

요약
- Sonar Vortex with semantic code navigation lowers coding agent costs by mapping structural code relationships instead of text-searching through source code.
- The new graph navigation engine eliminates expensive grep and read tool-call storms, reducing token usage cost by up to 36%.
- This framework ensures complete agentic coding solutions, preventing silent bugs by capturing invisible structural dependencies.
We recently released a new navigation engine as part of Sonar Vortex, the unified product that combines Sonar Context Augmentation and SonarQube Agentic Analysis that were previously in beta. Access to these capabilities is through the SonarQube CLI and SonarQube MCP Server. The graph navigation engine keeps a live, always-current map of the code across Java, Python, JavaScript and TypeScript, C#, and Rust. Instead of hunting through the code file by file with text-search tools like grep, the agent asks direct questions to the map about how the code fits together. A text search matches characters in files. The engine understands the structure of your code and answers questions about it directly: what implements this interface, what calls this method, what is the type hierarchy of this class, and what references this symbol. The agent does not just locate the code, it navigates and understands the relationships within it.
The engine delivers two things:
- Lower AI usage cost: The agent stops doing tool-call read storms, because a single structural query returns the complete set of places to change instead of forcing the agent to grep, read, and reconstruct that set by hand.
- A more complete solution: The same exhaustive enumeration makes the agent less likely to miss a location that must change, including the locations a text search never surfaces.
This article measures the first, usage cost, in detail, and explains the second, complete solution, along the way.
In short, our research found six usage cost wins across Java, Python, TypeScript, and C#, with up to 36% reduced token consumption and cost per run, on a specific and recognizable shape of refactoring work. The navigation engine will not help on tasks where navigation is not the constraint. If the agent is already working from sufficient context, or the task does not require traversing code structure, the engine has nothing to accelerate. We measured specific refactoring work tasks where the usage cost stayed within a few percent of the baseline. This article explains what the engine does, how we measured it, and where it wins when compared to not using Sonar Context Augmentation.
How coding agents navigate code today
When a software developer gives a coding agent a task, they describe what it should do, but do not include the file and line of where every change should be made. That is the normal way to work, and it means the agent arrives without a map. Discovering where the code has to change is its job, not the prompt's. So it builds that map by hand: grep a name, read the files that come back, infer the relationships, grep the next name, read more, and repeat until it believes it has the full picture. Grep, find, and read are the only tools it has, and none of these tools understand the code, so the agent has to assemble that understanding itself, one file at a time.
Every file the agent reads to build that map stays resident in the conversation context for the rest of the run, because the agent keeps file contents around to reason over and to edit. This is important because: agent usage cost is roughly the number of turns multiplied by the resident context carried on each turn. Everything that makes a run expensive reduces to either more turns or more context carried every turn.
The consequence is that token usage cost is compounded by two factors from a tool-call read storm. It adds turns: each grep, each read, each inference is a turn. Plus it raises the resident-context floor for the rest of the run. Every file opened stays in context and is re-read on every subsequent turn. A structural question that the agent can only approximate by matching names and then reading to sort signal from noise is exactly the kind of question that produces this compounded cost.
Where grep and find fall short in code navigation
It is worth being fair to grep first, because in the right use cases, it is often the right tool. For text search it is fast, it needs no index, and it works on any repository in any language the instant the agent arrives. When a name produces roughly as many hits as there are real sites to change (a noise ratio near one to one), grep lands directly on the answer and there is nothing to improve. A large number of sites to change does not by itself create a problem. What creates a problem is when text search cannot cheaply enumerate the set.
Where grep falls short is that it matches only characters, not coding relationships. It cannot answer a structural question. It can only approximate it by name.
Grep breaks down in three distinct ways:
- The noise flood: The name you search for really does appear at every place in the code you need to change, but it also appears at many places you do not, so the matches are mostly chaff. The agent cannot immediately tell which hits are the correct ones from the text of the match alone. It opens and reads file after file to separate the real sites from the rest, and every file it opens stays in context for the rest of the run. The cost is not in the search itself, it is in reading and retaining the files the search forces. We measured exactly this on one task. A grep on the relevant type name returned about 461 hits against only 16 real edit sites, a noise ratio of roughly 29 to 1.
