

TL;DR overview
- Choosing the right LLM for Java development requires evaluating not just benchmark scores but real-world code quality metrics including maintainability, security, and adherence to Java idioms.
- LLMs vary significantly in their Java code quality: some produce idiomatic, well-structured code while others generate verbose, error-prone, or stylistically inconsistent output that increases review burden.
- Static analysis with SonarQube provides an objective lens for evaluating LLM-generated Java code, measuring the number and severity of issues introduced per unit of code produced.
- Teams should test candidate LLMs against their own codebases and quality standards—not just on generic benchmarks—before committing to a specific tool for Java development workflows.
When evaluating a new AI model, ensuring the code compiles and executes is only the baseline. Experienced developers know that functionality is just the first step; the true standard for production-ready software is code that is reliable, maintainable, and secure.
Analysis of over a dozen LLMs in the latest Sonar Leaderboard data—covering over 4,400 tasks —reveals critical insights into AI model performance.
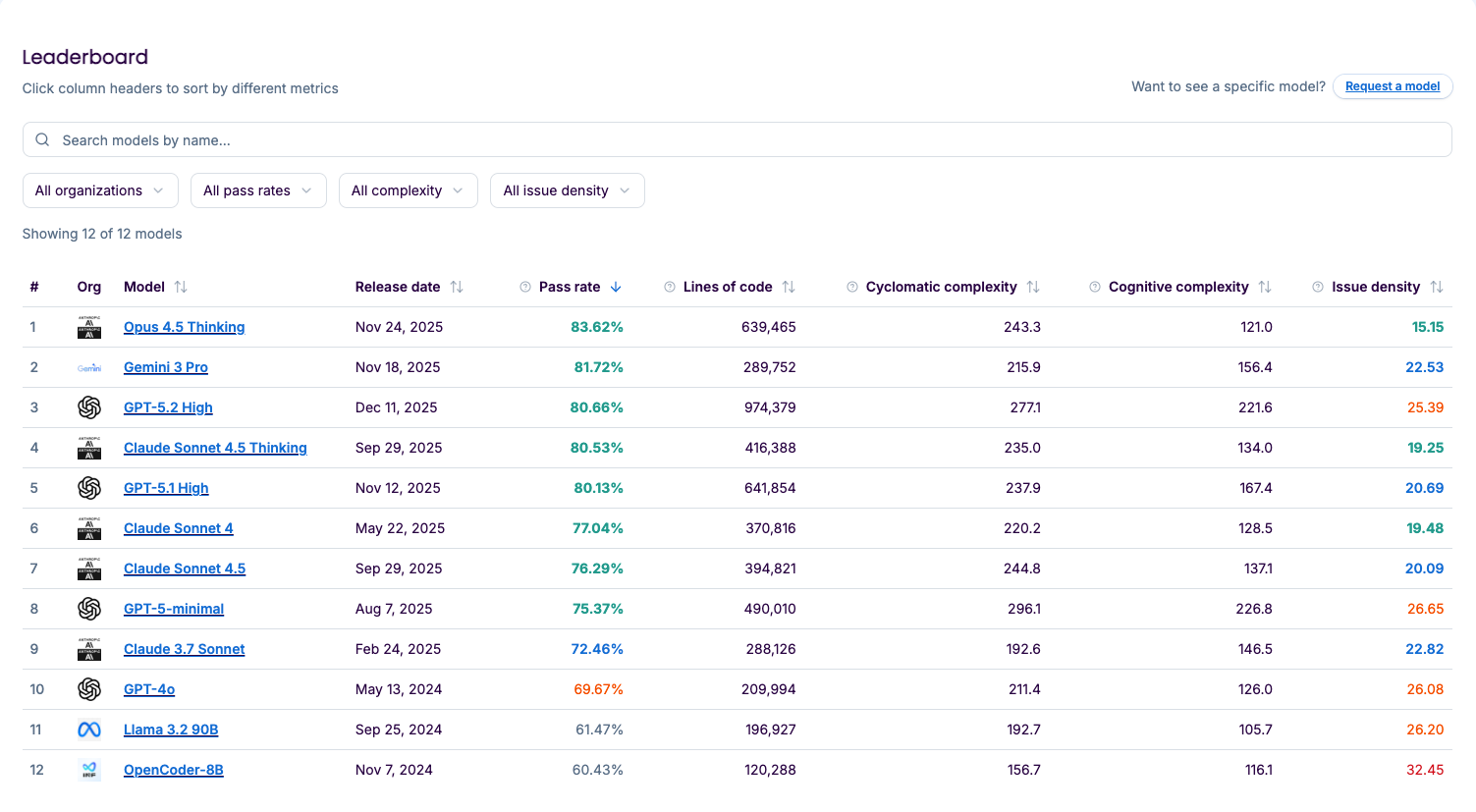
An important detail: The Sonar Leaderboard has evolved rapidly to match the pace of AI innovation. We have expanded our analysis from five initial models to 16, covering the latest wave of tools including new reasoning models and the Gemini family. With this broader dataset, the gap in code quality is undeniable.
