

クロスサイトスクリプティング(XSS)は、攻撃者が脆弱なページにJavaScriptコードを注入できる場合に発生する、よく知られた脆弱性タイプです。無防備な被害者がそのページを訪問すると、注入されたコードが被害者のセッション内で実行されます。この攻撃の影響はアプリケーションによって異なり、ビジネスへの影響がない場合から、アカウント乗っ取り(ATO)、データ漏洩、さらにはリモートコード実行(RCE)に至るまで様々です。
XSSにはリフレクテッド型、ストアド型、ユニバーサル型など様々な種類があります。しかし近年、DOMPurify、Mozilla bleach、Google Cajaなどのサニタイザーを迂回する変異型XSSが脅威となり、Google検索を含む多数のアプリケーションに影響を与えています。今日でも、こうした攻撃に脆弱なアプリケーションが数多く存在します。
では、mXSSとは何か?
(このテーマについては、Insomnihack 2024での講演「サニタイザーを突破せよ:ツールボックスにmXSSを加えるべき理由」でも掘り下げました。)
背景
ウェブ開発者であれば、XSS攻撃からアプリケーションを保護するため、何らかのサニタイズ機能を統合または実装した経験があるでしょう。しかし、適切なHTMLサニタイザーの構築がいかに困難かについては、ほとんど知られていません。HTMLサニタイザーの目的は、テキスト入力や外部ソースからのデータ取得など、ユーザー生成コンテンツがセキュリティリスクをもたらしたり、ウェブサイトやアプリケーションの意図した機能を妨げたりしないことを保証することです。
HTMLサニタイザー実装における主な課題の一つは、HTML自体の複雑な性質にあります。HTMLは多様な要素、属性、そしてウェブページの構造や動作に影響を与え得る潜在的な組み合わせを持つ汎用性の高い言語です。意図された機能を維持しつつHTMLコードを正確に解析・分析することは、非常に困難な作業となり得ます。
HTML
mXSS(ミューテーション・クロスサイトスクリプティング)の話題に入る前に、まずウェブページの基盤となるマークアップ言語であるHTMLについて見ていきましょう。mXSS攻撃はHTMLの特異な挙動や複雑な仕組みを利用するため、HTMLの構造と動作を理解することは極めて重要です。
HTMLは、エラーや予期しないコードに遭遇した際の寛容性から「許容性の高い言語」と見なされています。厳格なプログラミング言語とは異なり、HTMLはコードが完璧でなくともコンテンツの表示を優先します。この許容性がどのように機能するかを以下に示します:
破損したマークアップがレンダリングされる際、ブラウザはクラッシュしたりエラーメッセージを表示したりする代わりに、軽微な構文エラーや要素の欠落があっても、可能な限りHTMLを解釈し修正しようと試みます。例えば、以下のマークアップをブラウザで開くと <p>test p タグの閉じタグが欠落しているにもかかわらず、期待通りに実行されます。最終ページのHTMLコードを見ると、パーサーが破損したマークアップを修正し、p 要素を自動的に閉じていることがわかります: <p>test</p>。
許容される理由:
- アクセシビリティ: ウェブはすべての人にアクセス可能であるべきであり、HTMLの軽微なエラーがコンテンツの閲覧を妨げてはなりません。許容性により、より幅広いユーザーや開発者がウェブとやり取りできるようになります。
- 柔軟性: HTMLは、コーディング経験のレベルが異なる人々によって頻繁に使用されます。許容性により、ページの機能を完全に損なうことなく、多少の不注意やミスが許容されます。
- 後方互換性: ウェブは絶えず進化していますが、多くの既存ウェブサイトは古いHTML標準で構築されています。許容性により、最新の仕様に準拠していなくても、これらの古いサイトが現代のブラウザで表示され続けることが保証されます。
しかし、私たちのHTMLパーサーは、壊れたマークアップをどのように「修正」すべきかを どうやって 知るのでしょうか?<a><b> は<a></a><b></b> になるべきでしょうか、それとも<a><b></b></a> になるべきでしょうか?