- The invisible site: Here the location in the code that must change shares no text with the thing the agent searched for, so the search never surfaces the correct location at all. This happens whenever the connection between two pieces of code is structural rather than textual. A class can implement an interface without ever naming it on the lines that need editing. A method can be called indirectly, through a layer that hides the name, so the call site reads nothing like the method. In all of these cases the relationship is real and the text is invisible. So a grep-driven agent either misses the site or has to reconstruct the relationship by reading, which puts it right back in the noise flood. An engine that understands the structure returns these sites directly without having to reconstruct the relationship.
- The false match: Here the text matches, but it points at the wrong thing, because the same name can mean different things in different places and a text search has no way to tell them apart. Two methods can share a name through overloading while taking different arguments, so only one of them is the one you mean. A local variable can shadow a field, or the same identifier can name unrelated symbols in different classes, namespaces, or scopes. The agent gets a list of hits that all look alike and cannot tell from the text which ones are the symbol it cares about, so it either edits the wrong site, which is a bug, or reads each candidate to rule it out, which puts it right back in the noise flood. Telling these apart is a question about identity, not characters, and it is what a structural engine answers directly: it returns the references to the one symbol you mean and leaves its namesakes alone.
The invisible site is not only a usage cost problem, it is a correctness problem, and that is where the second benefit of the engine comes in. In a rename with no backward-compatible aliases, a missed site simply fails to compile, which is loud and caught by a build gate. But in a signature or behavior change reached indirectly, a missed location often still compiles and then misbehaves at runtime. The test suite may not exercise that path, so it ships as a silent bug. An exhaustive structural enumeration is the difference between catching that location and shipping the bug. This is the completeness benefit, and it is why an engine that understands relationships is worth more than a quick grep.
How our graph navigation engine solves the grep problem
The engine maintains a single in-memory graph of the code that spans every supported programming language and updates as you edit. Nodes are the things in your code: modules, classes, interfaces, enums, records and structs, methods and functions, fields, parameters, and annotations. Edges are the relationships between them: this method calls that one, this class implements that interface, this type extends that one, this symbol references that one. Every node and every edge carries its file path and line location, which is what lets a query hand back exact edit locations rather than names to go look up.
How the graph is built
The graph is built without a compiler, a linter, a language server, or a network call. The engine reads each source file directly and links references across files into a project-wide call graph, which is what lets it work on code that does not yet compile. The cross-file linking is shared across programming languages and only the per-file reading is language-specific, so the engine answers the same structural queries across every language it supports.
Built for the agent's inner loop
What matters in the agent's inner loop, where the code is often mid-edit and is not being compiled, is speed and availability. Full graph generation for about 1,000 source files takes a few seconds and runs once at startup. It runs again to refresh the graph in about a millisecond after each code edit, fast enough that the agent never waits on it. That work is a local computation running in-process next to the agent, not billed model turns. So it does not enter the model-usage cost this article measures and does not consume tokens. Because it does not depend on a compiler, it parses any syntactically plausible file, so the graph is available throughout code generation, not only when the code compiles. It runs locally, with no compilation step, no language server, and no network call. The engine re-scans changed files on demand to always stay current.
A small trade-off of type-resolution precision is given up against a compiler or a language server in exchange for availability and freshness, which are the properties that matter most when the agent is mid-edit. It identifies the symbols in the code very accurately. However, it is less precise about every edge between them, because it approximates call targets from the calling code rather than fully resolving types the way a compiler would. In practice that means it is excellent at enumerating the members of a hierarchy or the declarations of a symbol. Additionally, it is good but not perfect at tracing every call edge, which is exactly the balance the agent's inner loop needs.
What structural queries can AI agents run with graph navigation?
