

As part of building the new architecture management capability in SonarQube, I spent numerous hours playing with the new product on OSS projects, to test, dogfood, and demo. One of my favorite projects for this is GCToolkit from Microsoft, with which I developed such familiarity that I thought I should share an architecture review of it.
Microsoft GCToolKit is a set of libraries built to analyze HotSpot Java garbage collection (GC) log files. While it is a "smallish" project, it is dense enough to exhibit meaningful structural insights. Let me share how I have used SonarQube to get some deep structural insights, and some changes that could be made to the architecture of this project, to make it more understandable and modular.
At the top level
At a glance, I can see that this java project has 5 modules, because there are 5 boxes that feature the module icon.
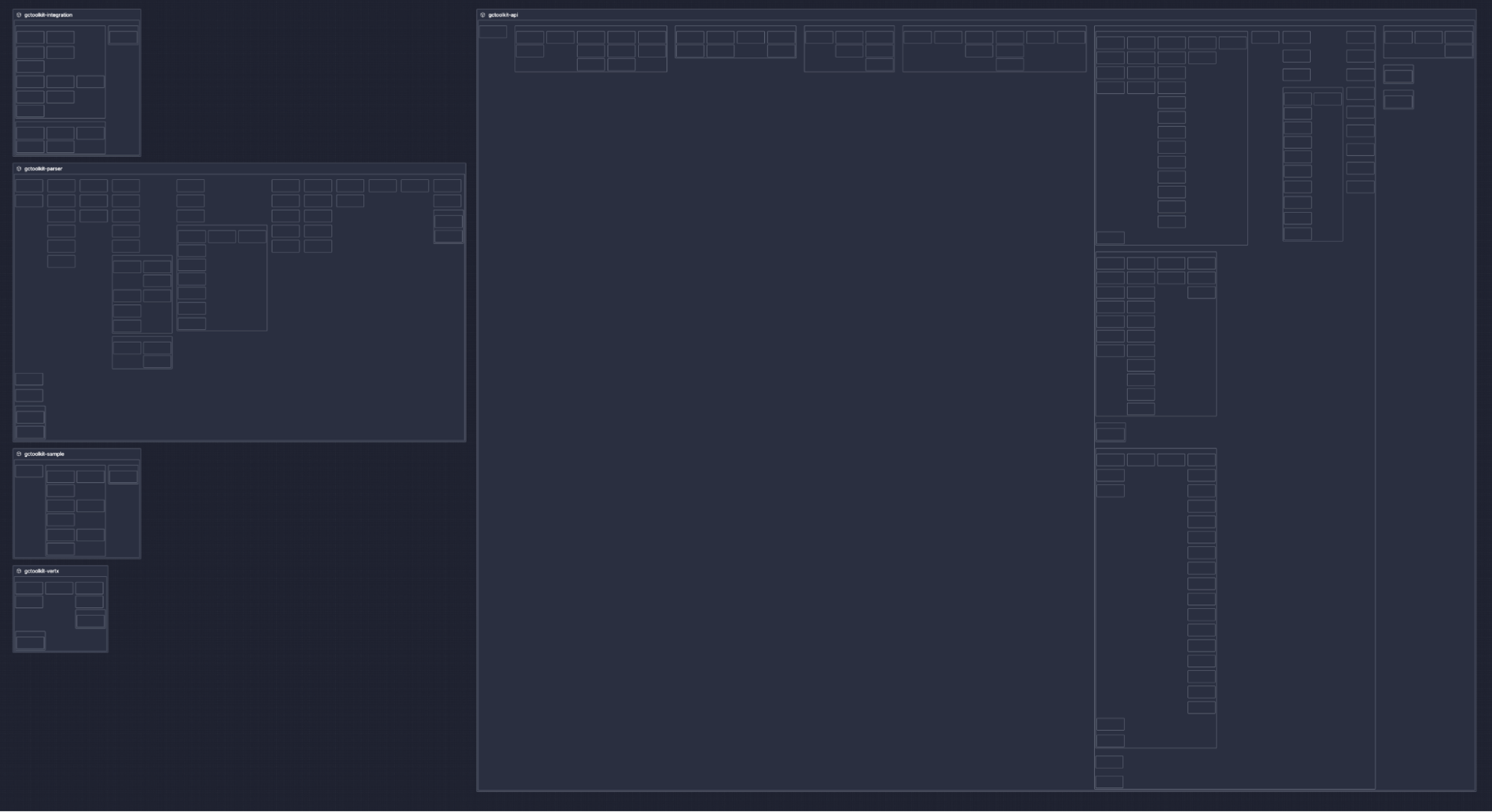
Because I can interpret the layouts, I know that the four modules on the left don’t use each other (they are in the same column), but they all use the API module on the right.
