

TL;DR overview
- Loop engineering is the system-building craft of managing autonomous AI coding agents, where the most critical and frequently underbuilt component is code verification.
- Robust code verification relies on a two-tier stop condition that prevents a premature-completion loop from shipping low-quality or half-done work.
- An LLM verifier sub-agent provides an initial probabilistic critique of intent and semantics, but it should not act as the final gate.
- A deterministic code verification tier serves as the ultimate hard halt, enforcing reproducible security, quality, and maintainability gates at loop speed — and is what converts an open-ended loop into a bounded, cost-controlled one.
Coding with AI has evolved. We've moved from prompt engineering, that is, writing instructions and reviewing results to loop engineering, that is, building autonomous systems that find work, delegate it to agents, review outcomes, and decide what's next. Addy Osmani has written the long-form case for it; Boris Cherny, who leads Claude Code, has put it bluntly: his job now is to write loops. The leverage moved one floor up, from typing prompts to designing the system that prompts.
The mechanics of that system are getting well documented — schedules and triggers, git worktrees for parallel runs, skills that store project knowledge, MCP connectors, a state file so the agent resumes instead of restarting, sub-agents that split the work. All of it is real and useful. Strip a loop down to its essential parts, and one node decides whether the rest of it matters is called code verification. The check that can fail the work without you in the room. Everything else is motion; verification is what makes the motion mean something.
This is the part of loop engineering worth getting right, because it’s the part most loops get wrong.