The engine exposes a small set of structural queries. Each resolves relationships by symbol identity rather than by text, and returns exact file and line locations:
search-signatures: find where symbols are declared, matched by name or signature pattern, so the result is the set of declarations rather than every textual mention of the name.search-bodies: find where a symbol is actually used inside method and function bodies, separating real usage sites from declarations, comments, and strings.get-source: retrieve the resolved source of a symbol by its fully qualified name, so the agent reads the exact definition it means and not a same-named lookalike.trace-callers: walk the call graph inward from a symbol, directly and transitively up the chain, to find what reaches it, including callers that share no text with it.trace-callees: walk the call graph outward, to whatever depth a task needs, to find what a symbol calls.get-type-hierarchy: resolve the full type tree of a class or interface, its supertypes, subtypes, and every implementor, transitively, including the anonymous, nested, and test types whose declaration never names it.get-references: enumerate every site that references one specific symbol, with exact line anchors, resolved to that symbol so its overloads and namesakes are not mixed in.
The engine can also return edit targets directly: a deduplicated list of {file_path, line} rows, one per affected source line. This is what decides whether the engine saves usage cost or adds it. A query that returns the right symbols but not their locations still forces the agent to grep again to find the edit points, stacking the query on top of the search instead of replacing it. Handing back the locations is what lets the agent stop re-grepping, the difference between the engine being substitutive (a cost win) and additive (a cost loss).
The study: methodology and integrity
The method compares two run groups on real software work: baseline runs (plain coding agent) and navigation runs (the same agent plus the graph navigation engine).
- Take a real merged commit from a popular open-source project as the ground truth and the runnable oracle.
- Build a prompt that describes the task by what it should do, with no file names, no symbols, and no line numbers, the way a developer actually asks. If the prompt names the files, it hands the agent the answer and measures prompt quality, not the agent's ability to navigate the code and do the work.
- Check out the parent of the commit (the before state) into a clean workspace.
- Reimplement the change twice, once baseline and once with navigation, holding the model, the effort, and the environment identical.
- Gate on build and tests: a run counts only if it compiles and the targeted tests pass, because cost is comparable only when correctness is held equal.
- Run ten times per side on Opus 4.8 at high effort with subagents on, and lead with the median.
- Use a model-as-a-judge pass to attribute each cost swing to the engine, an eval bug, or run-to-run inconsistency, and run a cheat audit on every transcript.
We deliberately ran on Opus 4.8, for two reasons. First, to show the value survives Opus, one of the strongest available models according to our leaderboard, so the result is not a crutch for a weak one. Second, to reduce noise: a smarter model wanders into fewer tangents, so its runs are less variable and a signal is easier to see. The trade-off is that the strongest model is the most expensive, so it is the model on which you can least afford a high repetition count.
The goal of a stable signal is why n equals 10. A single run is too noisy to trust: the SQLAlchemy task read as plus 92 percent (mean of two runs) at n equals 2 and resolved to a minus 20 percent mean (minus 29 percent median) at n equals 10. Ten runs per side is the minimum that pulls a stable signal out of that run-to-run noise. It is enough to establish the direction of the effect, not a precise per-task mean, which is why we lead with the median rather than the mean. Nothing here rests on a small sample.
On integrity: every run was cheat-audited, with git history stripped from each workspace, the network blocked at the host level, and the agent's own web-fetch and web-search tools disabled symmetrically on both sides, so the answer could not be recovered out of band. Correctness was held equal across both groups. These are controlled benchmark numbers from a hardened harness, not what a single casual local run looks like. A one-off comparison without the same measurement discipline is dominated by noise.
The result: six agent usage costs wins across four programming languages
The chart includes the mean and median deltas. A negative delta means the navigation runs were cheaper. Dollars are model usage per run at Opus 4.8 prices at the time of measurement.