この疑問にはHTML仕様書が明確な答えを示していますが、残念ながら今日でも主要ブラウザ間で異なる解析行動を引き起こす曖昧性が残っています。
変異
では、HTMLが壊れたマークアップを許容できることは、なぜ重要なのでしょうか?
mXSSの「M」は「変異(mutation)」を表し、HTMLにおける変異とは何らかの理由でマークアップに加えられたあらゆる変更を指します。
- パーサーが壊れたマークアップを修正する場合(
<p>test→<p>test</p>)、これはミューテーションです。 - 属性の引用符を正規化する場合(
<a alt=test>→<a alt=”test”>)、これはミューテーションです。 - 要素の順序を変更する場合(
<table><a>→<a></a><table></table>)、これはミューテーションです。 - 以下同様…
mXSSはこの動作を利用してサニタイズを回避します。技術的な詳細で具体例を示します。
HTML解析の背景
1500ページに及ぶ標準であるHTML解析を一節で要約するのは現実的ではありません。しかし、mXSSの深層理解やペイロードの動作原理を把握する上で重要であるため、主要なトピックを少なくともカバーする必要があります。理解を容易にするため、研究者や開発者向けに膨大な標準仕様を要約したmXSSチートシート(本ブログ後述)を開発しました。
異なるコンテンツ解析タイプ
HTMLは万能の解析環境ではありません。要素はコンテンツを異なる方法で扱い、7つの異なる解析モードが作用します。これらのモードがmXSS脆弱性に与える影響を理解するため、以下に解説します:
- 空要素
area,base,br,col,embed,hr,img,input,link,meta,source,track,wbr
template要素template
- 生テキスト要素
script,style,noscript,xmp,iframe,noembed,noframes
- エスケープ可能な生テキスト要素
textarea,title
- 外部コンテンツ要素
svg,math
- プレーンテキスト状態
plaintext
- 通常要素
- 許可されているその他のすべてのHTML要素は通常要素です。
以下の例で解析タイプの違いを比較的簡単に示せます:
- 最初の入力は
div要素(「通常要素」)です: <div><a alt="</div><img src=x onerror=alert(1)>">- 一方、2つ目の入力は
