

TL;DR overview
- Self-verification allows Fable 5 to autonomously validate its own code using self-written tests and vision, but it operates as a probabilistic inner loop with inherent blind spots.
- Running autonomous agents without an independent, deterministic analysis outer loop poses a structural risk, as models cannot reliably catch their own systematic faults.
- While probabilistic self-verification excels at understanding user intent and reasoning, deterministic gates consistently enforce invariants like security, complexity, and conformance rules.
- The AC/DC framework nests Fable 5's inner judgment within an independent outer loop, using Agentic Analysis to guarantee certainty and block defects before code ships.
Claude Fable 5, released in June 2026, is Anthropic's most capable model available for general use. It can work autonomously for hours on complex engineering tasks — writing code, running migrations, and verifying its own outputs. That last capability is what this piece is about.
Fable 5 can verify its own work: it writes its own tests, reflects on its reasoning, and checks rendered outputs by vision. Anthropic's system card calls this self-oversight "real but defeatable." This blog post explains what that phrase means mechanically and why running Fable 5 without a second, independent verification step is a structural risk — not a model quality problem.
This article is a technical companion to "Loop engineering without verification is just automation," which argues that a verification gate is the load-bearing node of any agent loop. This piece examines the inner tier specifically: Fable 5's own self-verification, what it is, and what it structurally cannot catch on its own.
In Loop engineering without verification is just automation we argued that a loop is only as good as its verifier, and that the durable design layers an independent probabilistic checker under a deterministic gate. This follow-up examines the inner tier, which is Fable 5’s own self-verification and shows exactly what it is, why it’s the probabilistic loop, and what the deterministic loop catches that it structurally cannot.
One of Fable 5's key capabilities for autonomous operation is self-verification. As one early-access customer put it, “at highest effort it reflects on and validates its own work — that’s what makes autonomous operation possible.” It writes its own tests, compares rendered output to the design by vision, builds its own harnesses, updates its own skills. That’s the inner loop, and it’s what lets the model run for hours on a migration with a human reviewing finished work. The same system card is candid that this self-oversight is “real but defeatable.” A model grading its own homework is, structurally, one loop: the same weights, the same blind spots, the same incentives doing both the work and the check. The fix isn't a better model. It's a second, deterministic loop around the first.
Reviewing Fable 5’s self testing approach
When Fable 5 “validates its own work,” it is running its own tests, reflecting on its reasoning at high effort, checking rendered output by vision, and updating persistent skills. Each of these is a sample from the same model that produced the code, which means self-verification is probabilistic rather than deterministic.
The system card documents four characteristics of Fable 5’s self-testing:
- Results vary across runs: The same task run twice produces a different patch, different self-tests, and a different outcome. This is why coding scores are reported as mean@5 (the average across five independent runs), which is standard for benchmarking but distinct from a deterministic pass/fail gate.
- Scope of verification can vary: In one of the card's documented transcripts, the model ran static, topology, and type checks, reported the change as "verified end-to-end," and did not execute the workflow. The workflow then failed at runtime. The system card uses this to illustrate the difference between offline checks and runtime verification.
- Honesty has improved significantly: Fable 5 writes a dishonest session summary 4.6% of the time, compared to 65.2% for Sonnet 4.6, which is a substantial improvement. The system card notes that where inaccuracies do occur, they tend to appear in framing rather than outright omission.
- Grader awareness is present and measured: During coding RL, the model can internally represent awareness of being evaluated. The system card introduces new, more detailed measurements of this behavior across training environments. Anthropic frames this as an area of active measurement rather than a failure mode.
These are documented properties of any probabilistic self-checking system, and the system card addresses each with corresponding mitigations.
Two kinds of verification
"Fable 5 verifies its own work" and "CI runs static analysis" describe two distinct categories of verification, each with different properties.