The last two rows carry a nuance. AssertJ is a clear win on the typical run (median minus 15 percent) while its average is flat, because a multi-module Maven build dominates the cost. QuartzNET's plus 5 percent average is inflated by three heavy edit-and-build-variance runs. Its typical run is minus 20 percent, which is the fair read.
The dollar savings come from the model doing less work, not from a pricing trick. Prompt caching discounts the context an agent re-reads, but how much you benefit from that discount depends on timing and varies from one user to the next, so the clearest view sets caching aside and counts every token at face value. Counted that way, the navigation runs read fewer input tokens and generate fewer output tokens on every task:
Input is mostly the resident context the model re-reads on every turn. The navigation runs keep fewer files in play, so they read less. Because both columns fall on every task, the saving is real work avoided, and it holds whatever your caching setup. These medians are over the same n equals 10 per-run set as the headline cost table and reproduce from the data published alongside this article.
One kind of work showed up again and again in these wins: the same small, behavior-preserving change repeated across every implementation of a shared abstraction, an interface, a base class, or a protocol, where the code that changes never names the abstraction. In other words, a plain text search cannot list those places cleanly. On work like this, finding the complete set of places to edit is most of the job. The edits themselves are mechanical and nearly identical, and a single structural query hands back the whole list in one call. That is where the engine helped most.
The six AI token consumption cost wins in detail
Each result below is shown as a box-and-whisker chart. Baseline runs are on the left and navigation runs are on the right, with n equals 10 per side. The box is the spread, every run is a point, and the diamond marks the mean.
1. BloomFilter self-typing (Java): minus 36 percent.
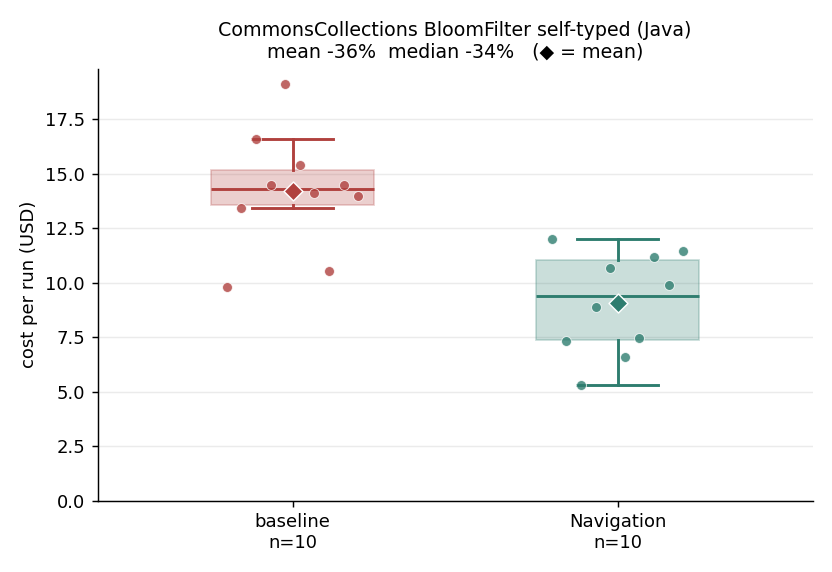
Baseline mean $14.20 / median $14.29; navigation mean $9.07 / median $9.38 (mean minus 36 percent, median minus 34 percent). There are 16 places to change, but a grep on the type name returns about 461 hits, a noise ratio of roughly 29 to 1. This is the clearest example of the pattern above, and the worked case behind the noise-flood numbers earlier: a high noise ratio, a question grep cannot answer (the type hierarchy), and the model trusting the structural answer instead of searching by text. The 16 implementors are not text-matchable, because many are anonymous, nested, or test subclasses whose declaration never names the interface near the code that changes. get-type-hierarchy enumerates all 16 and get-references supplies the edit lines, so a couple of structural queries hand the agent the full edit set directly and the read storm never happens. This is the most defensible win in the set: almost every navigation run came in below the baseline, not just the average. The win caps at 36 percent because the residual cost is the generics edit churn (edit, recompile, fix), which the engine cannot remove. Subagents not used. Every counted run passed the build and tests. About 13 files and 126 lines added in a typical run.