style要素(これは「生のテキスト」)を使用した類似のマークアップです: <style><a alt="</style><img src=x onerror=alert(1)>">
解析されたマークアップを見ると、パースの違いが明確に確認できます:
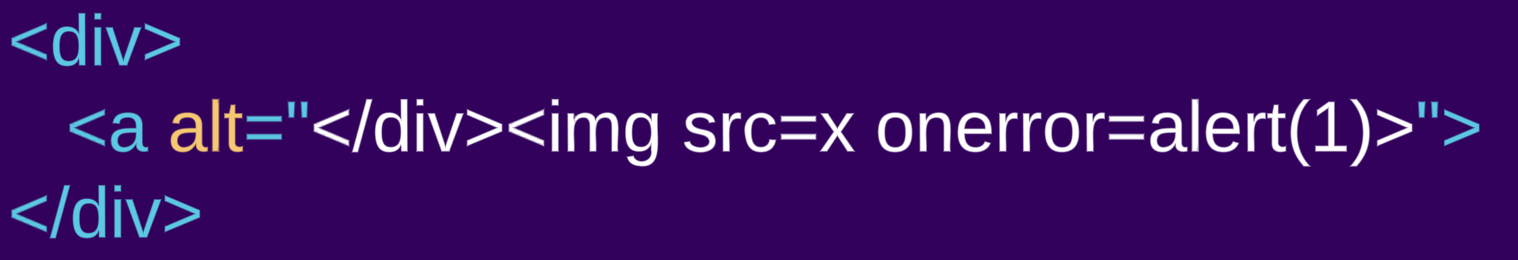

div要素の内容はHTMLとしてレンダリングされ、a要素が生成されます。閉じdivタグとimgタグのように見えるものは、実際にはa要素の属性値であり、したがってa要素のaltテキストとしてレンダリングされ、HTMLマークアップではありません。styleの例では、style要素の内容は生のテキストとしてレンダリングされるため、a要素は生成されず、いわゆる属性は通常のHTMLマークアップとなります。
外部コンテンツ要素
HTML5は、特殊なコンテンツをWebページに統合する新たな方法を導入しました。代表的な例が<svg>と<math>要素です。これらの要素は独自の名前空間を利用しており、標準HTMLとは異なる解析ルールに従います。mXSS攻撃に関連する潜在的なセキュリティリスクを軽減するには、これらの異なる解析ルールを理解することが不可欠です。
前回と同じ例を、今度は svg要素内にカプセル化して見てみましょう:
<svg><style><a alt="</style><img src=x onerror=alert(1)>">
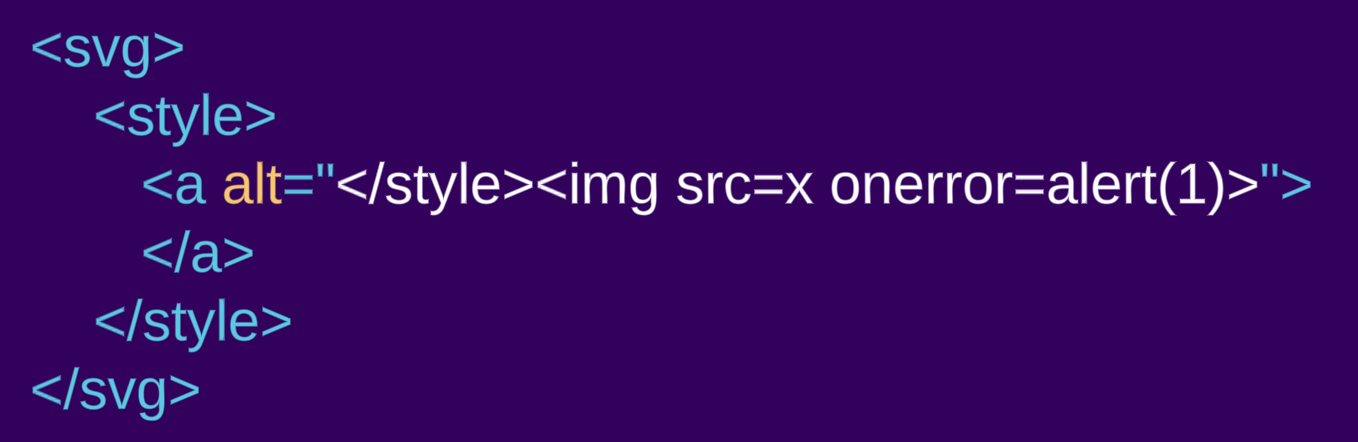
この場合、a要素が作成されていることが確認できます。style要素は別の名前空間内にあるため、「生のテキスト」解析ルールに従いません。SVGやMathMLの名前空間内に存在するときは、解析ルールが変更され、HTML言語のルールに従わなくなります。
攻撃者は、名前空間の混乱技術(DOMPurify 2.0.0 バイパスなど)を使用して、サニタイザーを操作し、ブラウザによって最終的にレンダリングされる方法とは異なる方法でコンテンツを解析させ、悪意のある要素の検出を回避することができます。
変異から脆弱性へ
多くの場合、mXSS という用語は、さまざまなサニタイザーのバイパスを包括的に指す広義の意味で使用されます。理解を深めるため、一般的な「mXSS」という用語を4つのサブカテゴリに分類します
パーサー差異
パーサー差異は通常のサニタイザーバイパスとも呼ばれますが、mXSSと表現される場合もあります。いずれにせよ、攻撃者はサニタイザーのアルゴリズムとレンダラー(例:ブラウザ)間のパーサー不一致を悪用できます。HTML解析の複雑性ゆえ、解析差異が存在しても必ずしも一方のパーサーが誤り、他方が正しいとは限りません。