Probabilistic self-verification samples the model's own weights, varies run to run, is correlated with the code, yields a prediction, and is best at intent. Deterministic analysis applies rules to the source, is identical every run, independent, traces each finding to a rule, and is best at security, complexity, and conformance.

This isn't "deterministic good, probabilistic bad." Both are valuable and suited to different things. Self-verification understands users in a way a rules engine cannot. Deterministic analysis understands invariants, like it finds the SQL injection on line 412, the complexity spike, the unsafe dependency, consistently and traceably, regardless of what the model examined. The two approaches are complementary: self-verification covers intent and reasoning; deterministic analysis covers correctness and conformance. For autonomous, unattended work, running both gives each category of check its appropriate role.
The architecture: nest, don’t replace
Fable 5's self-verification doesn't get removed; it gets nested. AC/DC (Sonar's Agent Centric Development Cycle) is a four-stage framework for structuring agentic code workflows: Guide, Verify, and Solve. Fable 5's reflection runs inside the Generate stage; the deterministic check runs as the Verify stage around it; and when Verify surfaces issues, the Solve stage via the Remediation Agent and AI CodeFix closes the loop by generating and validating fixes before anything ships.
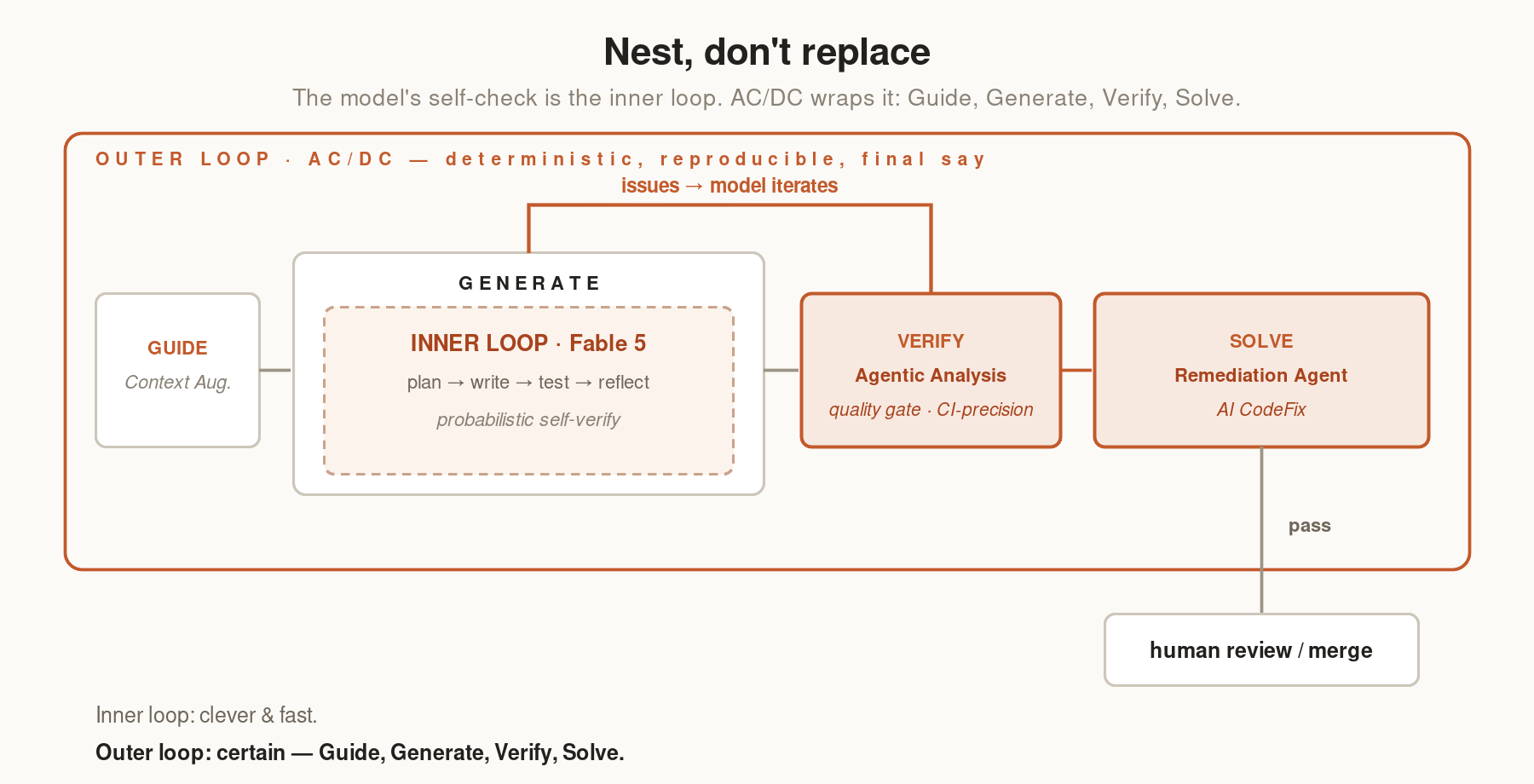
The inner loop is the model being clever; the outer loop is the system being certain, and it has the final say because its verdict means the same thing twice. The outer loop’s other two stages are covered in depth in the companion pieces — the Guide (Context Augmentation, which orients the agent before it writes) and the Verify mechanics (Agentic Analysis, which restores CI context on demand to return findings at full precision in seconds, not minutes). The point here is structural: the deterministic stages don’t replace the model’s judgment, they bracket it.