Our data shows that even top-tier models do not consistently output production-ready code. Here are the detailed findings.
The bloatware trap: precision versus verbosity
A revealing insight from the leaderboard is the massive disparity in the volume of code generated by different LLMs to solve identical problems. .
We have two contenders with a very similar success rate (Pass Rate) (~81%), but with opposite approaches:
- Gemini 3 Pro: Solves the problem set with ~289k lines of code.
- GPT-5.2 High: Needs almost 1 million lines (974k LOC) for the same thing.
Why should you care? Because the verbose model could add unnecessary boilerplate code and avoid using modern Java features that make it significantly harder to read and maintain..
Code face-off: filtering a list
Based on the cyclomatic complexity metrics from the report, this is how the code generated by these model profiles would potentially look:
What you could expect from a "verbose" model (GPT-5.2 High style): They usually add a lot of unnecessary defense, classic loops, and high complexity.
// ❌ Simulated example of a model with high verbosity/complexity
public List<String> filterValidUsers(List<User> users) {
List<String> validNames = new ArrayList<>();
if (users != null) {
for (User u : users) {
if (u != null) {
try {
String name = u.getName();
if (name != null && !name.trim().isEmpty()) {
validNames.add(name);
}
} catch (Exception e) {
// Defensive try-catch inside a loop... bad idea 🤦♂️
continue;
}
}
}
}
return validNames;
}What an "efficient" model would tend to generate (Gemini 3 Pro / OpenCoder style): Direct, readable, and using the Streams API correctly.
// ✅ Simulated example of an optimized and concise model
public List<String> filterValidUsers(List<User> users) {
if (users == null) return Collections.emptyList();
return users.stream()
.map(User::getName)
.filter(name -> name != null && !name.isBlank())
.toList(); // Java 16+ style
}Which model would you rather be responsible for in six months? The answer is obvious: you want the one that is well-documented, testable, and maintainable.
Security: Distinguishing bugs from open doors
Intelligence does not guarantee safety. The assumption that "smarter" models automatically write more secure code is a dangerous one.
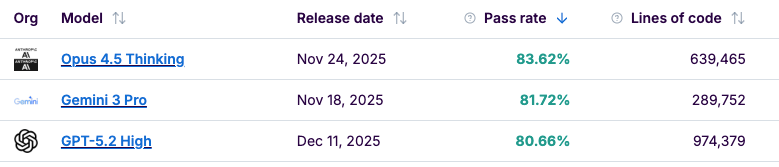
The leaderboard tracks issue density to quantify this risk. Models like Opus 4.5 Thinking have a very low density (15.15), while others like Llama 3.2, GPT 5 and 4o can go over 26 issues/kLOC. But the consequential part is not the quantity, it is the criticality.
The danger of "blockers"
Newer models often prioritize rapid string construction over security best practices, reintroducing vulnerabilities like SQL injection that were previously considered solved problems.
Example: Database queries
A model with high issue density could generate code that prioritizes building the String quickly rather than security:
// ❌ Critical Security Hotspot (SQL Injection)
// Typical of models that don't "think" (Chain of Thought) before writing
public List<User> search(String username) {
String query = "SELECT * FROM users WHERE name = '" + username + "'";
return entityManager.createNativeQuery(query, User.class).getResultList();
}While a secure model (like Opus 4.5 Thinking) would tend to use Prepared Statements by default:
// ✅ Secure Code
public List<User> search(String username) {
String query = "SELECT * FROM users WHERE name = :username";
return entityManager.createNativeQuery(query, User.class)
.setParameter("username", username)
.getResultList();
}Pro tip: If you use a model with high issue density (>25), assume there are vulnerabilities. Running a comprehensive code scanner (like SonarQube) before accepting the PR will help to mitigate that.
