

Le cross-site scripting (XSS) est un type de vulnérabilité bien connu qui se produit lorsqu'un pirate informatique parvient à injecter du code JavaScript dans une page vulnérable. Lorsqu'une victime inconsciente visite la page, le code injecté est exécuté dans la session de la victime. L'impact de cette attaque peut varier en fonction de l'application, sans incidence sur l'activité, jusqu'à la prise de contrôle de compte (ATO), la fuite de données ou même l'exécution de code à distance (RCE).
Il existe différents types de XSS, tels que le XSS réfléchi, le XSS stocké et le XSS universel. Mais ces dernières années, la classe de mutation du XSS est devenue redoutée pour sa capacité à contourner les nettoyeurs, tels que DOMPurify, Mozilla bleach, Google Caja, etc., affectant de nombreuses applications, y compris Google Search. À ce jour, nous constatons que de nombreuses applications sont vulnérables à ce type d'attaques.
Mais qu'est-ce que le mXSS ?
(Nous avons également abordé ce sujet dans notre présentation Insomnihack 2024 : Beating The Sanitizer: Why You Should Add mXSS To Your Toolbox.)
Contexte
Si vous êtes développeur web, vous avez probablement intégré, voire mis en œuvre, un système de nettoyage pour protéger votre application contre les attaques XSS. Mais on sait peu de choses sur la difficulté de créer un nettoyeur HTML efficace. L'objectif d'un sanitizer HTML est de garantir que le contenu généré par les utilisateurs, tel que les saisies de texte ou les données obtenues à partir de sources externes, ne présente aucun risque pour la sécurité et ne perturbe pas le fonctionnement prévu d'un site web ou d'une application.
L'un des principaux défis liés à la mise en œuvre d'un sanitizer HTML réside dans la nature complexe du langage HTML lui-même. Le HTML est un langage polyvalent qui comprend un large éventail d'éléments, d'attributs et de combinaisons potentielles pouvant affecter la structure et le comportement d'une page web. Analyser et interpréter le code HTML avec précision tout en préservant ses fonctionnalités prévues peut s'avérer une tâche ardue.
HTML
Avant d'aborder le sujet du mXSS, examinons d'abord le HTML, le langage de balisage qui constitue la base des pages web. Il est essentiel de comprendre la structure et le fonctionnement du HTML, car les attaques mXSS (mutation Cross-Site Scripting) exploitent les particularités et les subtilités du HTML.
Le HTML est considéré comme un langage tolérant en raison de sa nature indulgente lorsqu'il rencontre des erreurs ou du code inattendu. Contrairement à certains langages de programmation plus stricts, le HTML donne la priorité à l'affichage du contenu, même si le code n'est pas parfaitement écrit. Voici comment cette tolérance se manifeste :
Lorsqu'un balisage défectueux est rendu, au lieu de planter ou d'afficher un message d'erreur, les navigateurs tentent d'interpréter et de corriger le HTML du mieux qu'ils peuvent, même s'il contient des erreurs de syntaxe mineures ou des éléments manquants. Par exemple, l'ouverture du balisage suivant dans le navigateur <p>test s'exécutera comme prévu malgré l'absence d'une balise de fermeture p. En examinant le code HTML de la page finale, nous pouvons voir que l'analyseur a corrigé notre balisage incorrect et a fermé l'élément p de lui-même : <p>test</p>.
Pourquoi est-ce tolérant ?
- Accessibilité : le Web doit être accessible à tous, et les erreurs mineures dans le code HTML ne doivent pas empêcher les utilisateurs de voir le contenu. La tolérance permet à un plus large éventail d'utilisateurs et de développeurs d'interagir avec le Web.
- Flexibilité : le code HTML est souvent utilisé par des personnes ayant des niveaux d'expérience variés en matière de codage. La tolérance permet certaines imprécisions ou erreurs sans perturber complètement le fonctionnement de la page.
- Rétrocompatibilité : le Web est en constante évolution, mais de nombreux sites Web existants sont construits selon des normes HTML plus anciennes. La tolérance garantit que ces anciens sites peuvent toujours être affichés dans les navigateurs modernes, même s'ils ne respectent pas les dernières spécifications.
Mais comment notre analyseur HTML sait-il comment « corriger » un balisage défectueux ? Doit-il <a><b> devenir<a></a><b></b> ou <a><b></b></a> ?
Pour répondre à cette question, il existe une spécification HTML bien documentée, mais malheureusement, il subsiste certaines ambiguïtés qui entraînent des comportements d'analyse HTML différents, même entre les principaux navigateurs actuels.
Mutation
D'accord, le HTML peut tolérer un balisage défectueux, mais en quoi cela est-il pertinent ?