例えばnoscript要素の解析ルールは次の通りです:「スクリプティングフラグが有効の場合、トークナイザーをRAWTEXT状態に切り替える。そうでない場合、トークナイザーをデータ状態のまま維持する」 (リンク) つまり、JavaScriptが無効か有効かによって、noscript要素の本文が異なる方法でレンダリングされます。JavaScriptがサニタイザー段階では有効化されず、レンダラーでは有効化されるのは論理的です。この動作は定義上間違ってはいませんが、次のようなバイパスを引き起こす可能性があります:<noscript><style></noscript><img src=x onerror=”alert(1)”>
JS無効時:

JavaScriptが有効です:

他の多くのパーサーの差異、例えば異なるHTMLバージョン、コンテンツタイプの不一致などが発生する可能性があります。
パースの往復性
パースの往復性とは、よく知られ文書化されている現象であり、次のように述べています:「このアルゴリズムの出力をHTMLパーサーでパースした場合、元のツリー構造が復元されない可能性があります。シリアル化と再パースのステップで往復しないツリー構造は、HTMLパーサー自体によっても生成される場合がありますが、そのようなケースは通常、非準拠となります。」
つまり、HTMLマークアップを解析する回数に応じて、結果のDOMツリーが変化する可能性があるということです。
仕様書に記載されている公式の例を見てみましょう:
ただし、まず理解すべき点は、form要素内に別のform要素をネストできないことです:「コンテンツモデル:フローコンテンツだが、子孫要素としてform要素を含まない」(仕様書記載通り)
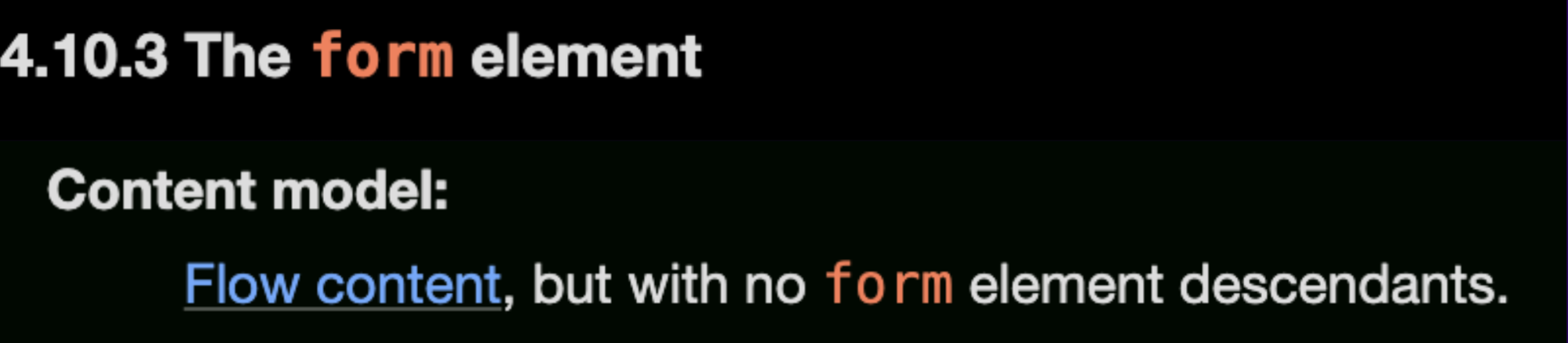
しかし、ドキュメントを読み進めると、form要素がネストされる方法の例が次のマークアップで示されています:
<form id="outer"><div></form><form id="inner"><input>
html
├── head
└── body
└── form id="outer"
└── div
└── form id="inner"
└── input</form>は閉じられていないdivのため無視され、input要素は内部のform要素に関連付けられます。このツリー構造がシリアライズされ再解析されると、<form id="inner">の開始タグは無視されるため、input要素は代わりに外側のform要素に関連付けられます。