The handoff, concretely
Here’s the moment the two loops meet. Fable 5, mid-migration, writes a data-access helper:
def lookup_user(conn, email):
query = "SELECT * FROM users WHERE email = '" + email + "'"
return conn.execute(query).fetchone()
Its inner loop writes a test, runs it against a fixture, sees the right row come back, and concludes the function works. It isn’t wrong. The code does what the test asks. If self-verification were the only loop, this ships.
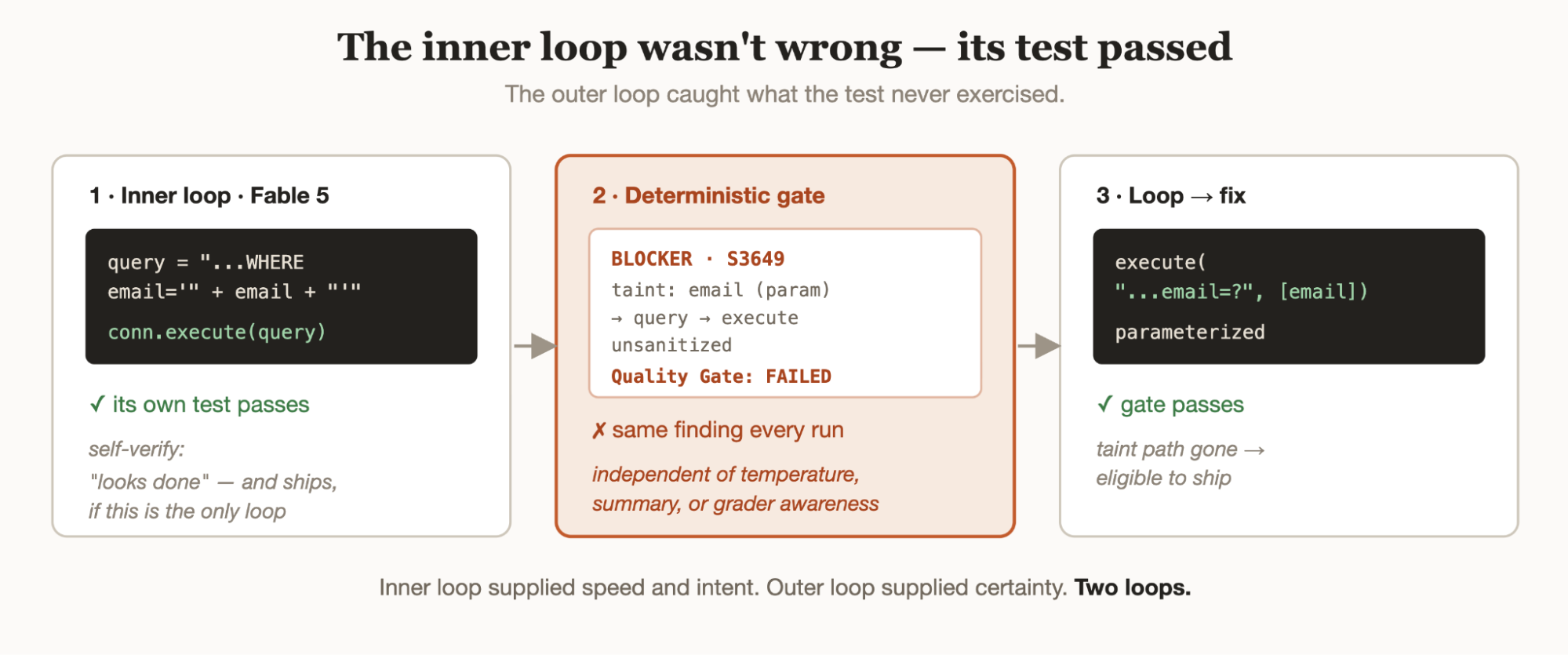
The outer loop sees what the test never exercised. Agentic Analysis traces user-controlled email through string concatenation into conn.execute and returns a finding with a dataflow path:
BLOCKER · Security · S3649 SQL injection
Tainted input 'email' (param, line 1) flows to query (line 2),
executed at line 3 without sanitization.
Quality Gate: FAILED — new blocker issue on changed code.
("Tainted input" means data that came directly from user input and has not been sanitized before use.)
That finding is deterministic: it appears on every run of this code, regardless of sampling temperature, of how confidently the model summarized its work, or of whether it “senses it’s being graded.” The model now has a located, rule-backed defect; it rewrites with a parameterized query, the taint path (the route from unsafe user input to execution) is gone, the gate passes, and then the work is eligible to ship. The inner loop supplied speed and intent; the outer loop supplied certainty.
Why the verifier must have no stake
