

El cross-site scripting (XSS) es un tipo de vulnerabilidad muy conocido que se produce cuando un atacante puede inyectar código JavaScript en una página vulnerable. Cuando una víctima inconsciente visita la página, el código inyectado se ejecuta en la sesión de la víctima. El impacto de este ataque puede variar en función de la aplicación, desde ningún impacto empresarial hasta la apropiación de cuentas (ATO), la fuga de datos o incluso la ejecución remota de código (RCE).
Existen varios tipos de XSS, como el reflejado, el almacenado y el universal. Pero en los últimos años, la clase de mutación de XSS se ha convertido en un temido por eludir los sanitizadores, como DOMPurify, Mozilla bleach, Google Caja y otros, lo que afecta a numerosas aplicaciones, incluida la búsqueda de Google. A día de hoy, vemos muchas aplicaciones que son susceptibles a este tipo de ataques.
Pero, ¿qué es mXSS?
(También exploramos este tema en nuestra charla Insomnihack 2024: Beating The Sanitizer: Why You Should Add mXSS To Your Toolbox).
Antecedentes
Si eres desarrollador web, probablemente hayas integrado o incluso implementado algún tipo de desinfección para proteger tu aplicación de los ataques XSS. Pero se sabe poco sobre lo difícil que es crear un desinfectante HTML adecuado. El objetivo de un sanitizador HTML es garantizar que el contenido generado por el usuario, como la entrada de texto o los datos obtenidos de fuentes externas, no suponga ningún riesgo para la seguridad ni altere la funcionalidad prevista de un sitio web o una aplicación.
Uno de los principales retos a la hora de implementar un sanitizador HTML radica en la naturaleza compleja del propio HTML. El HTML es un lenguaje versátil con una amplia gama de elementos, atributos y combinaciones potenciales que pueden afectar a la estructura y el comportamiento de una página web. Analizar y desglosar el código HTML con precisión, conservando al mismo tiempo su funcionalidad prevista, puede ser una tarea abrumadora.
HTML
Antes de entrar en el tema del mXSS, echemos primero un vistazo al HTML, el lenguaje de marcado que constituye la base de las páginas web. Es fundamental comprender la estructura del HTML y cómo funciona, ya que los ataques mXSS (mutación de Cross-Site Scripting) utilizan las peculiaridades y complejidades del HTML.
El HTML se considera un lenguaje tolerante debido a su naturaleza indulgente cuando encuentra errores o código inesperado. A diferencia de algunos lenguajes de programación más estrictos, el HTML da prioridad a la visualización del contenido, incluso si el código no está perfectamente escrito. Así es como se manifiesta esta tolerancia:
Cuando se renderiza un marcado defectuoso, en lugar de bloquearse o mostrar un mensaje de error, los navegadores intentan interpretar y corregir el HTML lo mejor posible, incluso si contiene errores sintácticos menores o elementos que faltan. Por ejemplo, al abrir el siguiente marcado en el navegador <p>test se ejecutará como se espera a pesar de que falte una etiqueta p de cierre. Al observar el código HTML de la página final, podemos ver que el analizador corrigió nuestro marcado defectuoso y cerró el elemento p por sí mismo: <p>test</p>.
Por qué es tolerante:
- Accesibilidad: la web debe ser accesible para todos, y los errores menores en HTML no deben impedir que los usuarios vean el contenido. La tolerancia permite que una gama más amplia de usuarios y desarrolladores interactúen con la web.
- Flexibilidad: el HTML suele ser utilizado por personas con diferentes niveles de experiencia en codificación. La tolerancia permite cierta imprecisión o errores sin romper completamente la funcionalidad de la página.
- Compatibilidad con versiones anteriores: la web está en constante evolución, pero muchos sitios web existentes se han creado con estándares HTML más antiguos. La tolerancia garantiza que estos sitios más antiguos puedan seguir mostrándose en los navegadores modernos, incluso si no cumplen con las últimas especificaciones.