Le M dans mXSS signifie « mutation », et une mutation en HTML est tout type de modification apportée au balisage pour une raison ou une autre.
- Lorsqu'un analyseur corrige un balisage incorrect (
<p>test→<p>test</p>), il s'agit d'une mutation. - Normaliser les guillemets d'attribut (
<a alt=test>→<a alt=”test”>), c'est une mutation. - Réorganiser les éléments (
<table><a>→<a></a><table></table>), c'est une mutation - Et ainsi de suite...
mXSS tire parti de ce comportement afin de contourner la désinfection. Nous présenterons des exemples dans les détails techniques.
Contexte de l'analyse HTML
Il n'est pas réaliste de résumer en une seule section l'analyse HTML, une norme de 1 500 pages. Cependant, en raison de son importance pour comprendre en profondeur mXSS et le fonctionnement des charges utiles, nous devons au moins aborder certains sujets majeurs. Pour faciliter les choses, nous avons développé une fiche de référence mXSS (à venir plus loin dans cet article) qui condense cette norme volumineuse en une ressource plus facile à gérer pour les chercheurs et les développeurs.
Différents types d'analyse de contenu
Le HTML n'est pas un environnement d'analyse universel. Les éléments traitent leur contenu différemment, avec sept modes d'analyse distincts. Nous allons explorer ces modes afin de comprendre leur influence sur les vulnérabilités mXSS :
- éléments vides
area,base,br,col,embed,hr,img,input,link,meta,source,track,wbr
- l'élément
templatetemplate
- Éléments de texte brut
script,style,noscript,xmp,iframe,noembed,noframes
- Éléments de texte brut échappables
textarea,title
- Éléments de contenu étranger
svg,math
- État en texte brut
plaintext
- Éléments normaux
- Tous les autres éléments HTML autorisés sont des éléments normaux.
Nous pouvons assez facilement démontrer la différence entre les types d'analyse à l'aide de l'exemple suivant :
- Notre première entrée est un élément
div, qui est un élément « normal » : <div><a alt="</div><img src=x onerror=alert(1)>">- D'autre part, la deuxième entrée est un balisage similaire utilisant à la place l'élément
style(qui est un « texte brut ») : <style><a alt="</style><img src=x onerror=alert(1)>">
En examinant le balisage analysé, nous pouvons clairement voir les différences d'analyse :
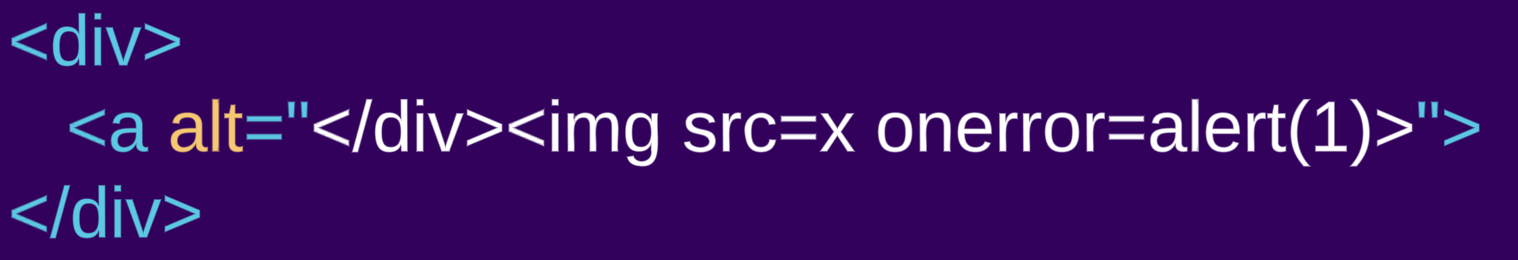

Le contenu de l'élément div est rendu en HTML, un élément a est créé. Ce qui semble être une balise de fermeture div et une balise img est en fait une valeur d'attribut de l'élément a, donc rendu comme texte alt pour l'élément a et non comme balise HTML. Dans l'exemple style, le contenu de l'élément style est rendu comme du texte brut, donc aucun élément a n'est créé, et l'attribut présumé est désormais une balise HTML normale.
Éléments de contenu étrangers
HTML5 a introduit de nouvelles façons d'intégrer du contenu spécialisé dans les pages web. Deux exemples clés sont les éléments <svg> et <math>. Ces éléments exploitent des espaces de noms distincts, ce qui signifie qu'ils suivent des règles d'analyse différentes de celles du HTML standard. Il est essentiel de comprendre ces différentes règles d'analyse pour atténuer les risques potentiels liés aux attaques mXSS.
