
Author: Killian Carlsen-Phelan
TL;DR overview
- Linting is a foundational code verification process that performs per-file AST analysis to catch syntax and style issues, but lacks the inter-procedural data flow tracking needed to detect vulnerabilities like SQL injection which require tracing untrusted data across multiple files and call chains.
- SonarQube provides deep static analysis by building multi-layer models, including data flow and control flow graphs, to track how untrusted data propagates across an entire project.
- Advanced techniques like taint analysis and symbolic execution allow teams to find critical "blocker" bugs in AI-generated code that standard linters structurally miss.
Your AI coding agent just generated a Flask API with three files: a route handler that reads a username from request.args, a service module that builds a query string, and a database module that executes it. Ruff reports zero findings across all three files. The code is idiomatic Python.
SonarQube traces the username from request.args["user"] in the route handler, through the string concatenation in the service layer, into the unsanitized cursor.execute() call in the database module. SQL injection. BLOCKER severity. CWE-89.
Ruff checked each file, but SonarQube also checked the flow between them. That distinction is the subject of this article.
The consensus is right
A growing coalition of engineering teams and thought leaders has converged on the same conclusion: linting is foundational infrastructure for agentic development.
Birgitta Böckeler at Thoughtworks, writing on martinfowler.com, frames linting as a deterministic guardrail within the agent's "harness." Architectural constraints are "monitored not only by the LLM-based agents, but also deterministic custom linters and structural tests." Humans work on the loop by improving the harness, not by editing agent output directly.
Anthropic's 2026 Agentic Coding Trends Report recommends a workflow state machine where agents advance only when deterministic gates pass. Linters sit in the fast preflight stage alongside formatting, type checking, and unit tests.
Stripe's Minions system merges over a thousand minion-produced PRs per week. A local executable runs selected lints on every push in under five seconds. Factory.ai puts it bluntly: "Agents write the code; linters write the law."
Spotify's Honk agent enforces standards through monorepos with linting. MIT's Missing Semester 2026 teaches students that coding models are most effective inside a feedback loop with failing checks they can run directly.
Fast, deterministic code verification in the agent's inner loop is a prerequisite for scaling AI-assisted development. And the same reasoning that makes linting essential points toward something linters structurally cannot do.
What linters actually do
Every major linter operates on a single file's abstract syntax tree. The linter parses source code into a tree structure, walks the tree node by node, and checks each node against a set of rules. This is a deliberate design choice optimized for speed, and it works.
ESLint's architecture docs describe a Linter class that parses source text into an AST, traverses it node by node, and fires events that rules subscribe to. It’s own glossary draws the line explicitly: "Whereas linters traditionally operate only on a single file's or snippet's AST at a time, type checkers understand cross-file dependencies and types."
Ruff, the Rust-based Python linter, implements over 900 rules, including reimplementations from Flake8, Bandit, and others. Its FAQ is upfront: "Ruff is a linter, not a type checker. It can detect some of the same problems that a type checker can, but a type checker will catch certain errors that Ruff would miss." Its GitHub discussion #23734 confirms that Ruff does not perform cross-file analysis.
Checkstyle's homepage calls itself "a single file static analysis tool." PMD's internal architecture includes an optional data flow analysis step, but multi-file analysis is labeled "FUTURE" in its own documentation. Bandit, the Python security linter, processes each file by building an AST and running plugins against it. Its docs describe it as a tool that "processes each file, builds an AST from it, and runs appropriate plugins against the AST nodes."
ESLint does offer "code path analysis," which developers sometimes confuse with data flow analysis. ESLint's code path analysis builds a control flow graph and answers the question "can execution reach this line?" Data flow analysis answers a different question: "what do we know about the state of every variable when execution reaches this line?" The distinction matters for understanding what a linter can and cannot detect.
The security-focused plugins face the same structural constraint. eslint-plugin-security, which provides 14 rules, describes itself as a tool that will "help identify potential security hotspots, but finds a lot of false positives which need triage by a human." It checks function names and node patterns, not whether a value was actually sanitized through arbitrary code paths.
None of this is a criticism. These tools deliver exactly what they promise: fast, per-file style enforcement and pattern detection. And, as a matter of fact, SonarQube provides some findings based on this kind of technology. The question is what happens when the bug lives between files.