Pero, ¿cómo sabe nuestro analizador HTML de qué manera «corregir» un marcado defectuoso? ¿Debería <a><b> convertirse en<a></a><b></b> o en <a><b></b></a> ?
Para responder a esta pregunta, existe una especificación HTML bien documentada, pero, lamentablemente, todavía hay algunas ambigüedades que dan lugar a diferentes comportamientos de análisis HTML, incluso entre los principales navegadores actuales.
Mutación
De acuerdo, el HTML puede tolerar el marcado defectuoso, ¿pero qué relevancia tiene esto?
La M de mXSS significa «mutación», y la mutación en HTML es cualquier tipo de cambio realizado en el marcado por una u otra razón.
- Cuando un analizador corrige un marcado incorrecto (
<p>test→<p>test</p>), eso es una mutación. - Normalizar las comillas de los atributos (
<a alt=test>→<a alt=”test”>), eso es una mutación. - Reorganizar elementos (
<table><a>→<a></a><table></table>), eso es una mutación - Y así sucesivamente...
mXSS aprovecha este comportamiento para eludir la desinfección. Mostraremos ejemplos en los detalles técnicos.
Antecedentes del análisis sintáctico de HTML
Resumir el análisis sintáctico de HTML, un estándar de 1500 páginas, en una sola sección no es realista. Sin embargo, debido a su importancia para comprender en profundidad mXSS y cómo funcionan las cargas útiles, debemos cubrir al menos algunos temas importantes. Para facilitar las cosas, hemos desarrollado una hoja de referencia de mXSS (que aparecerá más adelante en este blog) que condensa el voluminoso estándar en un recurso más manejable para investigadores y desarrolladores.
Diferentes tipos de análisis de contenido
HTML no es un entorno de análisis único para todos. Los elementos manejan su contenido de manera diferente, con siete modos de análisis distintos en juego. Exploraremos estos modos para comprender cómo influyen en las vulnerabilidades mXSS:
- elementos vacíos
área,base,br,col,embed,hr,img,input,link,meta,source,track,wbr
- el elemento
plantillaplantillaElementos de texto sin formato
- script,
style,noscript,xmp,iframe,noembed,noframesElementos de texto sin formato escapables
- área de texto,
títuloElementos de contenido externo
- Elementos de contenido externo
svg,math
- Estado de texto sin formato
plaintext
- Elementos normales
- Todos los demás elementos HTML permitidos son elementos normales.
Podemos demostrar con bastante facilidad la diferencia entre los tipos de análisis sintáctico utilizando el siguiente ejemplo:
- Nuestra primera entrada es un elemento
div, que es un elemento «normal»: <div><a alt="</div><img src=x onerror=alert(1)>">- Por otro lado, la segunda entrada es un marcado similar que utiliza el elemento
styleen su lugar (que es un «texto sin formato»): <style><a alt="</style><img src=x onerror=alert(1)>">
Al observar el marcado analizado, podemos ver claramente las diferencias de análisis:
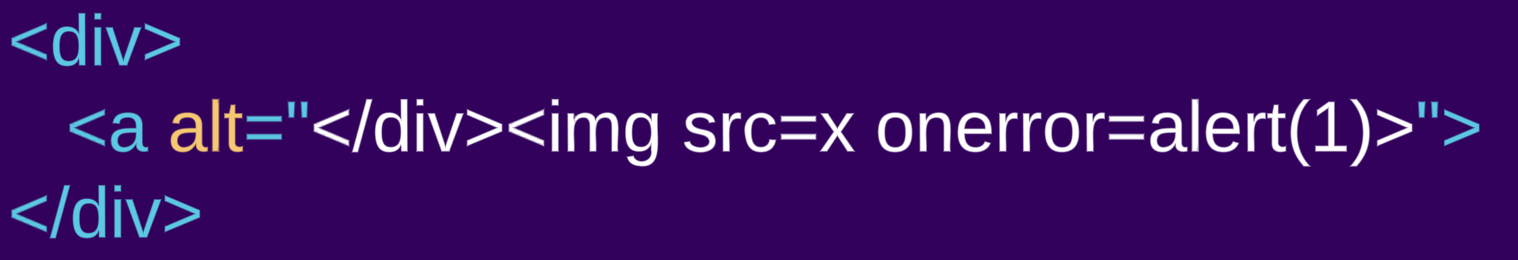

El contenido del elemento div se representa como HTML, se crea un elemento a. Lo que parece ser una etiqueta de cierre div y una etiqueta img es en realidad un valor de atributo del elemento a, por lo que se representa como texto alt para el elemento a y no como marcado HTML. En el ejemplo style, el contenido del elemento style se representa como texto sin formato, por lo que no se crea ningún elemento a y el supuesto atributo es ahora un marcado HTML normal.