Examinons le même exemple que précédemment, mais cette fois encapsulé dans un élément svg :
<svg><style><a alt="</style><img src=x onerror=alert(1)>">
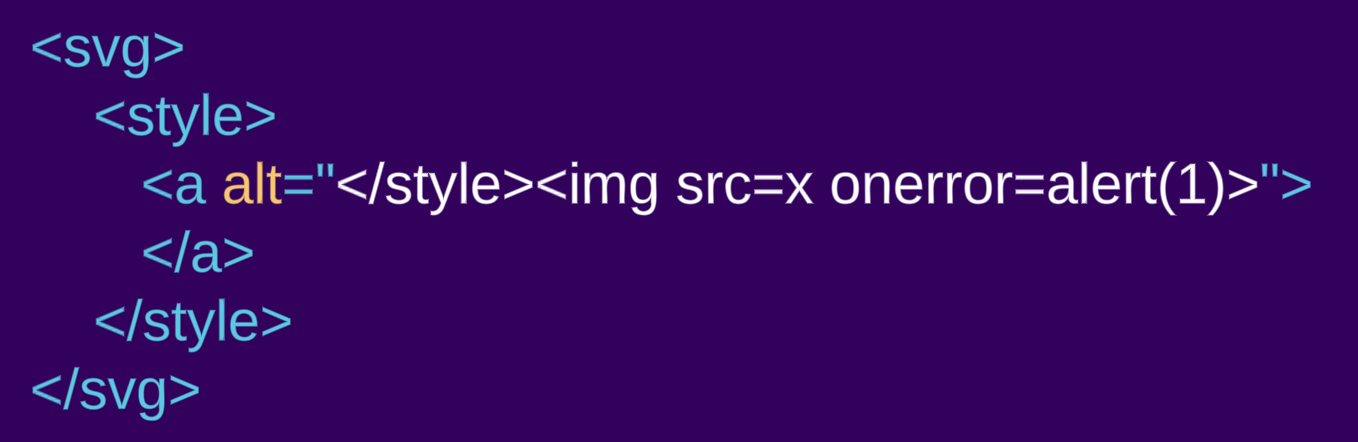
Dans ce cas, nous voyons bien un élément a être créé. L'élément style ne suit pas les règles d'analyse du « texte brut », car il se trouve dans un espace de noms différent. Lorsqu'il réside dans un espace de noms SVG ou MathML, les règles d'analyse changent et ne suivent plus le langage HTML.
En utilisant des techniques de confusion d'espace de noms (telles que DOMPurify 2.0.0 bypass), les attaquants peuvent manipuler le nettoyeur pour analyser le contenu d'une manière différente de celle dont il sera finalement rendu par le navigateur, échappant ainsi à la détection des éléments malveillants.
Des mutations aux vulnérabilités
Le terme mXSS est souvent utilisé de manière générale pour désigner divers contournements de nettoyeurs. Pour mieux comprendre, nous allons diviser le terme général « mXSS » en 4 sous-catégories différentes
Différences entre les analyseurs
Bien que les différences entre les analyseurs puissent être considérées comme un contournement habituel du nettoyeur, elles sont parfois appelées mXSS. Dans tous les cas, un pirate peut tirer parti d'une incompatibilité entre l'algorithme du nettoyeur et celui du moteur de rendu (par exemple, le navigateur). En raison de la complexité de l'analyse HTML, l'existence de différences d'analyseur ne signifie pas nécessairement qu'un analyseur est incorrect et l'autre correct.
Prenons par exemple l'élément noscript, dont la règle d'analyse est la suivante : « Si le drapeau de script est activé, basculez l'analyseur de tokens vers l'état RAWTEXT. Sinon, laissez l'analyseur de tokens dans l'état data. » (lien) Cela signifie que, selon que JavaScript est désactivé ou activé, le corps de l'élément noscript est rendu différemment. Il est logique que JavaScript ne soit pas activé au stade du nettoyage, mais qu'il le soit dans le moteur de rendu. Ce comportement n'est pas incorrect par définition, mais il peut entraîner des contournements tels que : <noscript><style></noscript><img src=x onerror=”alert(1)”>
JS désactivé :

JS activé :

De nombreuses autres différences entre les analyseurs, telles que différentes versions HTML, des incompatibilités de type de contenu, etc., peuvent également survenir.
Aller-retour d'analyse
L'aller-retour d'analyse est un phénomène bien connu et documenté, qui dit : « Il est possible que la sortie de cet algorithme, si elle est analysée avec un analyseur HTML, ne renvoie pas la structure arborescente d'origine. Les structures arborescentes qui ne font pas l'aller-retour entre une étape de sérialisation et une étape de réanalyse peuvent également être produites par l'analyseur HTML lui-même, bien que de tels cas soient généralement non conformes. »
Cela signifie que selon le nombre de fois où nous analysons un balisage HTML, l'arborescence DOM résultante peut changer.
