

TL;DR overview
- Sonar's latest LLM code quality analysis—run across 4,000+ Java tasks—finds GPT-5.2 High achieves the best security posture (16 blocker vulnerabilities per MLOC) but generates the highest code volume (974,379 LOC), creating significant maintainability burden.
- Claude Sonnet 4.5 produces 198 blocker vulnerabilities per MLOC including path traversal and injection flaws, while Opus 4.5 Thinking reduces this to 44 per MLOC, suggesting reasoning mode meaningfully improves security constraint verification.
- Code smells dominate across all models—accounting for 92–96% of all detected issues—confirming that maintainability is a universal cost of AI-generated code at scale.
- Results are available on the Sonar LLM Leaderboard, giving engineering leaders transparent quality data to inform AI model selection.
Functional benchmarks remain a standard for evaluating AI models, effectively measuring whether generated code can pass a test case. As LLMs evolve, they are becoming increasingly proficient at solving these functional challenges. However, for engineering leaders deploying this code into production, functional correctness is only half of the equation.
To understand the real effectiveness of AI coding models, we need to understand its structural quality, security, and maintainability as well. Thankfully, Sonar is an excellent position to do this work as we analyze over 750 billion lines of code each day.
Several months ago, we began analyzing the quality, security, and maintainability of the code created with leading LLMs by testing them on over 4,000 distinct Java programming assignments using the SonarQube static analysis engine.
Today, we are making all evaluations available in a new Sonar LLM leaderboard and sharing our latest findings on GPT-5.2 High, GPT-5.1 High, Gemini 3.0 Pro, Opus 4.5 Thinking, and Claude Sonnet 4.5.
Explore the new data on the Sonar LLM Leaderboard
Visualizing the trade-offs
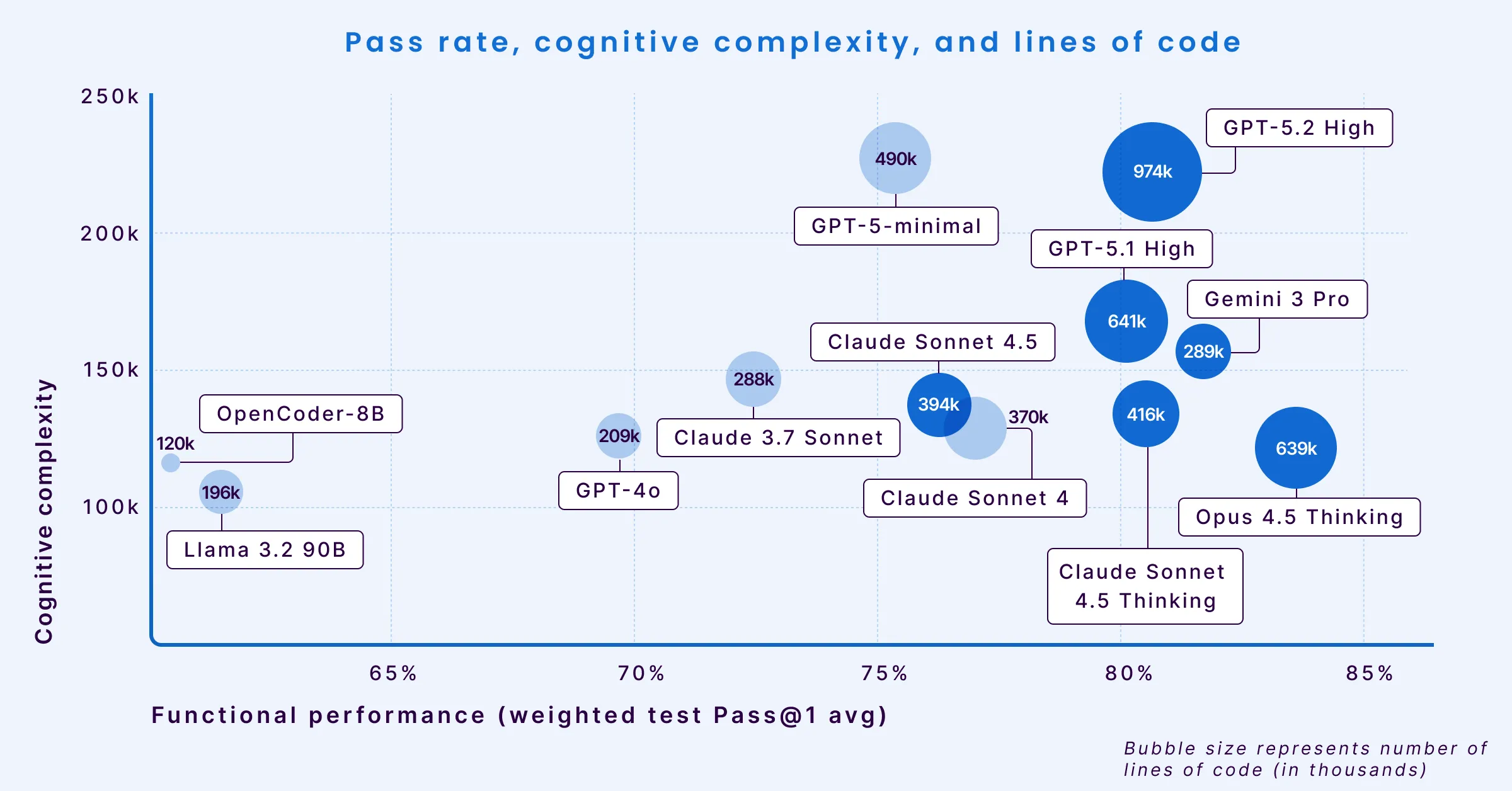
To understand the trade-offs and behaviors of different models, we plotted them on three critical dimensions: pass rate (X-axis), cognitive complexity (Y-axis), and verbosity (bubble size).