What deeper analysis looks like
SonarQube builds progressively richer models of source code. Adding more rules on the same foundation is not the same as building a deeper foundation. Each layer catches bugs the previous one can't.
Layer 1: Abstract syntax trees. This is where linters operate, and where SonarQube starts. SonarQube includes hundreds of AST-based rules, and for JavaScript and TypeScript, uses ESLint's engine directly. The difference isn't that SonarQube skips this layer; it builds additional layers on top of it. An AST check can flag eval(userInput) because the node pattern is recognizable. What it can't do is determine whether userInput actually came from a user.
Layer 2: Control flow graphs. A CFG represents every possible execution path through a single method, such as all the branches and loops. It’s still single-method analysis, but it unlocks path-sensitive reasoning that pure AST checks can’t do. Consider this:
Connection conn = null;
try {
conn = dataSource.getConnection();
} catch (SQLException e) {
logger.error("Connection failed", e);
}
conn.prepareStatement(query); // Bug: conn is null on the catch pathAn AST check sees conn declared and later used. Nothing structurally wrong. The CFG reveals two paths within this method: the normal path where conn gets reassigned, and the catch path where it stays null. On the catch path, conn.prepareStatement() throws a NullPointerException. The CFG doesn’t cross file boundaries, but it’s the foundation that makes the next layers possible.
Layer 3: Data flow graphs. Data flow analysis tracks how values propagate through the program. It answers the question the CFG can't: not just "can execution reach this line," but "what do we know about the state of every variable when execution reaches this line?" A resource opened in one method, passed through two others, and never closed on an exception path is a resource leak. Detecting it requires tracking the resource's lifecycle across assignments, branches, and function boundaries. SonarQube's java:S2095 (resources should be closed) is a data flow rule that tracks exactly this.
On top of these representations, two deeper techniques operate.
Consider a function that computes an average by counting only positive values in a loop. If all values are negative, the counter stays at zero and the final division crashes. A linter sees total / count and moves on because there's no literal zero in the code.
Symbolic execution catches this. It simulates program behavior using placeholder symbols instead of concrete values. Where a test says x = 5 and checks one path, symbolic execution says x = X and forks at every branch to explore what happens when X > 10 and when it doesn't. In the averaging function, the engine tracks count through the loop, determines its range includes zero because the increment only fires on a conditional branch, and flags the division. It reasons about each path independently, so it knows that a variable checked for null on one path is guaranteed non-null on the other. As Sonar describes it, this "makes it possible to detect problems only when they are realistically possible."
Taint analysis is the first layer in the stack that requires analyzing the entire project, not just a single file.
The practical results of this depth are measurable. SonarQube's Dataflow Bug Detection engine, which performs cross-procedural analysis for Java and Python, improved detection rates substantially when it replaced simpler rule implementations: 14x more true positives for division-by-zero detection and 113x fewer false positives for null dereference. Across 137 million distinct issues reviewed by users in 2025, SonarQube's overall false positive rate was 3.2%. Depth produces better results, and less noise.
Taint analysis across files
Back to the Flask example from the opening. Here's what the agent generated:
# routes.py
from flask import request
from services import get_user_data
@app.route('/users')
def get_users():
username = request.args["user"]
return get_user_data(username)# services.py
from db import execute_query
def get_user_data(username):
query = "SELECT * FROM users WHERE name = '" + username + "'"
return execute_query(query)# db.py
import sqlite3
def execute_query(query):
conn = sqlite3.connect('app.db')
return conn.cursor().execute(query)Ruff analyzes each file in isolation. routes.py reads a request parameter and passes it to a function. Nothing wrong with that. services.py builds a string and passes it to another function. Ruff doesn't know what username contains; it only sees a string concatenation. db.py executes a query it received as a parameter. Each file is individually clean.
SonarQube's taint engine (pythonsecurity:S3649) traces the data flow across all three files. It marks request.args["user"] as a taint source, follows username through the function call into services.py, tracks the unsanitized concatenation into the query string, follows that string through the execute_query call into db.py, and flags cursor.execute(query) as a taint sink receiving unsanitized user input. SQL injection. The fix is parameterized queries: cursor.execute("SELECT * FROM users WHERE name = ?", (username,)).