<html><head></head><body><form id="outer"><div><form id="inner"><input></form></div></form></body></html>
html
├── head
└── body
└── form id="outer"
└── div
└── input攻撃者はこの動作を利用して、サニタイザーとレンダラーの間の名前空間の混乱を引き起こし、以下のようなバイパスを実現できます:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
クレジット @SecurityMB、詳細はこちら で解説されています。
デサニタイゼーション
デサニタイゼーションとは、アプリケーションがクライアントへ送信する前にサニタイザーの出力を改変する重大な過ちであり、本質的にサニタイザーの処理を無効化します。マークアップへのわずかな変更が最終的なDOMツリーに重大な影響を与え、サニタイゼーションのバイパスを引き起こす可能性があります。この問題は以前、Insomni'Hackでの講演や複数のブログ記事で議論しており、以下のような様々なアプリケーションの脆弱性を特定しました:
- デサニタイゼーションの落とし穴:osTicketからの顧客データ漏洩
- コード脆弱性がProtonメールを危険に晒す
- コード欠陥によるTutanotaデスクトップのリモートコード実行
- コード脆弱性がSkiffメールを危険に晒す
以下にデサニタイゼーションの例を示します。アプリケーションがサニタイザーの出力を受け取り、svg要素をcustom-svgにリネームします。これにより要素のネームスペースが変更され、再レンダリング時にXSSを引き起こす可能性があります。
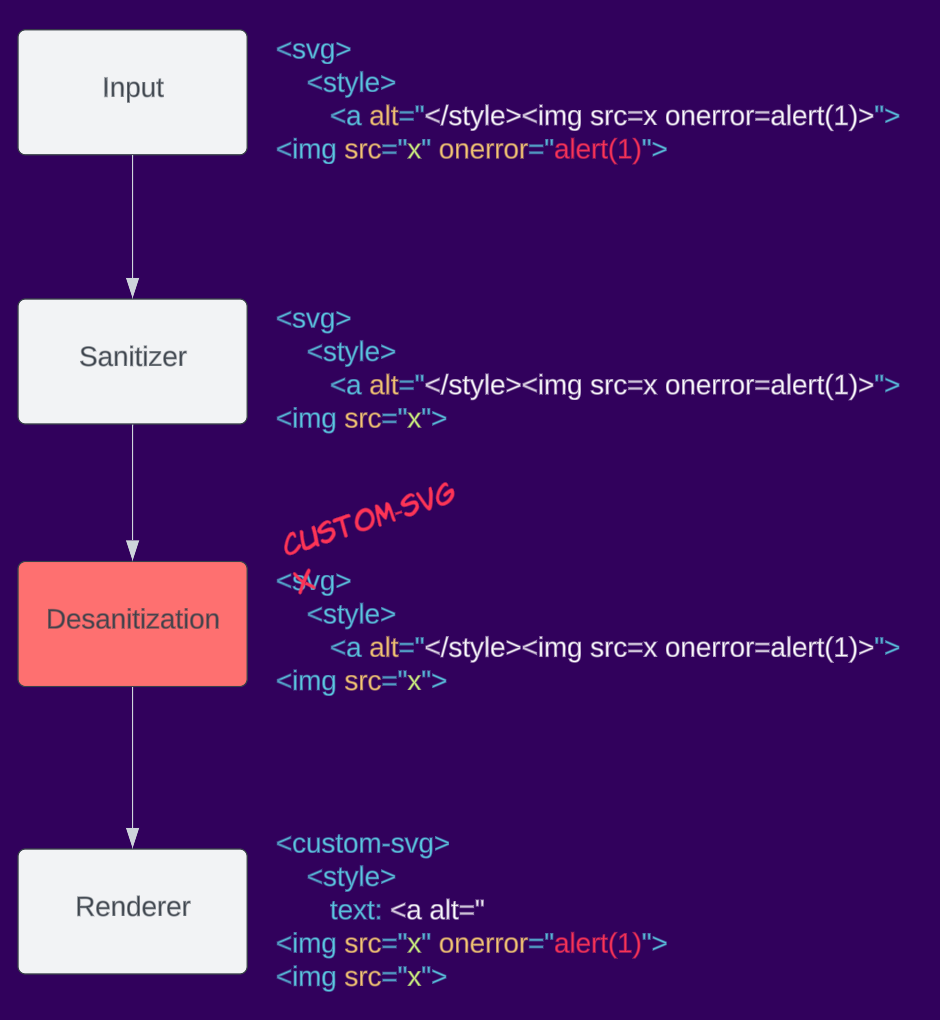
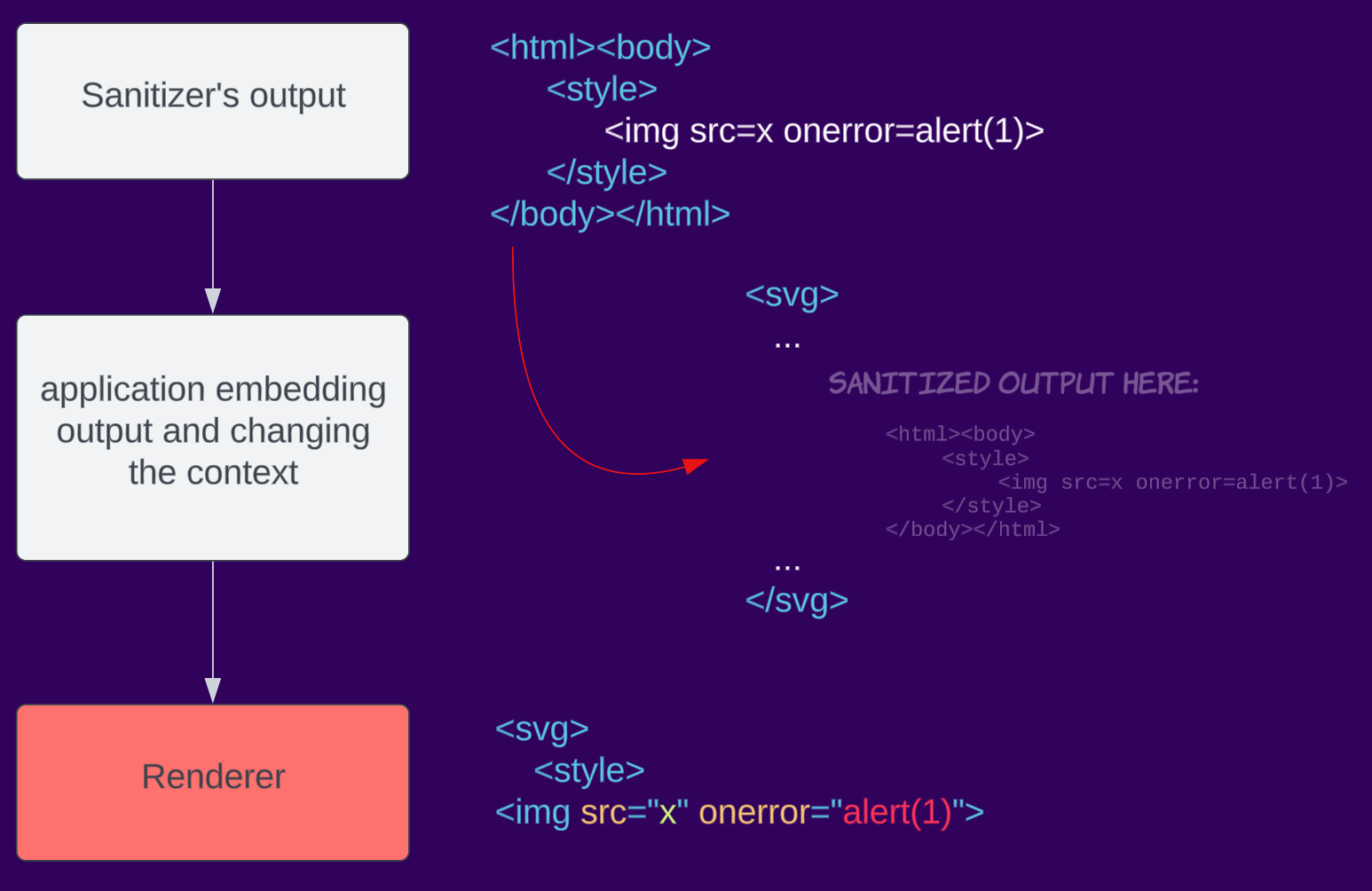
コンテキスト依存
HTMLの解析は複雑であり、コンテキストによって異なる場合があります。例えば、Firefoxではドキュメント全体の解析とフラグメント解析では異なります(チートシートのブラウザ固有セクションを参照)。ブラウザ内でのサニタイズからレンダリングへの移行を扱う際、開発者は誤ってデータがレンダリングされるコンテキストを変更し、解析の差異を引き起こし、最終的にサニタイザーをバイパスしてしまう可能性があります。サードパーティ製サニタイザーは結果が配置されるコンテキストを認識しないため、この問題に対処できません。この課題は、ブラウザが組み込みサニタイザー(Sanitizer API 取り組み)を実装することで解決される見込みです。