Elementos de contenido externo
HTML5 introdujo nuevas formas de integrar contenido especializado en las páginas web. Dos ejemplos clave son los elementos <svg> y <math>. Estos elementos aprovechan espacios de nombres distintos, lo que significa que siguen reglas de análisis diferentes en comparación con el HTML estándar. Comprender estas diferentes reglas de análisis es crucial para mitigar los posibles riesgos de seguridad asociados con los ataques mXSS.
Veamos el mismo ejemplo que antes, pero esta vez encapsulado dentro de un elemento svg:
<svg><style><a alt="</style><img src=x onerror=alert(1)>">
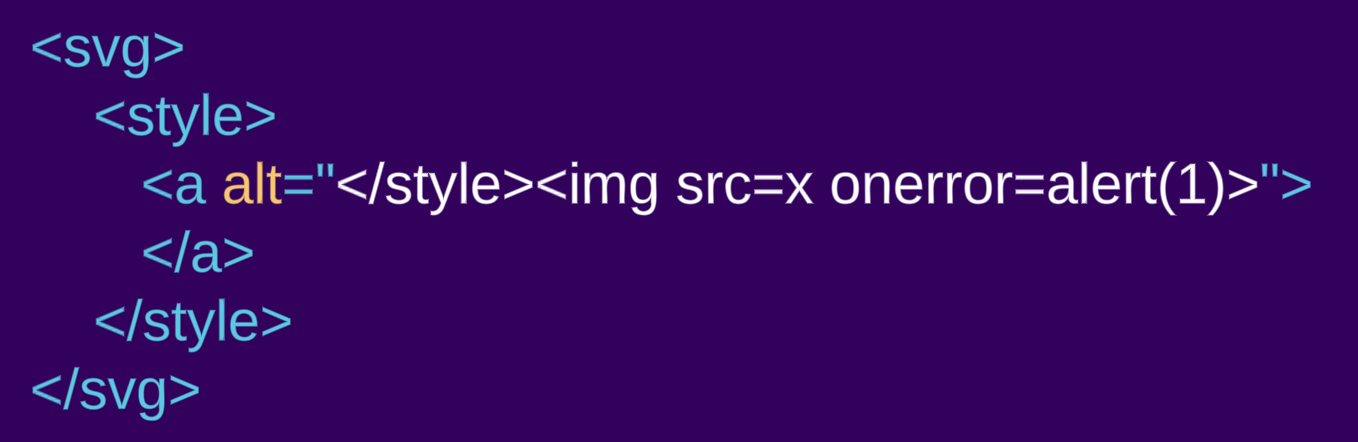
En este caso, vemos que se crea un elemento a. El elemento style no sigue las reglas de análisis de «texto sin formato», ya que se encuentra dentro de un espacio de nombres diferente. Cuando reside dentro de un espacio de nombres SVG o MathML, las reglas de análisis cambian y ya no siguen el lenguaje HTML.
Mediante técnicas de confusión de espacios de nombres (como DOMPurify 2.0.0 bypass), los atacantes pueden manipular el sanitizador para analizar el contenido de una forma diferente a como lo renderizará finalmente el navegador, evadiendo así la detección de elementos maliciosos.