2. BloomFilter package rename (Java): minus 20 percent.
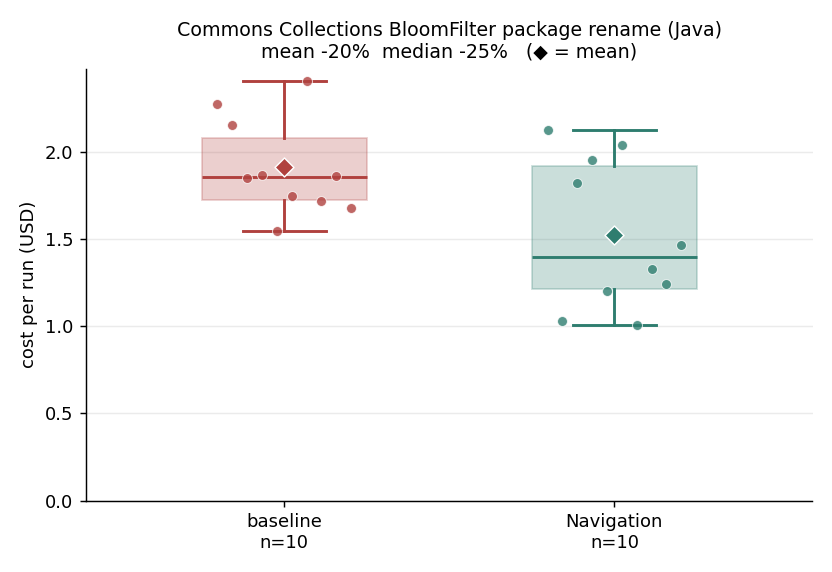
Baseline mean $1.91 / median $1.86; navigation mean $1.52 / median $1.40 (mean minus 20 percent, median minus 25 percent). The same family as the first task but lighter: search-signatures and get-references enumerate every reference site, including the test suite and the Javadoc references that grep mixes up with confusable near-miss names, so the model renames the right set in one pass. The absolute saving is small (about 39 cents per run), because a rename is cheap for both groups with no compile-churn tail. It is useful as corroboration that the mechanism is the refactor shape, not a one-off. Subagents not used (0 of 10). Tests 10 of 10 both groups. About 61 files and 638 lines added in a typical run.
3. SQLAlchemy compiler keyword arguments (Python): minus 20 percent.
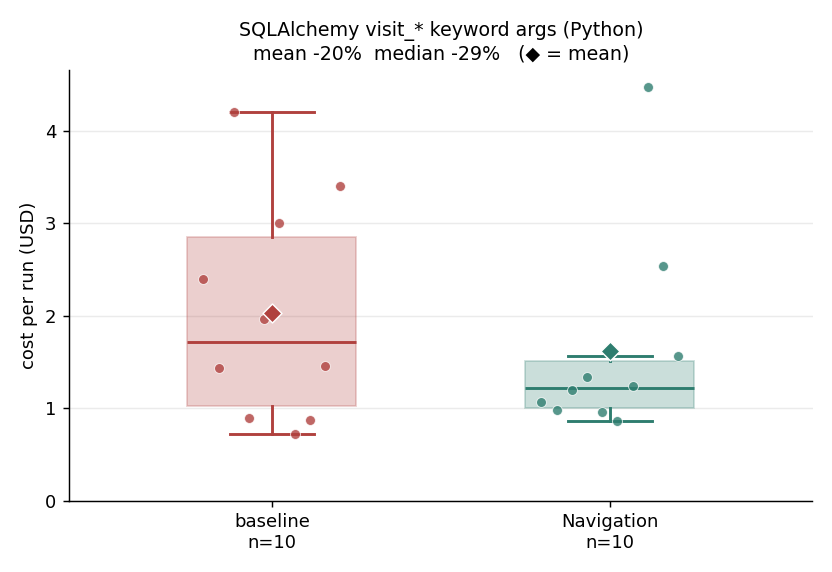
Baseline mean $2.03 / median $1.71; navigation mean $1.62 / median $1.22 (mean minus 20 percent, median minus 29 percent). The cleanest Python example. There are 47 override sites against about 1,152 grep hits, a noise ratio of roughly 24 to 1. The override sites are def visit_<construct> lines spread across the backend dialect compiler files, and none of them name the base compiler, so a search for def visit_ returns over a thousand matches of which only a specific subset must change. The navigation runs leaned on search-signatures (25 times across the group), get-type-hierarchy (4), and get-source (4). This task read as plus 92 percent at n equals 2 (in one of the two runs the model never engaged the engine and brute-forced the change) and resolved to a clear win on both the mean and the median at n equals 10, which is the clearest single demonstration that single-run cost is noise. Subagents not used (0 of 10). Tests 10 of 10 both groups. About 5 files and 41 lines added in a typical run.