Examinons l'exemple officiel fourni dans la spécification :
Mais avant cela, nous devons comprendre qu'un élément form ne peut pas contenir un autre élément form : « Modèle de contenu : contenu fluide, mais sans aucun élément form descendant. » (comme indiqué dans les spécifications)
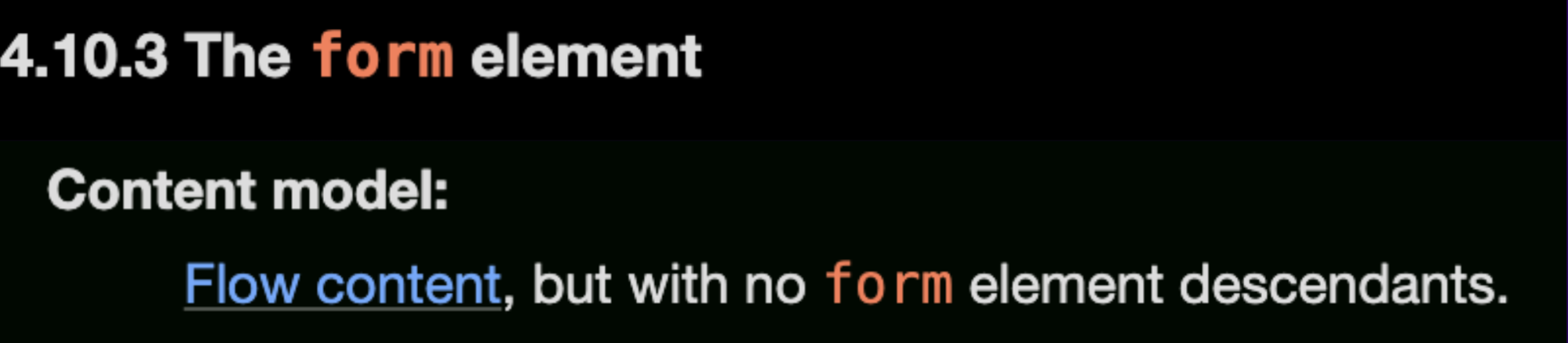
Mais si nous continuons à lire la documentation, ils donnent un exemple de la manière dont les éléments form peuvent être imbriqués, à l'aide du balisage suivant :
<form id="outer"><div></form><form id="inner"><input>
html
├── head
└── body
└── form id="outer"
└── div
└── form id="inner"
└── inputLa balise </form> est ignorée en raison de la balise div non fermée, et l'élément input sera associé à l'élément form interne. Maintenant, si cette structure arborescente est sérialisée et réanalysée, la balise de début <form id="inner"> sera ignorée, et l'élément input sera donc associé à l'élément form externe à la place.
<html><head></head><body><form id="outer"><div><form id="inner"><input></form></div></form></body></html>
html
├── head
└── body
└── form id="outer"
└── div
└── inputLes attaquants peuvent exploiter ce comportement pour créer une confusion entre l'espace de noms du nettoyeur et celui du moteur de rendu, ce qui permet de contourner la protection, par exemple :
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
Crédit @SecurityMB, traité en détail ici.
Désanitisation
La désanitisation est une erreur cruciale commise par les applications lorsqu'elles interfèrent avec la sortie du nettoyeur avant de l'envoyer au client, annulant ainsi le travail du nettoyeur. Toute petite modification du balisage peut avoir un impact majeur sur l'arborescence DOM finale, entraînant un contournement de la désanitisation. Nous avons déjà abordé cette question lors d'une conférence à Insomni'Hack et dans plusieurs articles de blog, où nous avons identifié des vulnérabilités dans diverses applications, notamment :
- Les pièges de la désanitisation : fuite de données clients depuis osTicket
- Les vulnérabilités du code mettent les e-mails Proton en danger
- Exécution de code à distance dans Tutanota Desktop en raison d'une faille dans le code
- Les vulnérabilités du code mettent les e-mails Skiff en danger
Voici un exemple de désanitisation : une application prend la sortie du sanitizer et renomme l'élément svg en custom-svg, ce qui modifie l'espace de noms de l'élément et peut provoquer un XSS lors du re-rendu.