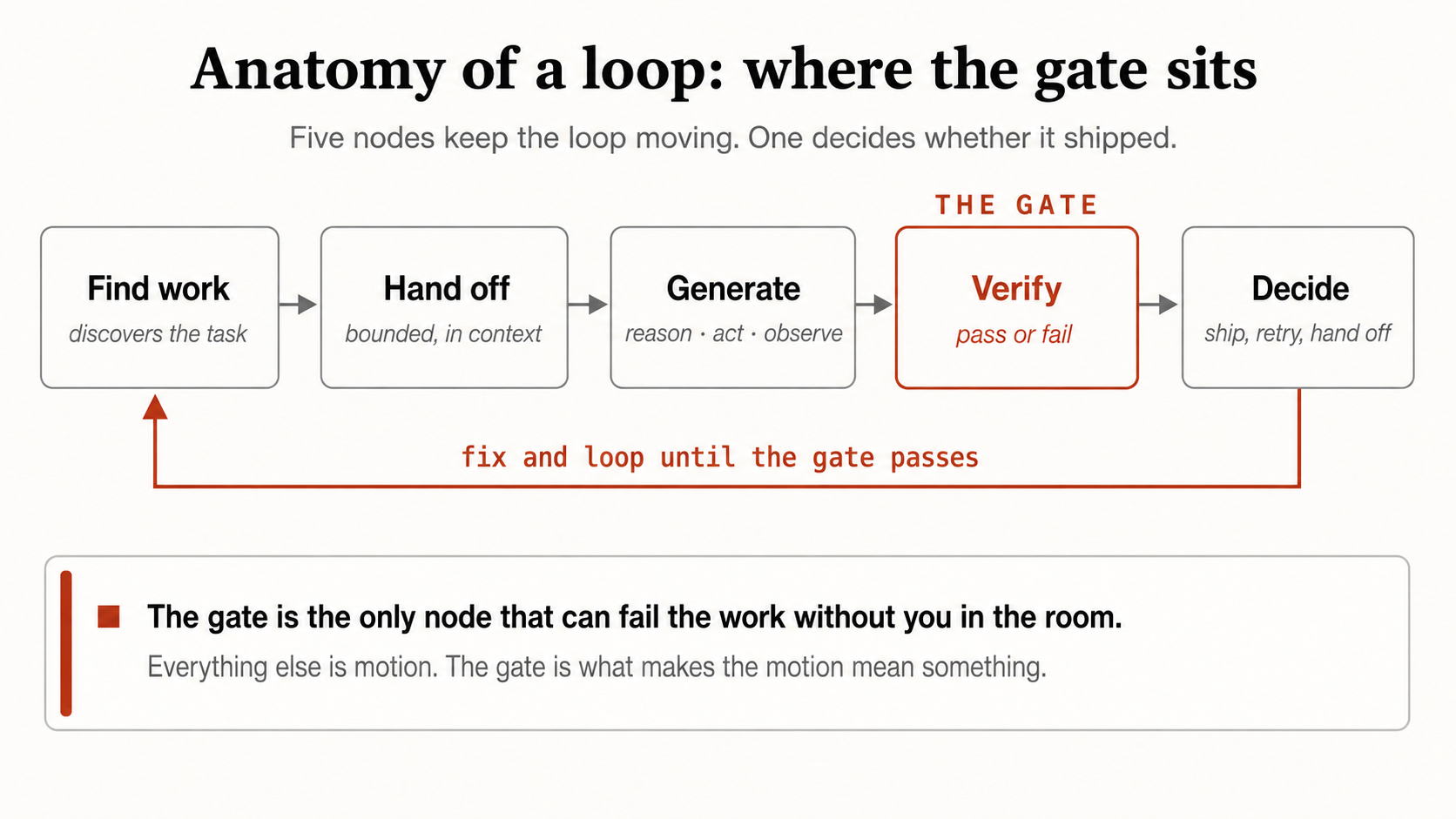
Why verification is load-bearing
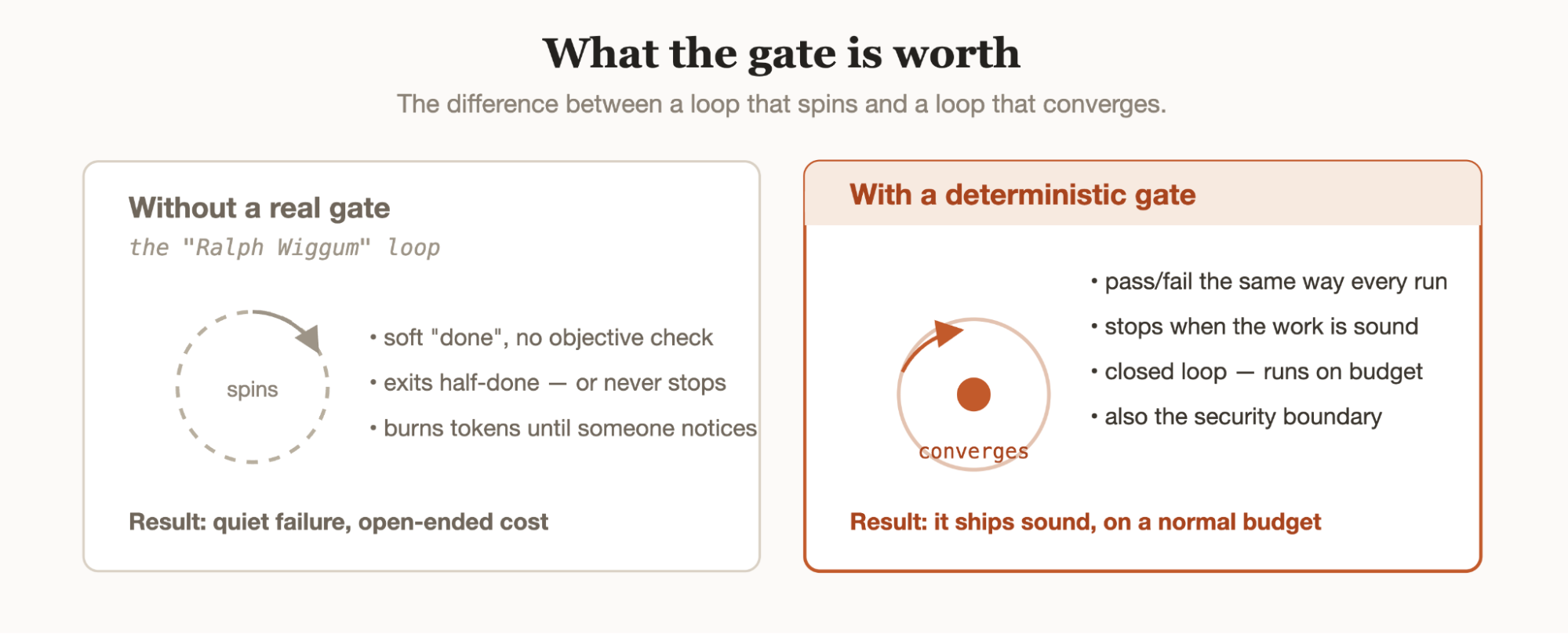
There is a specific failure mode in loop engineering: the premature-completion loop, where an agent signals completion on a half-done job. Without a hard, objective stop condition, a loop doesn’t fail loudly, it fails quietly, declaring success on work that isn’t done, and keeps spending while it does. The informal version of the same warning is everywhere now: point an open-ended loop at a loose standard and it becomes a slop machine.
The reason this happens is structural, not a quirk of any one model. A loop’s stop condition is usually some judgment of “is this done and correct?” If that judgment comes from the same model that did the work or from a second model asked politely to “review” — you have two optimists agreeing. This is the old maker-versus-checker principle, or Anthropic’s evaluator-optimizer pattern from late 2024, resurfacing as the central design question of autonomous loops: who, or what, is allowed to say the loop is finished?
Get that wrong and the loop’s other virtues turn against you. More automation means more unreviewed output. Parallel sub-agents mean more code merged faster than anyone reads it. A bigger context window and a longer schedule mean the agent runs further before anything checks it. The gate is the one component whose quality determines whether all that throughput is leverage or liability.
Closed loops are cheaper loops
One more thing the code verification buys you, and it’s a budget line. The open-ended, exploratory loop is the exciting end of this space and also the expensive one; it burns tokens with abandon, which is why it reads as obvious to people with unmetered budgets and reckless to everyone else. The bounded, closed loop runs on a normal budget because the path is tight.