De las mutaciones a las vulnerabilidades
A menudo, el término mXSS se utiliza de forma amplia para referirse a diversas formas de eludir el sanitizador. Para una mejor comprensión, dividiremos el término general «mXSS» en cuatro subcategorías diferentes
Diferencias entre analizadores
Aunque las diferencias entre analizadores pueden denominarse elusión habitual del sanitizador, a veces se denominan mXSS. En cualquier caso, un atacante puede aprovechar una discrepancia entre el algoritmo del sanitizador y el del renderizador (por ejemplo, el navegador). Debido a la complejidad del análisis sintáctico de HTML, tener diferencias de análisis sintáctico no significa necesariamente que un analizador sintáctico sea incorrecto y el otro correcto.
Tomemos, por ejemplo, el elemento noscript, cuya regla de análisis sintáctico es: «Si la bandera de scripting está habilitada, cambie el tokenizador al estado RAWTEXT. De lo contrario, deje el tokenizador en el estado de datos». (enlace) Esto significa que, dependiendo de si JavaScript está desactivado o activado, el cuerpo del elemento noscript se renderiza de forma diferente. Es lógico que JavaScript no esté activado en la etapa del desinfectante, pero sí lo estará en el renderizador. Este comportamiento no es incorrecto por definición, pero podría provocar elusión, como por ejemplo: <noscript><style></noscript><img src=x onerror=”alert(1)”>
JS desactivado:

JS habilitado:

Podrían producirse muchas otras diferencias entre analizadores, como diferentes versiones de HTML, discrepancias en el tipo de contenido y otras.
Análisis de ida y vuelta
El análisis de ida y vuelta es un fenómeno bien conocido y documentado que dice lo siguiente: «Es posible que el resultado de este algoritmo, si se analiza con un analizador HTML, no devuelva la estructura de árbol original. Las estructuras de árbol que no realizan un paso de serialización y reanálisis de ida y vuelta también pueden ser producidas por el propio analizador HTML, aunque estos casos suelen ser no conformes».
Esto significa que, según el número de veces que analicemos un marcado HTML, el árbol DOM resultante podría cambiar.
Echemos un vistazo al ejemplo oficial proporcionado en la especificación:
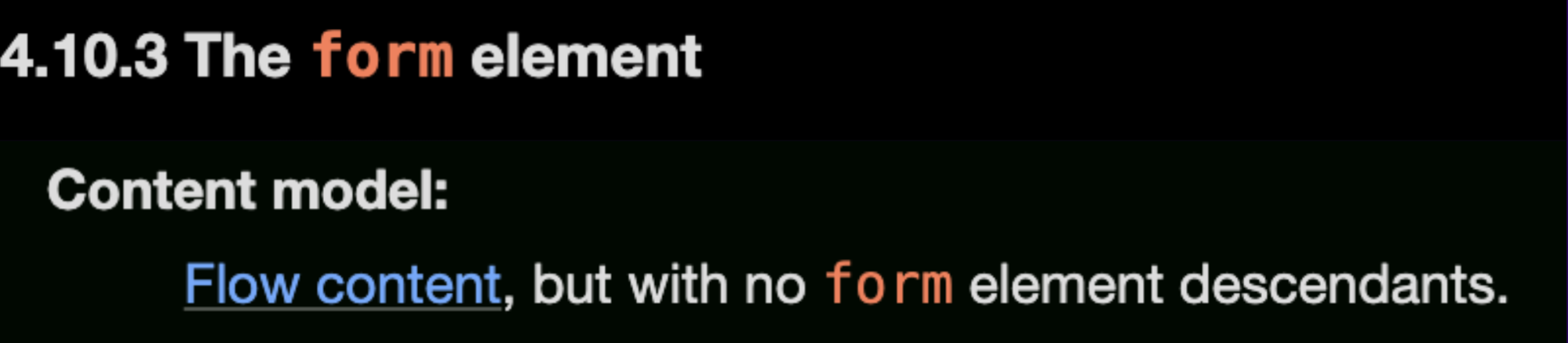
Pero primero, debemos entender que un elemento form no puede tener otro form anidado dentro de él: «Modelo de contenido: contenido de flujo, pero sin elementos descendientes de formulario.» (tal y como se describe en las especificaciones)
Pero si seguimos leyendo la documentación, nos dan un ejemplo de cómo se pueden anidar los elementos form mediante el siguiente marcado:
<form id="outer"><div></form><form id="inner"><input>
html
├── head
└── body
└── form id="outer"
└── div
└── form id="inner"
└── inputEl </form> se ignora debido al div sin cerrar y el elemento input se asociará con el elemento form interno. Ahora bien, si esta estructura de árbol se serializa y se vuelve a analizar, la etiqueta de inicio <form id="inner"> se ignorará, por lo que el elemento input se asociará con el elemento form externo.