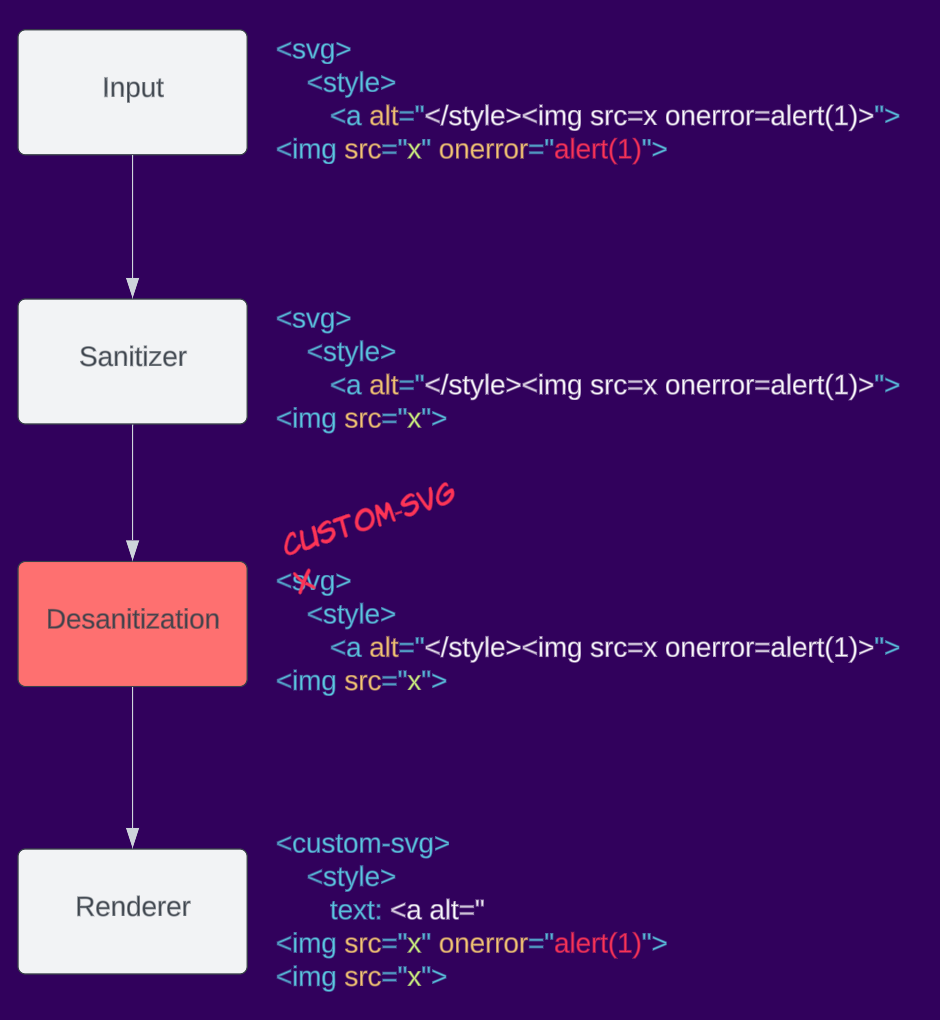
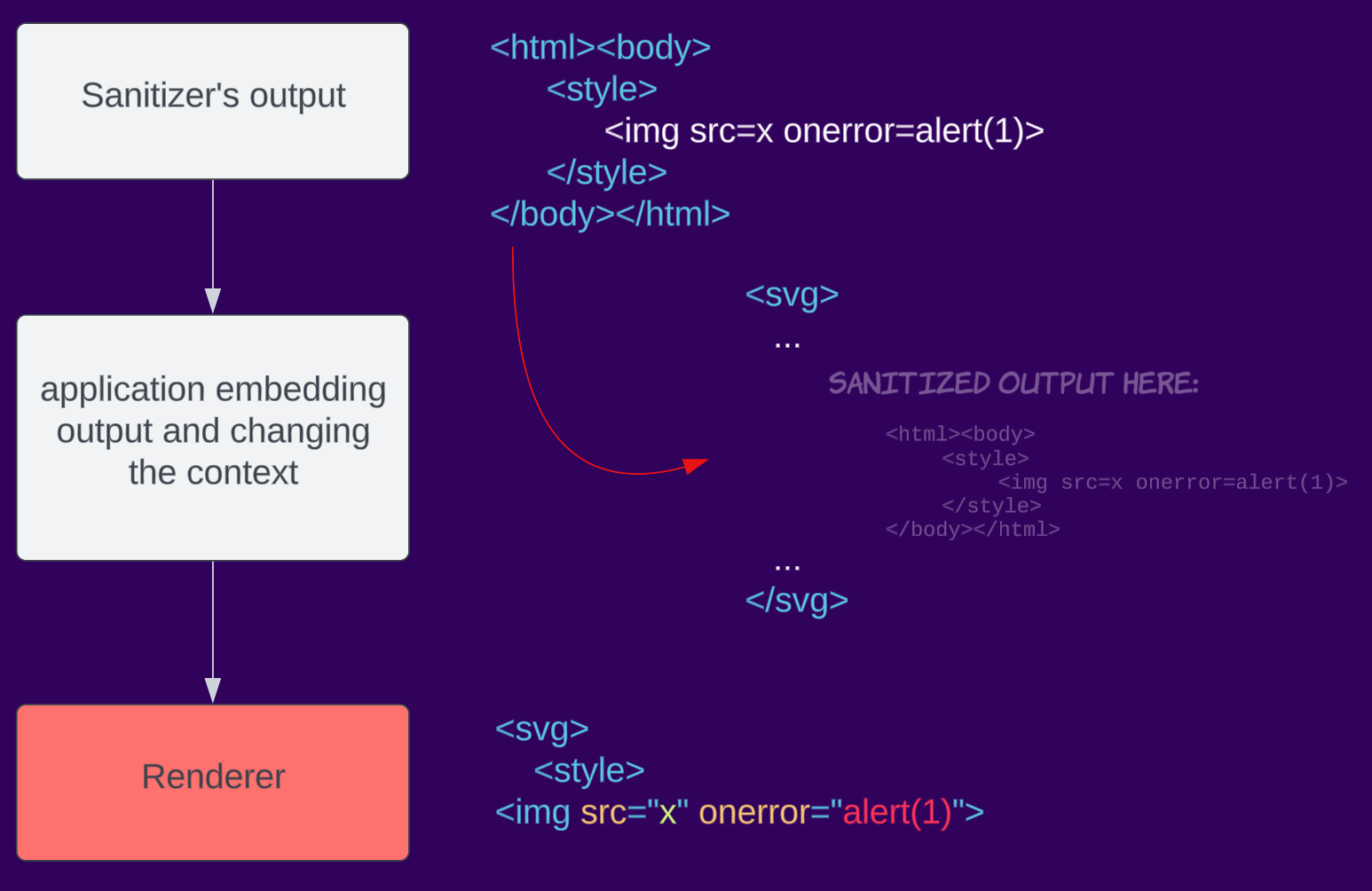
Dépendant du contexte
L'analyse HTML
est complexe et peut varier en fonction du contexte. Par exemple, l'analyse d'un document entier diffère de l'analyse d'un fragment dans Firefox (voir la section Browser Specific de la fiche de référence). Face au passage de la purification au rendu dans le navigateur, les développeurs peuvent modifier par erreur le contexte dans lequel les données sont rendues, ce qui entraîne des différences d'analyse et, à terme, contourne le purificateur. Comme les nettoyeurs tiers ne connaissent pas le contexte dans lequel le résultat sera placé, ils ne peuvent pas résoudre ce problème. Celui-ci devrait être résolu lorsque les navigateurs implémenteront un nettoyeur intégré (effort Sanitizer API).
Par exemple, une application nettoie une entrée, mais lorsqu'elle l'intègre dans la page, elle l'encapsule dans SVG, changeant ainsi le contexte en un espace de noms SVG.
Études de cas mXSS
Bien que nous ayons déjà publié des articles de blog traitant des vulnérabilités mXSS, tels que Réponse à calc : la chaîne d'attaque pour compromettre Mailspring, nous avons également signalé divers contournements de sanitisers, tels que mganss/HtmlSanitizer (CVE-2023-44390), Typo3 (CVE-2023-38500), OWASP/java-html-sanitizer, et bien d'autres encore.