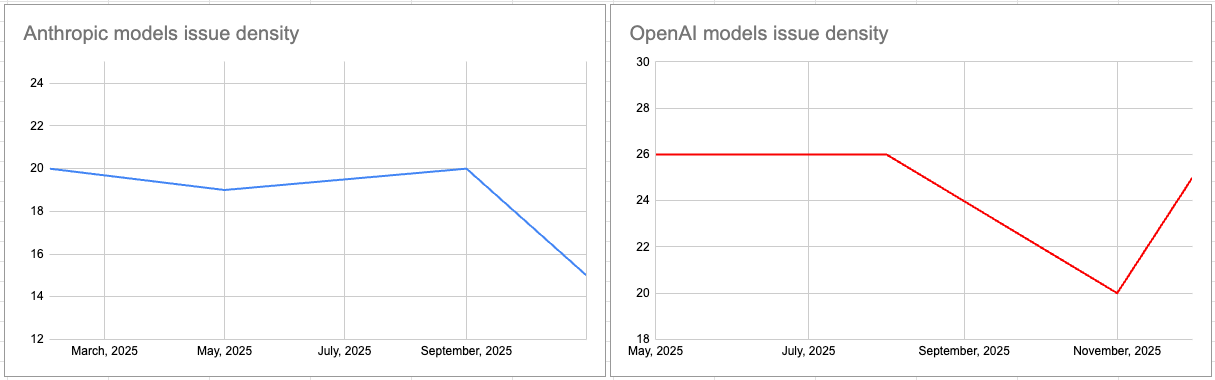
Difference in terms of issue density on the main model of each organization:
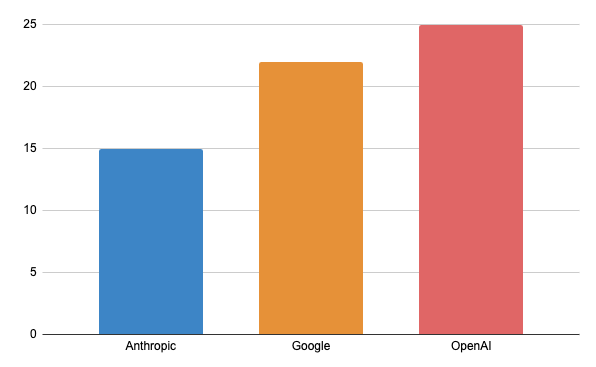
"Newer" does not guarantee "better code"
There is a common assumption that a newer version (v5) will always produce higher quality code than its predecessor (v4). Sonar's data says: "Not necessarily!"
Look at the regressions in technical quality:
- GPT-4o (May '24): Issue density of 26.08.
- GPT-5-minimal (Aug '25): Issue density of 26.65.
Sometimes, new models reintroduce basic code smells, like generic exception handling, just to "get by" and give you a quick answer.
// 🤢 The classic "Smell" that usually reappears in rushed models
try {
processData();
} catch (Exception e) {
// Catching 'Exception' is lazy and hides real errors
e.printStackTrace();
}
The summary: Which model should I use for Java?
To move from "vibe coding" to production-ready code, we recommend choosing models based on the complexity and security requirements of the task.
For business logic and security: Opus 4.5 Thinking
It is the current leaderboard leader with the highest pass rate.
- Pass rate: 83.62% (The highest).
- Issue density: 15.15 Issues/kLOC (The safest).
- Drawback: it’s a slow model, so not appropriate for small coding fixes.
Use it where you cannot afford errors, and the task is complex enough. It introduces the least technical debt.
For "day to day" and maintenance: Gemini 3 Pro
The balanced option.
- Efficiency: Very few lines of code (low verbosity).
- Quality: Maintains an elite pass rate (>81%).
- Verdict: Ideal for generating tests, scripts, or standard features where you want clean and easy-to-read code for your human colleagues.
For extreme logic cases: GPT-5.2 High
- Pros: Solves very hard problems.
Cons: Be prepared to refactor a lot of verbose code and clean bad smells.
Final note
Don't let the pass rate fool you. Code that runs but is full of security holes or excessive complexity is a future liability. Consider verifying AI-generated code with a comprehensive code scanner like SonarQube to help ensure your commits are production-ready.