例えば、アプリケーションが入力をサニタイズしても、ページに埋め込む際にSVGでカプセル化すると、コンテキストがSVG名前空間に変更される場合があります。
mXSSケーススタディ
過去にはReply to calc: The Attack Chain to Compromise MailspringのようなmXSS脆弱性に関するブログ記事を公開してきましたが、mganss/HtmlSanitizer (CVE-2023-44390)、
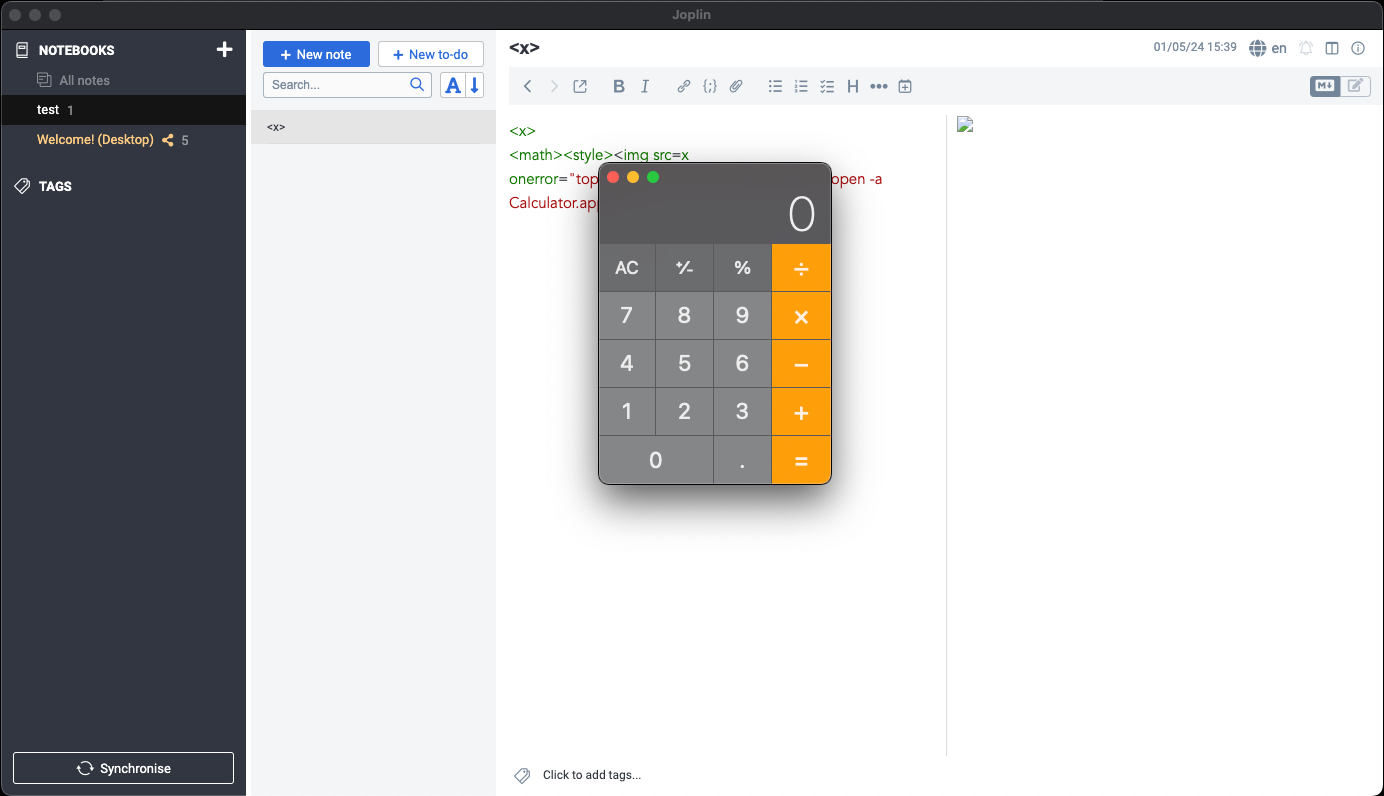
しかし今回は、Electronで書かれたデスクトップ用ノートアプリ「Joplin」(CVE-2023-33726)における単純な事例を検証します。安全でないElectron構成のため、Joplin内のJSコードはNodeの内部機能を利用でき、攻撃者がマシン上で任意のコマンドを実行することを可能にします。
この脆弱性の根源は、htmlparser2 npmパッケージを介して信頼できないHTML入力を解析するサニタイザーのパーサーにあります。このパッケージ自体、仕様準拠を重視せず速度を優先していると明言しています:「厳密なHTML仕様準拠が必要な場合はparse5を参照してください。」
このパーサーが仕様に準拠していない点を、私たちはすぐに確認しました。以下の入力から、パーサーが異なる名前空間を認識していないことがわかります。

Sanitizerのパーサーはimg要素をレンダリングしませんが、レンダラーはレンダリングします。これはパーサー差分の例であり、攻撃者は単にonerrorイベントハンドラーを追加するだけで、被害者が悪意のあるノートを開いた際に任意のコードを実行できます。
この特定の発見は@maple3142によっても独立して確認されました
緩和策
残念ながら、単純な単一の緩和策は存在しません。開発者にはこのバグクラスを深く理解し、自身のアプリケーションに応じてこの問題を緩和する方法をより適切に判断できるよう推奨します。
調査過程で、開発者がmXSS問題に対処するために採用した複数の緩和アプローチとセキュリティ対策を確認しました(チートシートにも記載あり):
クライアントサイドでのサニタイズ