The API module on the right is pretty fat, and deserves a closer look to understand what is in it, and whether it could/should be split. Its square shape, and the large amount of whitespace at the bottom left indicate that the top row of components has a strong coupling, while vertical components have no coupling at all. That makes me want to see if the structure could be easily changed to encapsulate more of the structural intent, making it easier to understand and more modular than the current monolith.
Digging inside the monolith
Let’s take a closer look at the internals of the gctoolkit-api module. I first examine the relationships for that chain across the top, selecting each of the packages in turn to see what they depend on:

A clear pattern is common to all the packages in the chain:
- Each is dependent on the others in the chain. This includes cyclic “feedback” dependencies (the looping lines indicate right-to-left direction). This means they are tightly coupled and are not candidates for extraction—they belong together.
- None of them directly uses that deep vertical column. Rather, they bypass it and use only the classes to its right. This means that the horizontal and vertical subsets are candidates for separation. In other words, they do not use each other.
There is however one exception to this pattern that stands out:
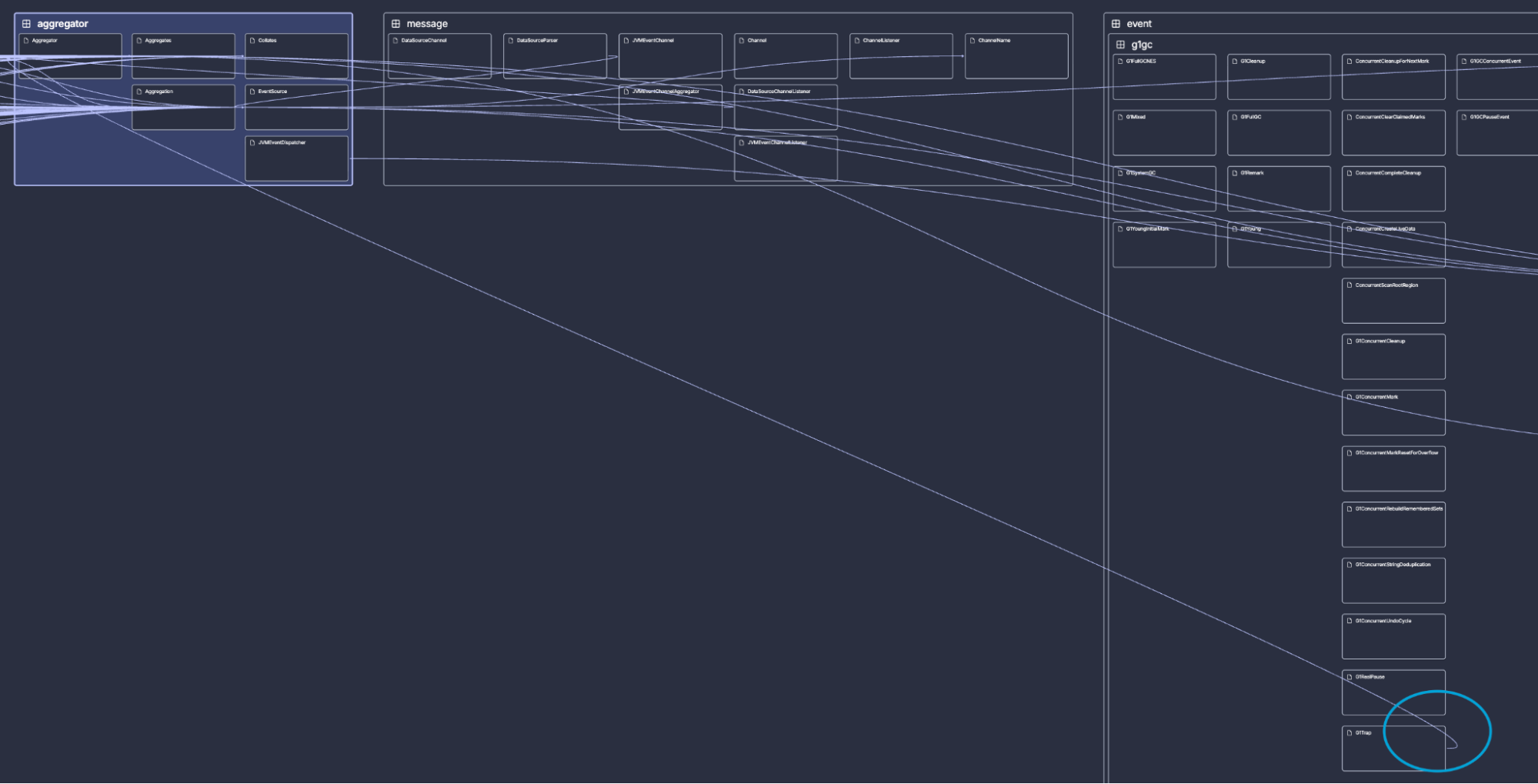
There is a feedback dependency from G1Trap on the right to Aggregator on the left. I suspect this outlier is unintentional. It is the kind of 'drift' that often happens when the established flow of dependencies isn’t visible during the daily flow of development. Perhaps the reference from G1Trap to Aggregator is accidental, or G1Trap is misplaced and should be located in a package to the left?