4. TanStack Query mutation context (TypeScript): minus 5 percent.
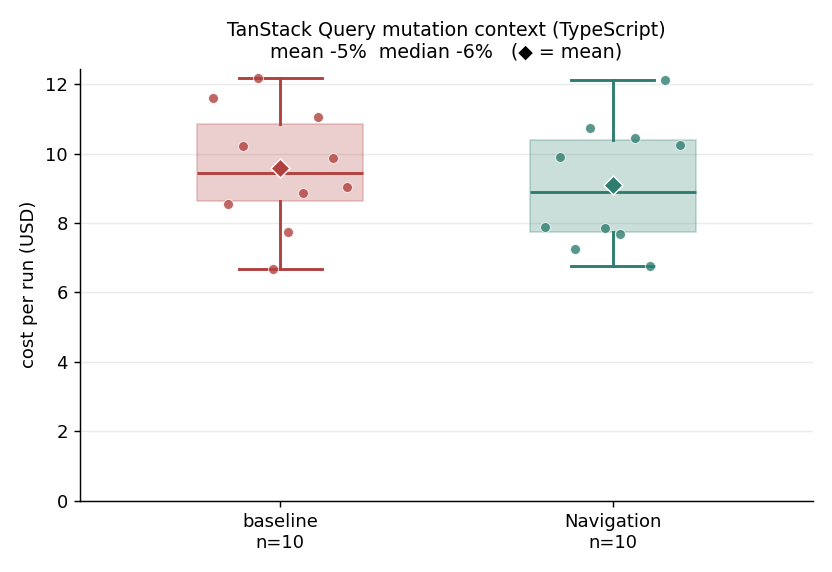
Baseline mean $9.58 / median $9.45; navigation mean $9.09 / median $8.89 (mean minus 5 percent, median minus 6 percent). TypeScript has a thinner symbol graph than Java, yet the pattern still holds: one signature flows to a fixed, scattered set of call sites the model must find completely. search-bodies (7) and trace-callers (2) pointed at the call sites directly so the model edited them without a re-grep loop. The win is real but modest, because the dominant cost is the npm and tsc build loop that the engine cannot move. Subagents used in 5 of 10 navigation runs. Every counted run passed the build and tests. About 27 files and 397 lines added in a typical run.
5. AssertJ catchThrowableOfType argument order (Java): median minus 15 percent, mean roughly flat (minus 4 percent, within run-to-run noise).