<html><head></head><body><form id="outer"><div><form id="inner"><input></form></div></form></body></html>
html
├── head
└── body
└── form id="outer"
└── div
└── inputLos atacantes pueden aprovechar este comportamiento para crear confusión en el espacio de nombres entre el sanitizador y el renderizador, lo que da lugar a elusiones como:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
Crédito @SecurityMB, tratado en profundidad aquí.
Desanilización
La desanilización es un error crucial que cometen las aplicaciones cuando interfieren en la salida del desinfectante antes de enviarla al cliente, lo que esencialmente deshace el trabajo del desinfectante. Cualquier pequeño cambio en el marcado podría tener un gran impacto en el árbol DOM final, lo que daría lugar a una elusión de la desinfección. Ya hemos tratado este tema anteriormente en una charla en Insomni'Hack y en varias entradas de blog, donde identificamos vulnerabilidades en diversas aplicaciones, entre ellas:
- Pitfalls of Desanitization: Leaking Customer Data from osTicket
- Las vulnerabilidades del código ponen en riesgo los correos electrónicos de Proton
- Ejecución remota de código en Tutanota Desktop debido a un fallo en el código
- Las vulnerabilidades del código ponen en riesgo los correos electrónicos de Skiff
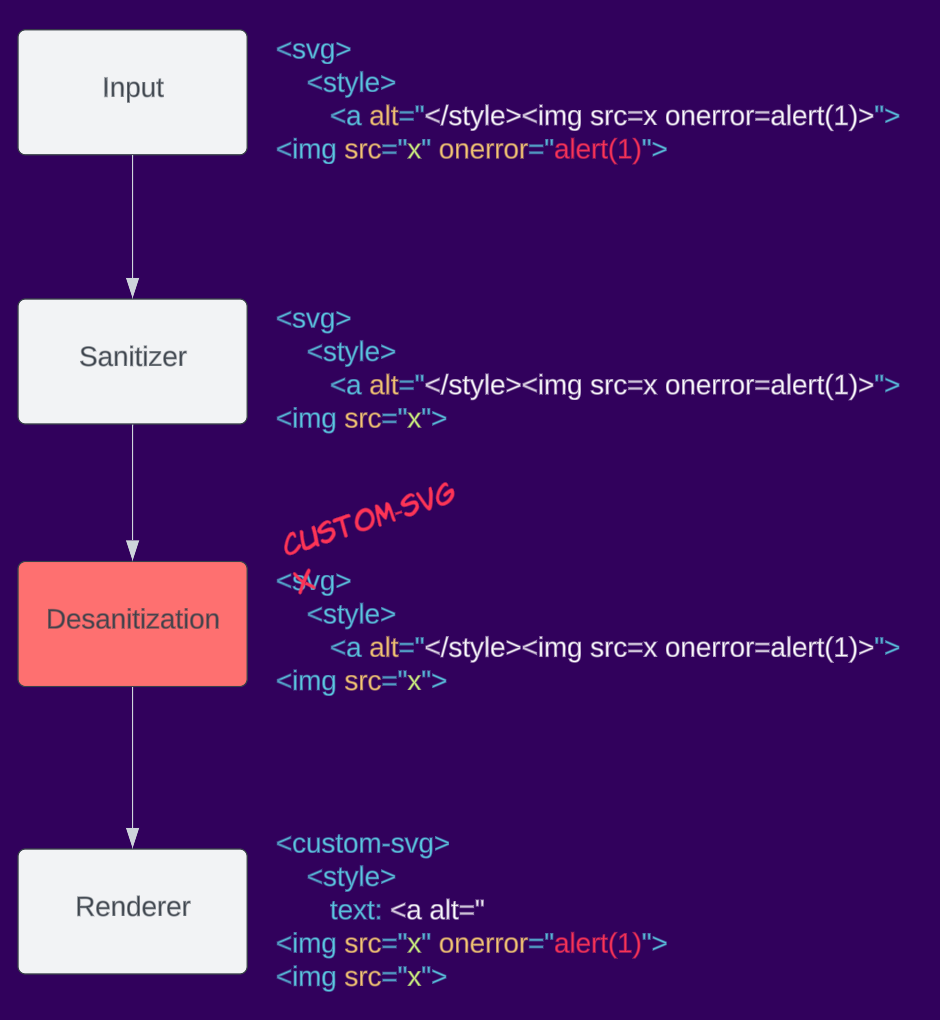
He aquí un ejemplo de desanilización: una aplicación toma la salida del desanilizador y renombra el elemento svg como custom-svg, lo que cambia el espacio de nombres del elemento y podría provocar XSS al volver a renderizarlo.
Dependiente del contexto
El análisis HTML es complejo y puede variar en función del contexto. Por ejemplo, el análisis de un documento completo es diferente del análisis de fragmentos en Firefox (véase la sección Browser Specific de la hoja de referencia). Al lidiar con el cambio de la desinfección a la representación en el navegador, los