs, vulnerabilities, and poor patterns. Models don't just absorb these flaws; they amplify them in everything they generate. SonarSweep fixes this at the source by cleaning training data before a model ever sees it.
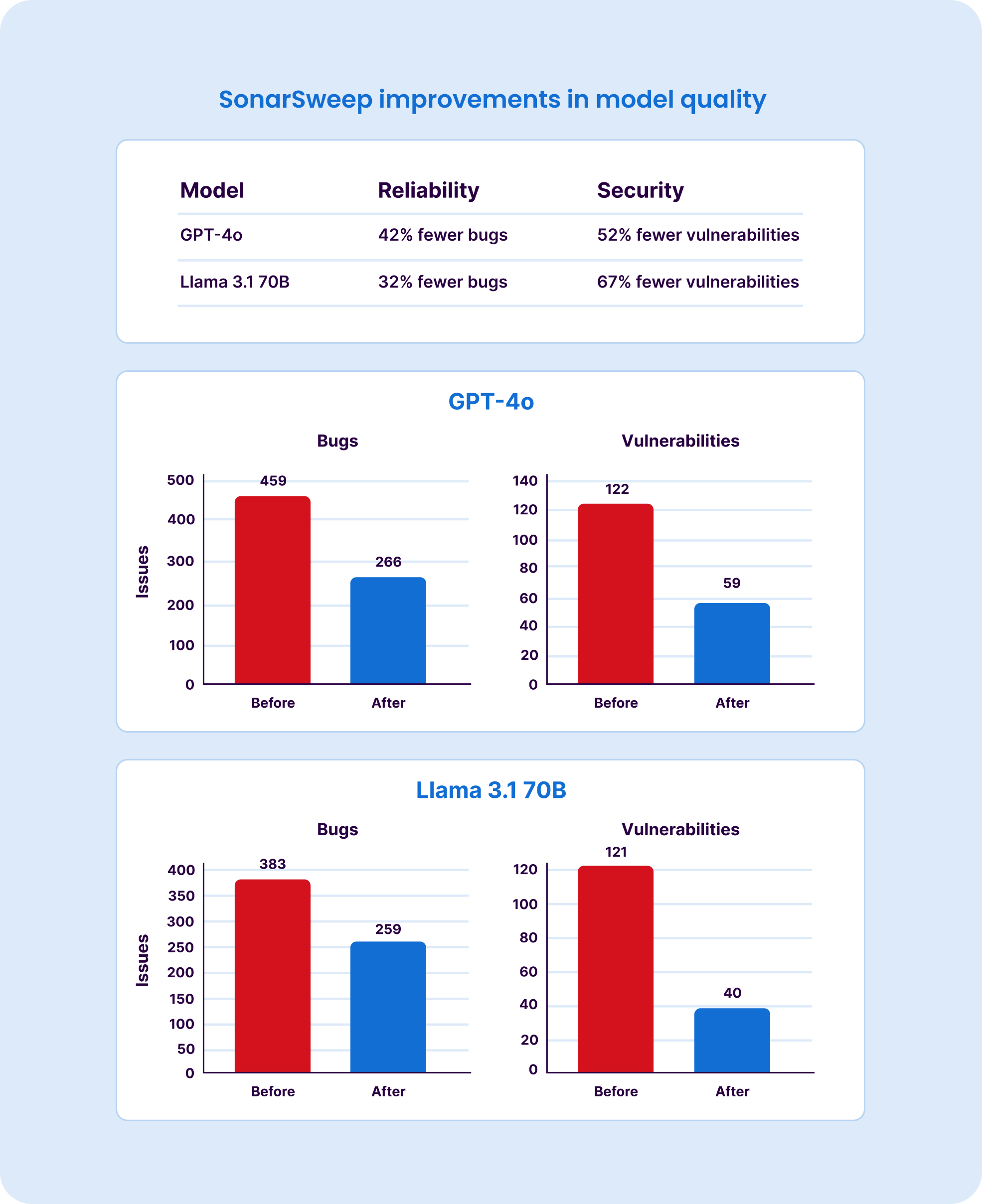
It reduces security vulnerabilities in model output by up to 67% and cuts bugs by up to 42%. It also handles a subtler problem: naively removing flawed code can skew language distribution in a dataset, so SonarSweep rebalances after cleaning to preserve model proficiency across all languages. And by addressing quality upfront, it eliminates the need for costly post-training correction passes.
SonarQube for IDE (formerly SonarLint) is a developer productivity tool that runs inside editors like VS Code, IntelliJ, and Eclipse, giving individual developers real-time feedback on quality and security issues as they write code. It operates at the developer level, in the IDE, during active development.
SonarSweep is not a developer tool at all. It is a data processing service for AI companies that are training or fine-tuning coding LLMs. It does not run in an IDE, does not provide feedback to developers, and is not part of a development workflow.
Yes — this is the core purpose of SonarSweep. The quality of code a language model generates is directly shaped by the quality of the data it trained on. A model that learned from code full of vulnerabilities and bugs will reproduce those patterns at scale. SonarSweep intervenes at the data stage, before training, to raise the quality floor of what the model learns from.
Models trained on SonarSweep-prepared datasets have demonstrated up to 67% fewer security vulnerabilities and up to 42% fewer bugs in their generated code compared to models trained on unswept data — with no degradation in functional performance. This was validated on the GPT-OSS-20B model.
SonarSweep supports 35+ programming languages, drawing on the full breadth of Sonar's code analysis engines — the same engines that power SonarQube and SonarQube Cloud.
In the context of LLM training data, this means SonarSweep can analyze, filter, and remediate code across all the languages that typically appear in large public code datasets: common back-end languages, front-end languages, scripting languages, systems languages, and more. Across these languages, it can identify and automatically fix over 6,700 distinct types of quality and security issues.
SonarSweep doesn't produce code changes for developers to review in pull requests. It processes and delivers cleaned training datasets to AI companies. Governance in this context sits with the AI team — validating dataset quality and model output before using the swept data in a training run.
No. SonarSweep has no connection to any SonarQube edition. It is a separate product for companies building or fine-tuning coding LLMs — not a feature unlocked through any SonarQube subscription tier.
The ROI is for AI companies, not development teams. Models trained on SonarSweep-processed data produce up to 67% fewer security vulnerabilities and up to 42% fewer bugs — with no loss in functional performance. It also reduces training cost by addressing data quality upfront, eliminating expensive post-training correction cycles.