- これはおそらく最も重要なルールです。DOMPurifyのようなクライアントサイドで動作するサニタイザーを使用することで、パーサー差異のリスクを回避できます。パースの複雑さと、異なるパーサー(Firefox vs Chrome vs Safariなど)へのコンテンツ提供が一般的であるため、HTMLが最終的にレンダリングされる場所とは異なる場所でパースされる場合、差異を完全に回避することは不可能です。このため、サーバーサイドのサニタイザーは失敗しやすい傾向があります。
- クライアントサイドJSフレームワークでサーバーサイドレンダリング(SSR)を使用する場合、isomorphic-dompurifyのようなライブラリを導入するのは簡単です。これらはDOMPurifyのようなクライアントサイドのサニタイザーをSSRモードで「そのまま動作させる」ことを可能にします。しかしこれを実現するために、jsdomのようなサーバーサイドHTMLパーサーも導入され、これがパーサー差異のリスクをもたらします。SSRを利用するWebアプリケーションにとって最も安全な選択肢は、ユーザーが制御するHTMLに対してSSRを無効化し、サニタイズとレンダリングをクライアントサイドのみに委ねることです。
再解析を避ける
- 「ラウンドトリップmXSS」を回避するため、アプリケーションはコンテンツをシリアライズして再レンダリングする代わりに、サニタイズ済みDOMツリーを直接ドキュメントに挿入できます。
- 注意:この手法はサニタイザーがクライアントサイドで実装されている場合にのみ有効であり、予期せぬ動作(ページの文脈に適応しないことによるコンテンツの異なるレンダリングなど)を引き起こす可能性があります。
常に生のコンテンツをエンコードまたは削除する
- mXSSの概念は、悪意のある文字列がサニタイザーでは生のテキストとしてレンダリングされ、後でHTMLとして解析される方法を見つけることであるため、サニタイザー段階で生のテキストを許可/エンコードしないことで、それをHTMLとして再レンダリングすることを不可能にします。
- 注意:これによりCSSコードなど一部の機能が破損する可能性があります。
外部コンテンツ要素をサポートしない
- サニタイザーで外部コンテンツ要素(svg/math要素とそのコンテンツを削除し、名前を変更しない)をサポートしないことで、複雑さを大幅に削減できます。
- 注記:これはmXSSを軽減するものではなく、予防措置を提供します。
将来
単純な解決策のないこの複雑な課題に、明るい未来はあるのか?
答えはイエスです。幸いにも、このバグクラスを終わらせる、あるいは少なくとも公式に対処するための数多くの提案と行動が取られています。