Overall it means that, should we sort out the exception, here is the architecture of the monolith:
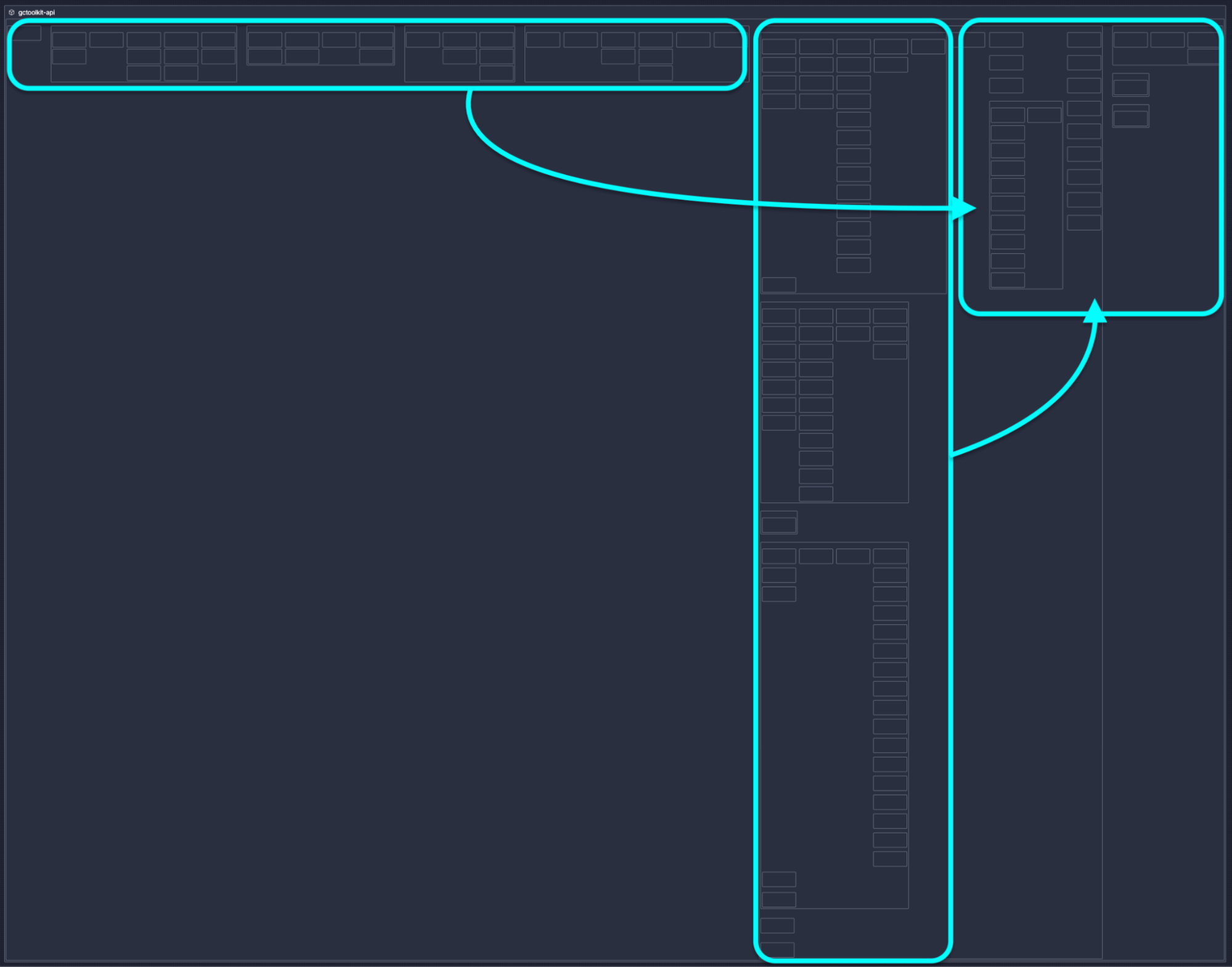
Proposed refinement
Placing these groups into separate modules would reinforce this independence and reduce the module size discrepancy. This new structure could be controlled with an intended architecture model like this:
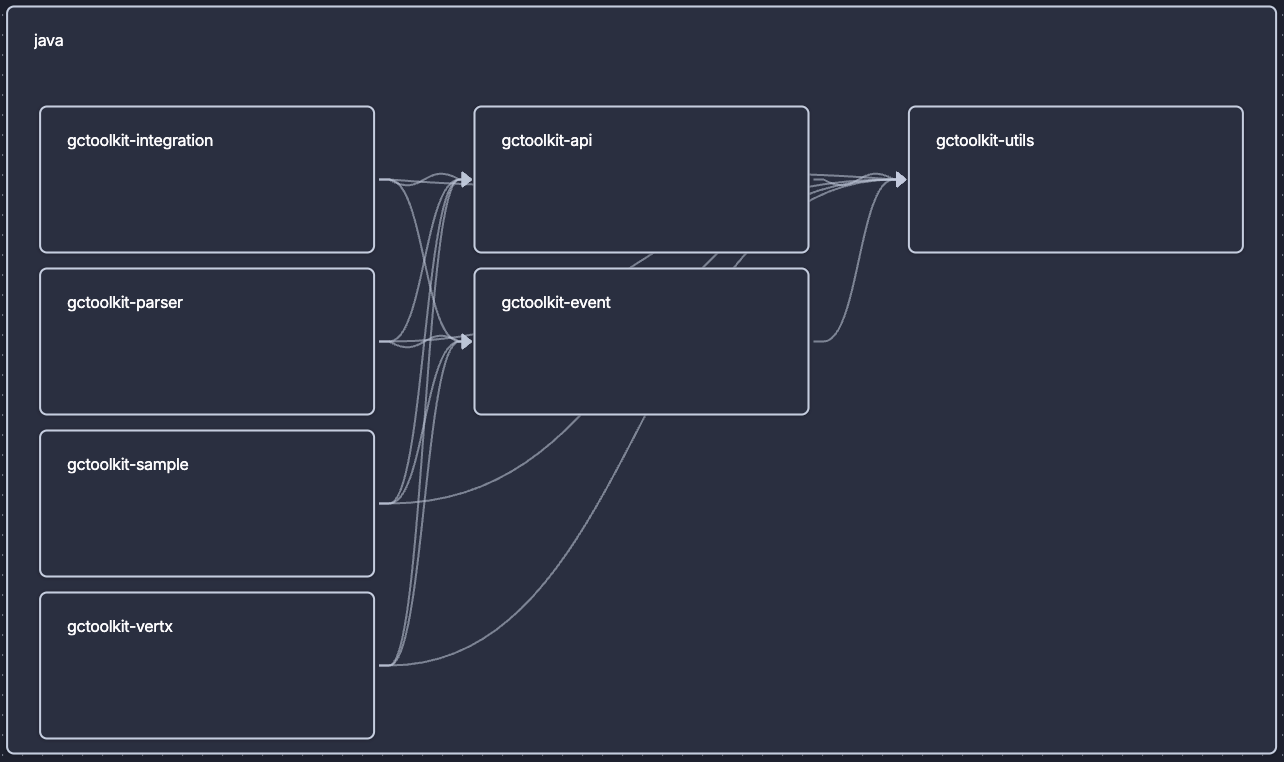
The original gctoolkit-api module would retain just the horizontal chain, a new gctoolkit-event module would contain the vertical column, and a new gctoolkit-utils would contain the collection of classes used by both.
If we do not first solve the exception, this modified structure would raise a deviation issue for the feedback dependency we spotted earlier, and prevent any further accidental relationships from being created. It would also help the developer understand the architecture, greasing the wheels of ongoing development.
And that’s my architectural review of GC Toolkit with SonarQube. In conclusion, using high-level structure, the shape of components, and their relationship, I was able to understand the intended architecture of the project, and see some drifting that happened. The next step would be to declare the intended architecture to make sure there is no further drifting. That’s it for today, folks.