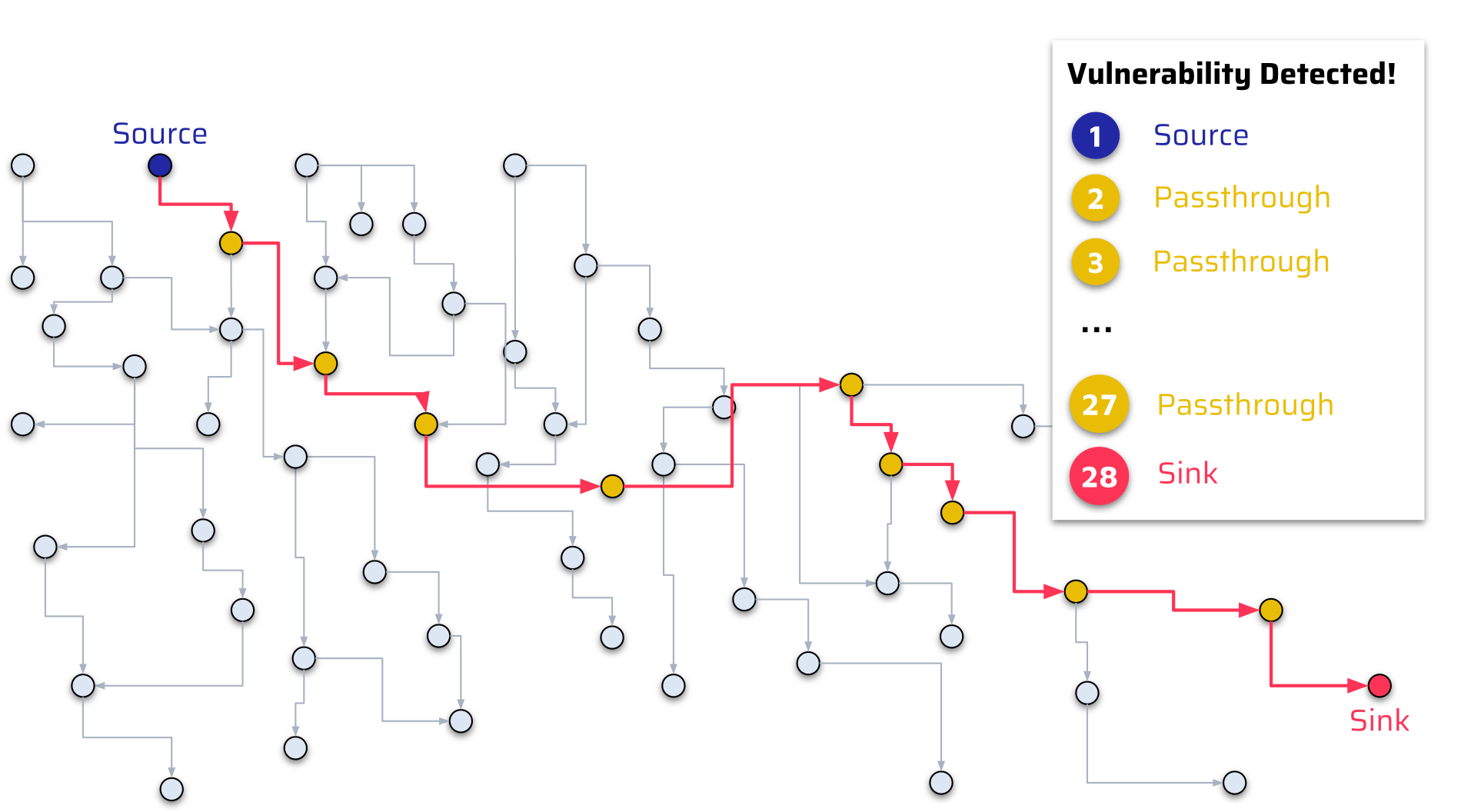
The OpenAPI Generator CVE-2024-35219 shows what this looks like at scale. SonarQube's taint engine traced a 28-step flow from source to sink across multiple classes:
- Step 1 (source): User-controlled JSON arrives via a
@RequestBodyparameter at the/gen/clients/{language}API endpoint. - Mid-chain: The attacker-controlled value is extracted through
opts.getOptions().get("outputFolder")and concatenated into a file path:getTmpFolder().getAbsolutePath() + File.separator + destPath. No validation checks that the path stays within the intended directory. Anew File(outputFolder)is created and added tofilesToAdd. - Step 28 (sink): The tainted path reaches
listFiles()on aFileobject insideaddFolderToZip(), followed byFileUtils.deleteDirectory()on the traversed directory.