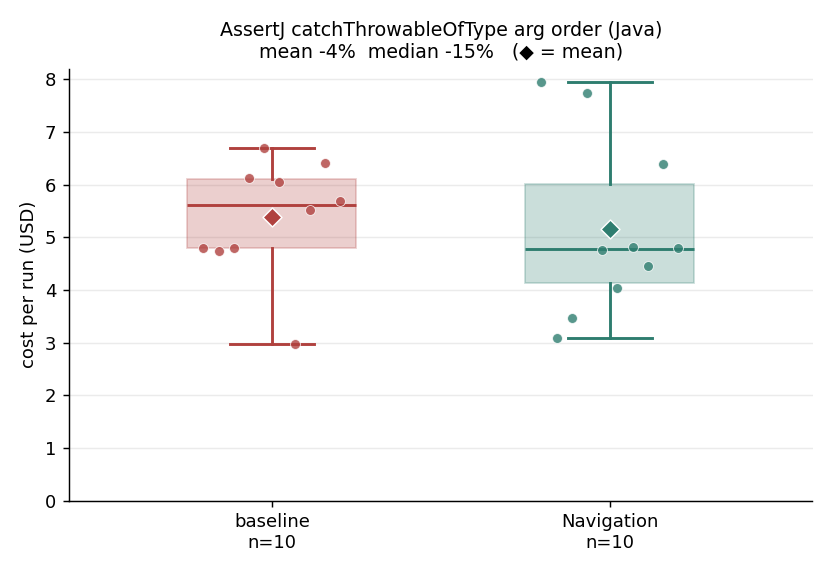
Baseline mean $5.38 / median $5.61; navigation mean $5.15 / median $4.78 (mean minus 4 percent, median minus 15 percent). There are 32 call sites against 196 grep hits, a noise ratio of about 6 to 1. The token catchThrowableOfType is greppable, so the difficulty is not locating it but distinguishing the old argument order from the new one across multi-line calls. The baseline burns 11 to 18 escalating regular expressions. The navigation search-signatures and trace-callers queries, read with get-source on the overloads, return the resolved call sites with line ranges directly, dropping the typical grep count from 11 to 3. The win shows only on the median because the dominant cost is the multi-module Maven build, which the engine cannot move, and because two of the ten navigation runs reverted to grepping and erased the gain on the average. Subagents used in 6 of 10 runs. Tests 10 of 10 both groups. About 32 files and 98 lines added in a typical run.
6. QuartzNET store and scheduler return types (C#): minus 20 percent on the typical run.
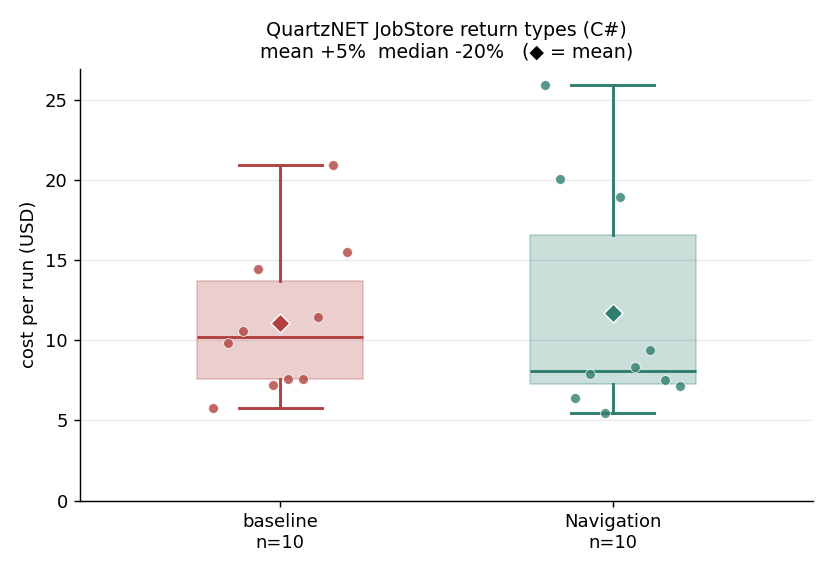
Baseline mean $11.10 / median $10.20; navigation mean $11.71 / median $8.11 (mean plus 5 percent, median minus 20 percent). This task touches 186 sites, more than any other here, against 776 grep hits, a noise ratio of about 4 to 1. The large number of edits did not translate into the largest saving. The navigation runs used search-signatures (23), get-type-hierarchy (10), and get-source (11) to enumerate the interface implementor set, and grep collapsed from about 22 calls in the baseline to 3. The median is a clear minus 20 percent win and is the fair read. The mean is the one figure that does not show it, dragged positive by three heavy runs (156 to 186 turns of solo editing, or spreading the work across many subagents) that reflect edit-and-build variance on a very large 186-site change rather than engine cost. The baseline has a right tail too, but a lighter one, so on this task the median run is clearly cheaper while navigation's worst runs are occasionally pricier than the baseline's. The median, not the average, is the summary here. Subagents used in 2 of 10 runs. Tests 10 of 10 both groups. About 24 files and 279 lines added in a typical run.