As models become more “performant” and move to the right, their outputs tend to get more verbose and complex, imposing higher burdens on engineers reviewing and using the code.
The complexity correlation
Our research highlights a correlation between model reasoning capabilities and code complexity. As models attempt sophisticated, stateful solutions to harder problems, they often move away from simple code. This shift introduces engineering challenges that are harder to detect than simple syntax errors.
For example:
- Opus 4.5 Thinking leads in functional performance with an 83.62% pass rate (thus it is furthest to the right in the chart above). However, this performance comes with high verbosity, generating 639,465 lines of code (LOC) to solve the benchmark test (which is why it is one of the largest bubble sizes on the chart). This is more than double the volume of less verbose models.
- Gemini 3 Pro stands out as an efficiency outlier. It achieves a comparable 81.72% pass rate while maintaining low cognitive complexity and low verbosity (small bubble size). This combination suggests a unique ability to solve complex problems with concise, readable code. But Gemini has the highest issue density in contrast to the other recent models.
- GPT 5.2 High ranks third in functional performance (80.66%), trailing Opus 4.5 and Gemini 3 Pro. Despite the high pass rate, it generated the highest code volume of the cohort (974,379 LOC). Compared to its predecessor (GPT 5.1 High), GPT 5.2 shows regressed maintainability and increased bug density across all severities, though it demonstrates marginal improvements in overall security and blocker-level vulnerabilities.
- GPT-5.1 High also achieves an 80% pass rate but exhibits an increase in cognitive complexity (high placement on the Y-axis). This indicates that while it solves the problem, it generates logic that is structurally more difficult to read and maintain.
Engineering discipline and reliability
While models demonstrate strong logic capabilities, our analysis reveals distinct patterns in how they handle software engineering fundamentals like resource management and thread safety. Contextualizing these numbers reveals significant disparities in reliability between models that otherwise have similar pass rates.
1. Concurrency challenges: GPT-5.2 High demonstrates powerful reasoning but is more prone to concurrency errors than its peers. It generates 470 concurrency issues per million lines of code (MLOC) —a rate nearly double that of the next closest model and over 6x higher than Gemini 3 Pro.
2. Resource management: Claude Sonnet 4.5 showed a higher rate of resource management leaks, generating 195 leaks per MLOC. By comparison, GPT-5.1 High produced only 51 leaks per MLOC for the same tasks.
3. Control flow precision: Gemini 3 Pro posted the highest rate of control flow mistakes (200 per MLOC), nearly 4x higher than Opus 4.5 Thinking (55 per MLOC). GPT 5.2 High demonstrated high precision, achieving the lowest error rate in the cohort at just 22 control flow mistakes per MLOC.
Security verification
Security remains a critical area for verification. Our analysis confirms that models do not always reliably track untrusted user input from source to sink.
Claude Sonnet 4.5 registered 198 blocker-severity vulnerabilities per MLOC, including path traversal and injection flaws. This rate is higher than other models in its class. Opus 4.5 Thinking performed significantly better with only 44 blockers per MLOC, suggesting its “thinking” process may allow for better verification of security constraints before generating output. GPT 5.2 High achieved the best security posture in the cohort, with only 16 blocker vulnerabilities per MLOC. While other metrics showed this model struggles with code volume and general bug density, its handling of critical security hotspots is currently best-in-class.
The challenge of maintainability
Beyond critical bugs, maintainability remains a primary factor in the total cost of ownership for AI code. “Code smell” issues, which degrade maintainability, accounted for 92% to 96% of all detected issues across the models evaluated.
GPT-5.1 High generated over 4,400 generic smells per MLOC.
Claude Sonnet 4.5 bypassed more design best practices.
About the Sonar LLM Leaderboard
We created the Sonar LLM Leaderboard to provide transparency into how models build code, not just what they build. By running thousands of AI-generated solutions through SonarQube, we evaluate models on the metrics that matter to engineering leaders: security, reliability, maintainability, and complexity.
Explore the complete dataset on the Sonar LLM Leaderboard.