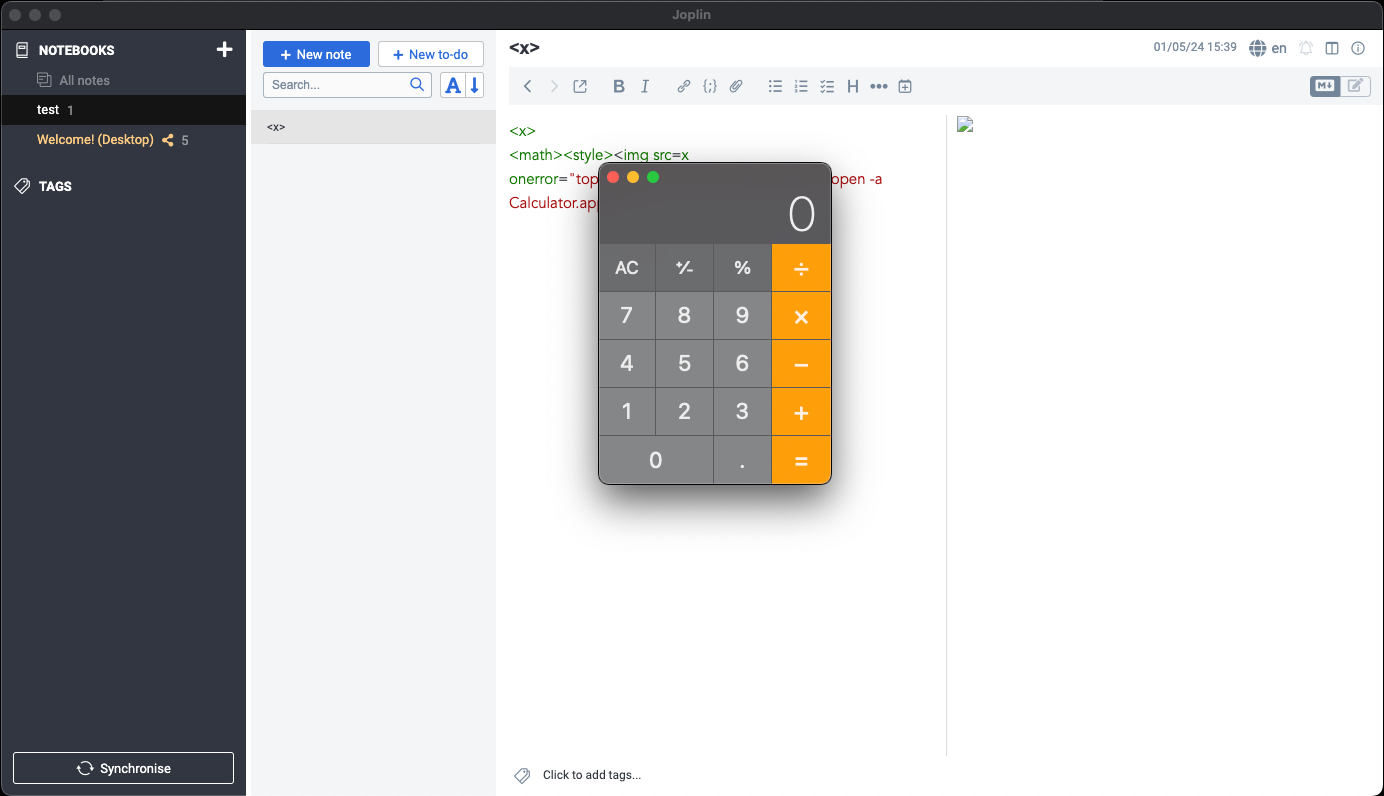
Mais examinons un cas simple dans un logiciel appelé Joplin (CVE-2023-33726), une application de prise de notes pour ordinateur de bureau écrite en Electron. En raison de configurations Electron non sécurisées, le code JS de Joplin peut utiliser les fonctionnalités internes de Node, ce qui permet à un attaquant d'exécuter des commandes arbitraires sur la machine.
L'origine de la vulnérabilité réside dans l'analyseur du sanitizer, qui analyse les entrées HTML non fiables via le paquet npm htmlparser2. Le package lui-même affirme ne pas respecter les spécifications et privilégier la vitesse à la précision : « Si vous avez besoin d'une conformité stricte aux spécifications HTML, jetez un œil à parse5. »
Nous avons très vite remarqué que cet analyseur ne respectait pas les spécifications. Avec l'entrée suivante, nous pouvons voir que l'analyseur ignore les différents espaces de noms.

Alors que l'analyseur du désinfecteur ne rend pas l'élément img, le moteur de rendu le fait. Il s'agit d'un exemple de différentiel d'analyseur. Un attaquant peut simplement ajouter un gestionnaire d'événements onerror qui exécutera un code arbitraire lorsqu'une victime ouvrira une note malveillante.
Cette découverte spécifique a également été faite indépendamment par @maple3142.
Atténuation
Malheureusement, il n'existe pas de solution d'atténuation simple. Nous encourageons les développeurs à comprendre en profondeur cette classe de bogues afin qu'ils puissent prendre une meilleure décision sur la manière d'atténuer ce problème en fonction de leur application.
Au cours de nos recherches, nous avons découvert un certain nombre d'approches d'atténuation et de mesures de sécurité prises par les développeurs afin de résoudre le problème du mXSS (également disponibles dans la fiche pratique) :
Nettoyer côté client
- Il s'agit probablement de la règle la plus importante à suivre. L'utilisation de nettoyeurs qui s'exécutent côté client, tels que DOMPurify, permet d'éviter les risques liés aux différences entre les analyseurs syntaxiques. En raison de la complexité de l'analyse syntaxique et du fait que le contenu est très probablement servi à différents analyseurs syntaxiques (Firefox vs Chrome vs Safari, etc.), il est impossible d'éviter les différences lorsque le HTML n'est pas analysé au même endroit que celui où le contenu est finalement rendu. Pour cette raison, les nettoyeurs côté serveur sont susceptibles d'échouer.
