

TL;DR overview
- The Sonar Foundation Agent is an AI-powered agentic tool that autonomously detects and remedies code quality and security issues, operating within the boundaries defined by Sonar's analysis engine.
- Unlike general-purpose AI coding assistants, the Foundation Agent grounds its fixes in verified SonarQube findings, ensuring remediation targets real issues rather than hallucinated problems.
- The agent integrates into existing CI/CD workflows, enabling automated fix proposals to be created and reviewed in pull requests—keeping humans in control of which fixes are accepted.
- Early use cases include automating remediation of well-defined, deterministic issues like hardcoded secrets, missing null checks, and common security anti-patterns identified by Sonar's rules.
Sonar Foundation Agent is a coding agent for general software issues, developed at Sonar by the former AutoCodeRover team. As of November 3, 2025, Sonar Foundation Agent scores 75% on SWE-bench Verified, while maintaining a low average cost of $1.26 and a high efficiency of 10.5 min per issue.
Implementation with the LlamaIndex framework
Sonar Foundation Agent is a tool-calling-style agent, implemented with the LlamaIndex framework. Configured with a carefully-designed system prompt, Sonar Foundation Agent receives the description of the issue to solve and then iteratively invokes tools to investigate and resolve the issue. The final output is a patch to the code in the unified diff format.
Sonar Foundation Agent has the following tools:
bash: A tool for executing arbitrary commands in bash. The tool is stateful, i.e., the same bash process is used across invocations of the tool.str_replace_editor: A tool for viewing, creating, and editing files. The edits happen by means of string replacement.find_symbols: A tool for searching the program AST for symbols, including classes, methods, and functions. This is the same AST search tool introduced in the original AutoCodeRover agent, making it easy and reliable to find relevant symbol definitions in the program.
Lesson learned: Tailoring agent autonomy
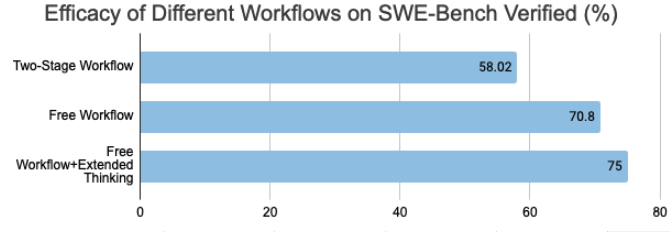
Figure 1. Efficacy increases with the level of agent autonomy
In trying to improve the efficacy of Sonar Foundation Agent, our team has conducted extensive research and experiments. During this process, it became clear to us that the key to a great agent is to match the level of autonomy with the capability of the underlying model. As shown in Figure 1, with the current powerful LLMs, the efficacy of our agent on SWE-bench Verified increases when given more autonomy.
Constrained workflow: Early-days AutoCodeRover
Back in April 2024, our team developed AutoCodeRover, which was one of the earliest coding agents. It has a clearly-defined 2-stage workflow: context retrieval, followed by patch generation. Either stage is handled by a separate agent. In the context retrieval stage, AutoCodeRover would repeatedly invoke an AST search tool to find the buggy location and accumulate relevant context, and most of the autonomy of AutoCodeRover lies in what AST searches to perform and when to stop. In the patch generation stage, AutoCodeRover would simply write a patch with the accumulated context. There is no autonomy in deciding the workflow.
The limited autonomy to AutoCodeRover was a conscious decision. At that time, the capability of LLMs to grasp a long context was limited. When we instructed a single agent to first retrieve context and then write a patch, it would have lost sight of some context collected early on when writing the patch. Moreover, oftentimes, it would not write a patch altogether. Therefore, we broke the workflow into two distinct stages: the context is first collected and summarized by a first agent, and a patch is written by a second agent. We found that the separation improved both context utilization and instruction following, boosting AutoCodeRover’s efficacy under limited LLM capability.
More autonomy in workflow and tools: Sonar Foundation Agent
This time around, while developing Sonar Foundation Agent, we re-examined AutoCodeRover’s two-stage workflow and its basis. We realized that the capability of LLMs have evolved a lot over the past year and a half, and that the agent might now benefit from a more free workflow. Therefore, we switched to a single-agent workflow. The two-stage workflow was not totally discarded. Instead, we prompted the single agent to work in several stages, including the two stages and more patch testing and validation. We were glad to find that the latest models, including GPT-5 and Claude Sonnet 4.5, are able to deal with a longer context window and follow instructions significantly better. Using the same LLM, the change in workflow resulted in an efficacy boost from about 58% (“Two-Stage Workflow” in Figure 1) to 70% (“Free Workflow” in Figure 1).
More autonomy in prompts: Leveraging thinking models
Finally, we sought to unlock the power of thinking models. In an initial attempt, we simply turned on the extended thinking of Claude Sonnet 4.5. However, the efficacy remained at about 70%. We realized that the prompt was so detailed that even with extended thinking, the agent would do largely the same things and achieve similar results. Our realization was corroborated by Claude’s official prompting guide, which says thinking models can benefit from more concise and less prescriptive prompts. In light of this, we distilled the essence of our prompt, highlighting a test-driven approach to issue resolving, while removing the overly prescriptive instructions. This improvement in prompts gave us a final boost of efficacy to 75% (“Free Workflow+Extended Thinking” in the chart above).
The journey from AutoCodeRover to the Sonar Foundation Agent offers a critical insight for the future of agentic coding: as underlying models grow more powerful, we must grant them more autonomy. Our research clearly shows that moving from a constrained, two-stage process to a "Free Workflow" and refining prompts to be less prescriptive unlocked the agent's full potential, boosting efficacy from 58% to 75%. This principle of matching agent autonomy to model capability will be foundational as we continue to push the boundaries of AI-driven software development.