現在の最大の問題は、信頼できないHTML入力のサニタイズ責任がサードパーティ開発者(アプリケーション開発者やサニタイザー開発者)に委ねられている点です。この課題の複雑さと、異なるレンダラーパーサー(ユーザーが異なるブラウザを使用)への対応、進化するHTML仕様への追従が必要となる事実から、これは非現実的です。より適切な解決策は、マークアップ内に悪意のあるコンテンツが存在しないことを保証する責任をレンダラー側に負わせることです。例えばブラウザに組み込みのサニタイザーを実装すれば、これまで見られた回避策のほとんど、あるいは全てを排除できるでしょう。
Sanitizer APIイニシアチブはまさにこの目的を追求するものです。現在Web Platform Incubator Community Group(WICG)によって開発が進められており、ブラウザ自身が提供する統合された堅牢な文脈認識型サニタイザーを開発者に提供することを目指しています(パーサーの違いや再解析の必要性がなくなります)。Sanitizer APIのブラウザ間での広範な採用は、開発者による安全なHTML操作のための利用増加につながるでしょう。
この問題に対処するための別の取り組みとして、仕様の更新があります。例えば、Chromeでは現在、属性内の<および>文字をエンコードしています。
<svg><style><a alt="</style>">→ <svg><style><a alt="</style>">
HTML定義の基礎を進化させ、より安全な未来へ。
mXSSチートシート 🧬🔬
mXSSの世界で学び、研究し、革新したい方々のためのワンストップリソースとしてmXSSチートシートを作成しました。1500ページに及ぶドキュメントを読む代わりに、予期せぬHTMLの挙動を簡潔なリストで把握できるよう支援します。ユーザーの皆様には貢献していただき、この取り組みを共に推進するよう呼びかけています。
概要
mXSS(ミューテーション・クロスサイトスクリプティング)は、HTMLの処理方法に起因するセキュリティ脆弱性です。従来のXSS攻撃を防ぐ強力なフィルタを実装したWebアプリケーションであっても、mXSSはすり抜ける可能性があります。これはmXSSがHTML動作の癖を悪用し、サニタイザーを欺いて悪意のある要素を透過させるためです。
本ブログではmXSSを詳細に解説し、具体例を示しながら「mXSS」という包括的な概念を細分化し、開発者向けの対策戦略を網羅しました。この知識を武器に、開発者や研究者が今後この課題に自信を持って対処できることを願っています。