- Lorsque vous utilisez le rendu côté serveur (SSR) avec un framework JS côté client, il peut être facile d'ajouter des bibliothèques telles que isomorphic-dompurify. Elles permettent aux nettoyeurs côté client tels que DOMPurify de « simplement fonctionner » en mode SSR. Mais pour y parvenir, elles introduisent également un analyseur HTML côté serveur tel que jsdom, ce qui introduit des risques de différences d'analyse. L'option la plus sûre pour les applications web utilisant le SSR est de désactiver le SSR pour le HTML contrôlé par l'utilisateur et de reporter la purification et le rendu uniquement côté client.
Ne pas réanalyser
- Afin d'éviter le « Round trip mXSS », l'application peut insérer l'arborescence DOM nettoyée directement dans le document, contrairement à la sérialisation et au rendu du contenu.
- Remarque : cette approche ne peut être mise en œuvre que lorsque les nettoyeurs sont implémentés côté client et peut entraîner des comportements inattendus (tels que le rendu différent du contenu en raison d'une adaptation insuffisante au contexte de la page).
Toujours encoder ou supprimer le contenu brut
- Comme l'idée du mXSS est de trouver un moyen pour qu'une chaîne malveillante soit rendue sous forme de texte brut dans le nettoyeur, mais analysée comme du HTML par la suite, le fait de ne pas autoriser/encoder le texte brut au stade du nettoyage rendrait impossible son nouveau rendu en HTML.
- Notez que cela pourrait perturber certains éléments, tels que le code CSS.
Ne pas prendre en charge les éléments de contenu étrangers
- Ne pas prendre en charge les éléments de contenu étrangers (supprimer les éléments svg/math et leur contenu sans les renommer) dans vos nettoyeurs réduit considérablement la complexité.
- Remarque : cela n'atténue pas le mXSS, mais constitue une mesure de précaution.
Avenir
Un sujet aussi complexe sans solution simple, y a-t-il un avenir prometteur ?
La réponse est oui, heureusement, un certain nombre de propositions et de mesures ont été prises afin de mettre fin à cette classe de bogues ou, au moins, de la traiter officiellement.
Le plus gros problème aujourd'hui est que la responsabilité de nettoyer les entrées HTML non fiables incombe aux développeurs tiers, qu'il s'agisse des développeurs d'applications ou des développeurs de nettoyeurs. Cela n'est pas pratique en raison de la complexité de la tâche et du fait qu'ils devraient traiter différents analyseurs de rendu (différents utilisateurs utilisent d'autres navigateurs) et se tenir au courant de l'évolution des spécifications HTML. Une approche plus appropriée consisterait à confier au moteur de rendu la responsabilité de s'assurer qu'il n'y a pas de contenu malveillant dans le balisage. L'intégration d'un outil de nettoyage dans le navigateur, par exemple, permettrait d'éliminer la plupart, voire la totalité, des contournements que nous observons à ce jour.
L'initiative Sanitizer API va exactement dans ce sens. Elle est actuellement développée par le Web Platform Incubator Community Group (WICG) et vise à fournir aux développeurs un nettoyeur intégré, robuste et sensible au contexte, écrit par les navigateurs eux-mêmes (plus de différences entre les analyseurs ni de réanalyse). Une adoption plus large de l'API Sanitizer par les navigateurs conduirait probablement à une utilisation accrue de celle-ci par les développeurs pour une manipulation HTML plus sûre.
Une autre mesure prise pour lutter contre ce problème consiste à mettre à jour les spécifications. Par exemple, Chrome encode désormais les caractères < et > dans les attributs
<svg><style><a alt="</style>"> → <svg><style><a alt="</style>">
Faire évoluer les fondamentaux des définitions HTML vers un avenir plus sûr.
Fiche de référence mXSS 🧬🔬
Nous avons créé une fiche de référence mXSS destinée à servir de référence unique pour toute personne intéressée par l'apprentissage, la recherche et l'innovation dans le domaine du mXSS. Elle aide les utilisateurs à identifier les comportements HTML inattendus dans une liste simplifiée, plutôt que de devoir lire 1 500 pages de documentation. Nous encourageons les utilisateurs à contribuer et à faire avancer cette initiative ensemble.
Résumé
Le mXSS (mutation cross-site scripting) est une faille de sécurité qui résulte de la manière dont le HTML est traité. Même si une application web dispose de filtres puissants pour empêcher les attaques XSS traditionnelles, le mXSS peut toujours s'infiltrer. En effet, le mXSS exploite les particularités du comportement HTML, aveuglant le nettoyeur aux éléments malveillants.
Ce blog se penche sur le mXSS, fournit des exemples, divise ce grand nom « mXSS » en sous-sections et couvre les stratégies d'atténuation des développeurs. En vous dotant de ces connaissances, nous espérons que les développeurs et les chercheurs pourront aborder cette question en toute confiance à l'avenir.