What tightens the path is a trustworthy gate. A loop that can reliably tell “done and correct” from “done” converges; it stops at the right moment instead of spinning. A good code verifier isn’t only a quality control. It’s the mechanism that turns an open loop into a closed one, which is the difference between a research toy and something you can afford to run every night.
The split nobody resolves
Here the canon divides, and the division is worth taking seriously because both sides are right about different things.
One camp says the gate should be an LLM verifier sub-agent: a second agent, with different instructions and ideally a different model, grading in an independent context window. There's good evidence this outperforms self-critique, separating the grader's context from the maker's removes the most obvious source of correlated bias, and it's flexible enough to judge things no automated test encodes ("does this actually solve the user's problem?"). AI verification brings intent-awareness that rules-based systems simply don't have.
The other camp says an LLM reviewer is still a probabilistic judgment, and for security, correctness, and conformance you need objective code verification: a test, a type check, a build, a static analyzer, something that returns pass or fail identically on every run, traceable to a specific rule. The distinction Osmani draws is useful: a check that can fail the work, not a verifier that has an opinion. A failing build is a fact; an opinion is a starting point.
The productive framing isn't choosing between them but it's recognizing they answer different questions and stacking them accordingly. Sonar's AC/DC framework is built around exactly this principle: multiple verification layers, each doing what it's best at. Context Augmentation (Guide) injects architectural awareness, project-specific coding guidelines, and semantic navigation into the agent before it writes making AI verification smarter from the start. Agentic Analysis (Verify) then runs full CI-level deterministic analysis on generated code, restoring the same dependency and type context a normal CI scan uses, so findings are precise and rule-backed. The Remediation Agent and AI CodeFix then close the loop on what the Verify layer surfaces.
The result is verification that's both intelligent and objective: AI layers handle intent and context; deterministic layers handle correctness and conformance. A durable loop for autonomous work needs both.

Put the probabilistic checker first, where its judgment about intent adds value. Put the deterministic gate last, as the thing the loop actually stops on. The LLM verifier improves the draft; the deterministic gate decides whether the draft ships. A loop that has only the first tier is the Ralph Wiggum loop with extra steps.
What the deterministic tier has to do
The objection to deterministic gates inside a loop has always been latency and depth. A unit test is fast but shallow; a full static-analysis pass with real type and dependency context is deep but slow, and minutes of latency break an agent’s inner loop. So teams settle for “tests pass” as the gate, which is exactly the soft condition Huntley warned about, because passing tests is silent on whether the code is secure, maintainable, or even comprehensible.
The deterministic tier needs to run at CI-grade precision but at loop speed, and it needs to check the things tests don't: injection and taint paths, cognitive complexity. This is the Verify stage of Sonar's AC/DC framework and what SonarQube Agentic Analysis is built to deliver. It reuses the context from a prior CI analysis and restores it on demand, so a single- or multi-file check runs with full CI fidelity in seconds rather than minutes. Wired into the agent's runtime via the SonarQube plugin for Claude Code, that is a PostToolUse hook fires analysis after each file edit — the Verify step lands inside the loop instead of after it.
The payoff for loop design is that this gives /goal style stop conditions something real to resolve against. “Keep going until the goal holds” is only as good as the definition of holds. A passing quality gate, no new blocker issues on changed code, security and maintainability thresholds met is a stop condition the agent cannot satisfy by writing a confident summary. It’s the hard halt the loop was missing.
Verification is also the security boundary
There’s a second reason the deterministic tier matters, and the loop-engineering writing is candid about it: an unattended loop is an unattended attack surface. A loop that opens pull requests faster than a human can read them will merge insecure code automatically unless the gate includes security checks — SAST, dependency auditing, secret scanning. Skills pulled from the community can carry prompt injection in their descriptions; credentials leak into logs nobody is watching; permission scope quietly creeps.
This is the same gate, doing double duty. The deterministic node that keeps the loop from shipping slop is also the one that keeps it from shipping vulnerabilities: static analysis for injection and taint classes, software composition analysis for dependency and supply-chain risk, and secret scanning before content ever reaches the model’s context (the SonarQube plugin scrubs over 450 secret patterns at that boundary). For an autonomous loop, “verified” has to mean secure, not just green and only a deterministic, security-aware gate can make that claim the same way twice.
Build the code verification, stay the engineer
Loop engineering is the right frame for the Fable 5 era. Models built for long, self-correcting, multi-day runs, make the loop the unit of work, and they make the stop condition the most important thing you design. The canon already knows this; it just hasn’t fully resolved that the answer is two tiers, not one. An independent LLM verifier is a real improvement over self-critique. It is not a gate. The gate is the deterministic, security-aware check the loop halts on, and it’s the part you build last and trust most.
The honest caveat the loop-engineering writers keep raising belongs here too: the faster a loop ships code no human has read, the larger the comprehension debt the team carries. A deterministic gate doesn’t erase that debt, but it’s the one durable, independent record of whether what shipped was sound. Build the loop, by all means. Just remember that the loop is only as good as the thing allowed to tell it “no.”