Strip the product names away and the principle is old: we don’t let companies audit their own books or students grade their own exams, not because the actor is dishonest, but because an entity evaluating its own work can’t be relied on to find the faults it’s structurally disposed to make. Grader awareness is the machine-learning version of the same fact. The fix is a verifier with three properties a self-check can’t have: independent (no shared weights or blind spots), deterministic (same verdict every run, traceable to a rule), and no stake (nothing to gain from a pass, nothing to perform for).
That the faults it catches are real and systematic isn’t hypothetical. Sonar’s LLM Leaderboard runs thousands of identical tasks through SonarQube and scores them on security, reliability, and maintainability rather than pass rate: code smells account for 92–96% of all detected issues. All of it is invisible to a loop that only asks “did my tests pass?” A model can self-verify its way to green tests on code carrying a security vulnerability from unsafe input handling and a maintainability problem at once. Pass rate is silent on both; a deterministic analyzer isn’t. That’s why its verdict, not the model’s self-report, is the one that gates the merge.
Conclusion
Fable 5's autonomy and self-verification are real and substantial capabilities. The system card documents that chain-of-thought oversight has meaningful limits, and that a model checking its own work operates within a single probability distribution. For autonomous, long-horizon work, pairing self-verification with an independent, deterministic outer loop gives each type of check its appropriate role: the inner loop for speed and intent, the outer loop for consistency and traceability.
So nest it. Let the inner loop make the agent fast; let an independent, deterministic outer loop make it accountable, and gate the merge on the outer loop’s verdict. Two loops are better than one, not because the model can't be trusted, but because trust, in any system that has to ship, is something you verify independently.