desarrolladores pueden cambiar por error el contexto en el que se representan los datos, lo que provoca diferencias en el análisis y, en última instancia, eludir el desinfectante. Dado que los sanitizadores de terceros no conocen el contexto en el que se colocará el resultado, no pueden abordar este problema. El objetivo es resolverlo cuando los navegadores implementen un sanitizador integrado (iniciativa Sanitizer API).
Por ejemplo, una aplicación sanitiza una entrada, pero al incrustarla en la página, la encapsula en SVG, cambiando el contexto a un espacio de nombres SVG.
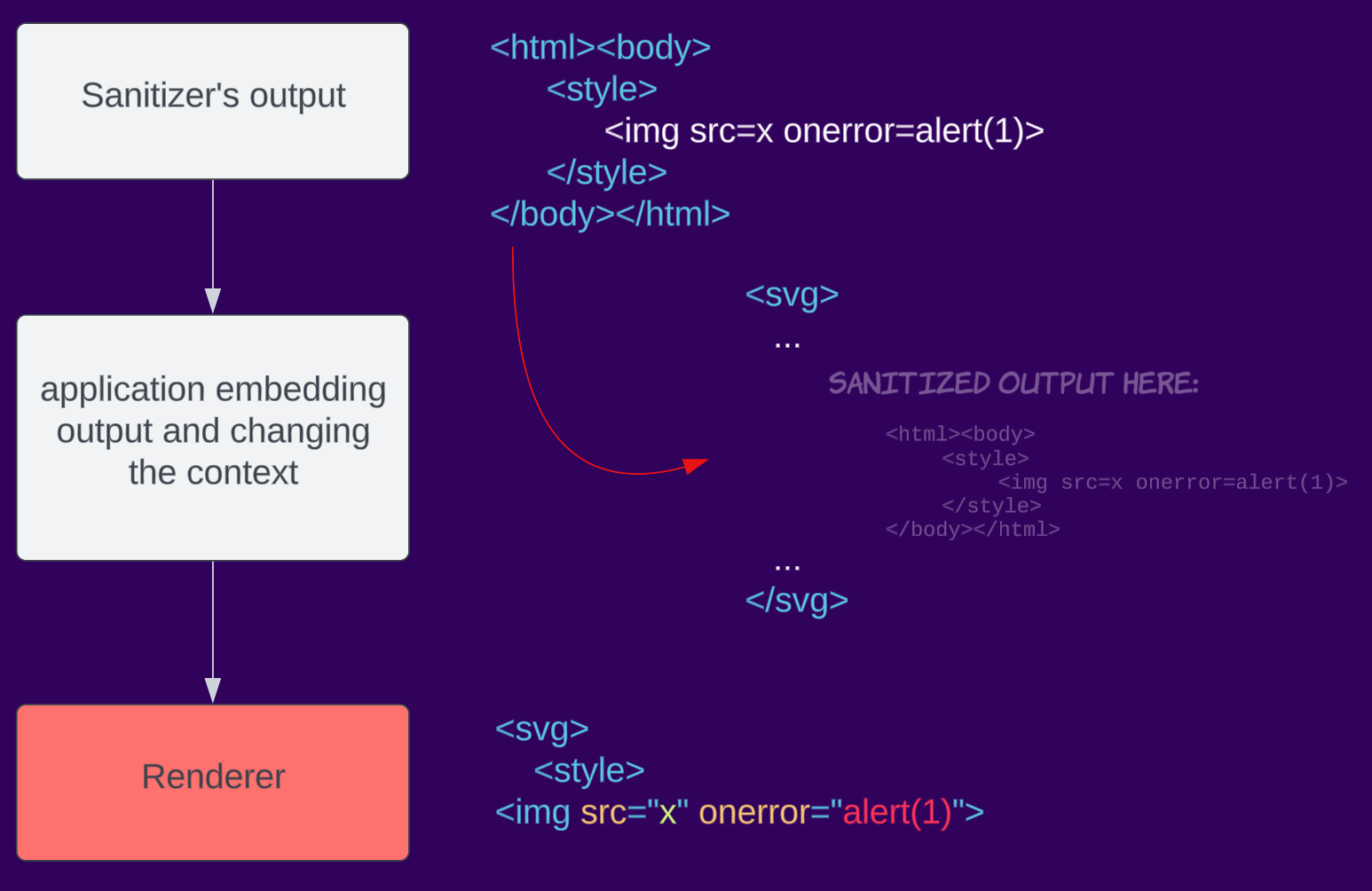
Casos prácticos de mXSS
Aunque ya hemos publicado entradas de blog sobre vulnerabilidades mXSS, como Respuesta a calc: la cadena de ataque para comprometer Mailspring, también hemos informado de varios casos de elusión de sanitizadores, como mganss/HtmlSanitizer (CVE-2023-44390), Typo3 (CVE-2023-38500), OWASP/java-html-sanitizer y otros.