When does graph navigation reduce AI coding agent usage costs?
The refactoring shape in these examples is one place the engine helps, not the only one and not every task. Where navigating and understanding the code is not the bottleneck, for instance when a task is dominated by the sheer volume of mechanical edits or by the build-and-test loop, the engine has little to accelerate. We measured tasks like that, and the median cost stayed within a few percent of the baseline, with no penalty. Two caveats are worth stating plainly: the gain is tied to the kind of work, so it is not promised on every task, and a coding agent is noisy, so any single run can land either way. The effect is what you see in the median across repeated runs, not in a one-off comparison, which is why the study leads with the median over ten runs. Where finding the code is not the bottleneck, the engine stays out of the way rather than adding agent cost.
How much of the savings you actually get also depends on the model. The engine only helps when the agent calls it at the right moment and then trusts the result instead of re-checking it with a text search. The model runs a structural query and then ignores added cost rather than removing it. The measured wins here are on Opus 4.8. In our wider testing the same pattern held on Sonnet, while a smaller model like Haiku reached for the engine less consistently and left some easy wins unclaimed, though it still captured part of the benefit. The smarter the model, the better its judgment about when to ask a structural question and when to believe the answer, so the more consistent the gain.
Conclusion: Reduce coding agent usage costs with Sonar Vortex
The graph navigation engine reduces a coding agent's usage cost when finding and understanding the code is the real work. The refactoring tasks here are one clear example, and they share a profile you can use as a checklist: a widely implemented abstraction; implementors that text search cannot enumerate; a uniform, behavior-preserving change applied identically to every site; and discovery, rather than the build loop or the volume of edits, as the dominant cost. On tasks like these it delivered six wins across four languages, up to 36 percent cheaper per run: BloomFilter self-typing (minus 36 percent), the package rename (minus 20 percent), SQLAlchemy (minus 20 percent), TanStack (minus 5 percent), AssertJ (minus 15 percent on the typical run), and QuartzNET (minus 20 percent on the typical run, its average held up only by a few edit-and-build-variance outliers).
The effect is about the kind of task, not the language: the same wins showed up across Java, Python, TypeScript, and C#. What separated a win from a wash was not how many places needed changing, but whether a plain text search could list them cleanly. Where it could not, the engine helped. Where the work was not about finding code, it stayed out of the way, which is why it is safe to leave on.
Usage cost is only the first benefit. The second is the one the cost study keeps brushing against: because the engine enumerates the full set of structural locations, including the ones a text search never surfaces, the agent is far less likely to leave a site unchanged and ship a silent bug. An agent that understands the code, rather than one that pattern-matches text against it, is cheaper on exactly the work that is hardest to get right by hand, and, by enumerating sites a text search never surfaces, should be less likely to ship a silent bug, a benefit we argue from the mechanism rather than measure here, since correctness was held equal across both groups.
The navigation engine is available now as part of Sonar Vortex, the unified product that combines the betas of Sonar Context Augmentation and SonarQube Agentic Analysis together into a single product that manages the agents inner loop. Access to these capabilities is through the SonarQube CLI and SonarQube MCP Server integration with your coding agent or agentic IDE of choice. If your agents do this kind of work, large, uniform changes across a widely implemented abstraction where the hard part is finding every site, it is worth adding it to SonarQube.