Path traversal sequences like ../../../../home/user/.ssh in the outputFolder value allowed arbitrary file reads and deletions. No sanitization anywhere in the 28-step chain. A tool checking any single file would see nothing suspicious, because no single file contains both the user input and the dangerous file operation. The blog post notes this "critical flow is much harder to identify manually" because the taint traverses "many method and function calls before reaching a Sink."
SonarQube has found real bugs in TensorFlow, NumPy, and Sentry, projects with mature review processes and active linter configurations.
The taint engine goes further. Deeper SAST extends taint tracking into transitive dependency code, following data flows through library functions the project doesn't own. On average, this finds one additional hidden vulnerability for every ten regular vulnerabilities detected in project code.
When programming language semantics hide the bug
Taint analysis catches data flow vulnerabilities. A different class of bugs requires understanding how language semantics interact across classes.
Java 25 introduced flexible constructor bodies (JEP 513), allowing subclass fields to be initialized before super(). Without that feature, you get this:
class Super {
Super() { foo(); }
void foo() { System.out.println("Base"); }
}
class Sub extends Super {
final int x;
Sub(int x) {
super(); // foo() fires here
this.x = x; // x is still 0 when foo() ran
}
@Override void foo() { System.out.println(x); } // Prints 0, not the expected value
}The superclass constructor calls foo(), which the subclass overrides to read x. But x hasn't been assigned yet because super() runs first. The overridden method silently sees zero. SonarQube's java:S8447 flags this because it models inheritance chains, method dispatch order, and field initialization semantics. No syntax pattern can express the relationship between a superclass constructor calling an overridable method and the initialization state of a subclass field. (For more Java 25 examples, see our companion article on writing Java 25 right with SonarQube.)
Why this matters more with AI agents
AI coding agents generate code across files, often scaffolding entire services and wiring route handlers to business logic to data access layers in a single pass. They don't respect module boundaries because they don't know your module boundaries. They use APIs based on training data that may predate the API's current version.
Sonar's Coding Personalities research analyzed 4,442+ distinct programming tasks per LLM, and found over 90% of all issues in AI-generated code were code smells. Every model showed what the researchers called a "fundamental lack of security awareness." The finding that stopped people is that newer models that score higher on functional benchmarks produce bugs that are more likely to be BLOCKER severity. Claude Sonnet 4, for example, improved benchmark pass rates by 4.6 percentage points over its predecessor (77.04% vs. 72.46%) while producing bugs 93% more likely to be the highest severity. Functional correctness and code safety are not the same axis.
The State of Code Developer Survey found that 42% of committed code is now AI-generated or AI-assisted, and 96% of developers don't fully trust the output. Only 48% always verify before committing.
The verification tool for this code needs to understand semantics and data flow, not just patterns, and that verification no longer has to wait for CI. SonarQube Agentic Analysis brings SonarQube's trusted analysis into the agent's inner loop, running inside the IDE or coding agent workflow. The agent writes code, asks SonarQube to verify it via the SonarQube MCP server, and gets taint analysis and semantic rule results before the code reaches a pull request. The same deterministic, fast-feedback loop that makes linting valuable for agents now includes cross-file data flow analysis, taint tracking, and language-semantic code verification.
Getting started
If your team already runs linters in the agent's feedback loop, you're ahead of most. The next step is adding the analysis layer that catches what linters structurally cannot.
- SonarQube Cloud runs the full analysis engine on every PR, including taint analysis across files and into dependency code.
- SonarQube for IDE brings issue detection into your editor, synced with your project's quality profile.
- SonarQube Agentic Analysis puts that same engine in the agent's workflow, so code verification happens before code reaches review. Currently available in open beta for all SonarQube Cloud users, with support for a growing list of languages including Java, JavaScript, TypeScript, Python, secrets detection, and more.
Linting is the floor, not the ceiling. SonarQube brings you beyond that important first step.