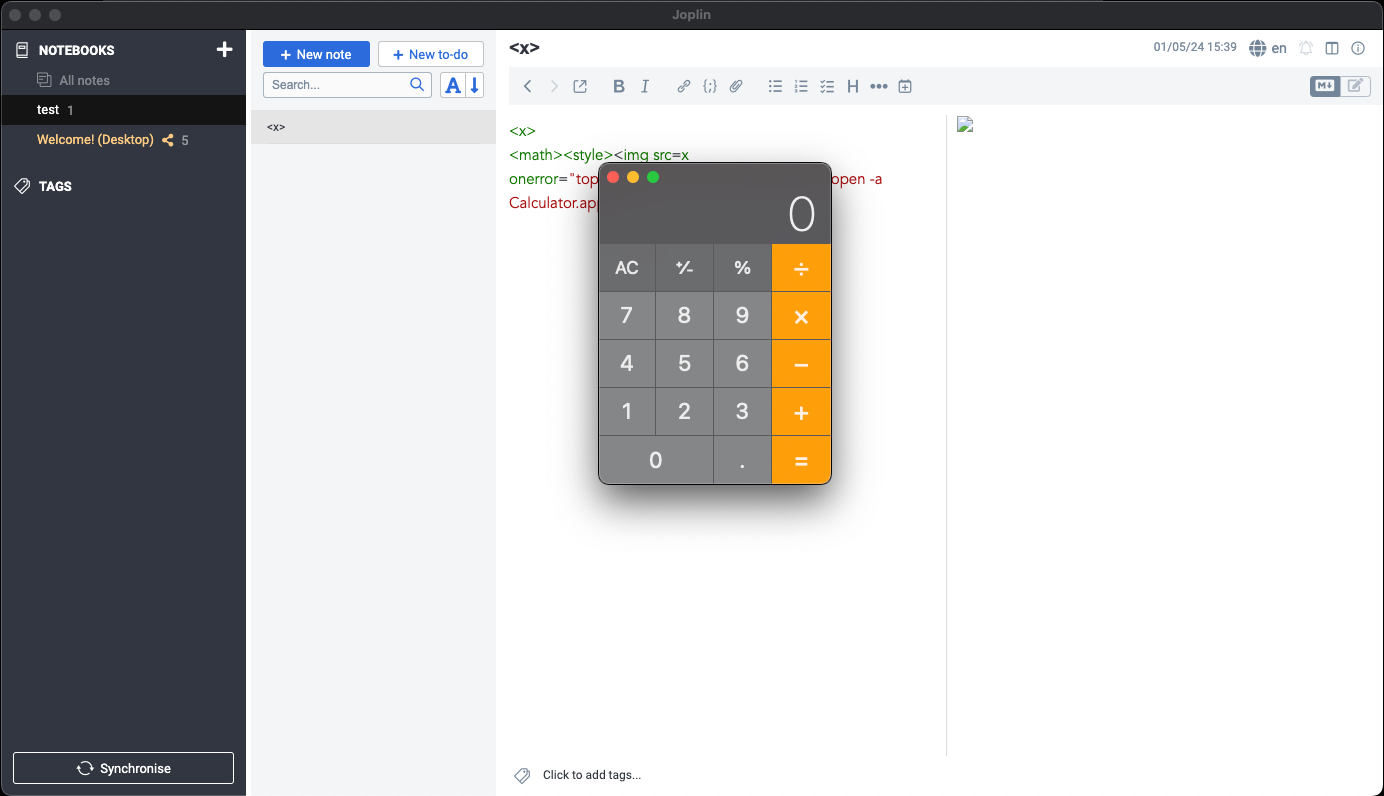
Pero veamos un caso práctico sencillo en un software llamado Joplin (CVE-2023-33726), una aplicación de escritorio para tomar notas escrita en Electron. Debido a configuraciones inseguras de Electron, el código JS de Joplin puede utilizar funcionalidades internas de Node, lo que permite a un atacante ejecutar comandos arbitrarios en la máquina.
El origen de la vulnerabilidad reside en el analizador del sanitizador, que analiza entradas HTML no fiables a través del paquete npm htmlparser2. El propio paquete afirma que no sigue la especificación y prefiere la velocidad a la precisión: «Si necesitas un cumplimiento estricto de la especificación HTML, echa un vistazo a parse5».
Muy rápidamente nos dimos cuenta de que este analizador no sigue la especificación. Con la siguiente entrada, podemos ver que el analizador ignora los diferentes espacios de nombres.

Mientras que el analizador del desinfectante no representa el elemento img, el renderizador sí lo hace. Este es un ejemplo de Parser Differential, un atacante puede simplemente añadir un controlador de eventos onerror que ejecutará código arbitrario cuando la víctima abra una nota maliciosa.
Este hallazgo específico también fue descubierto de forma independiente por @maple3142.
Mitigación
Desafortunadamente, no existe una solución de mitigación sencilla. Recomendamos a los desarrolladores que comprendan en profundidad este tipo de error para que puedan tomar una mejor decisión sobre cómo mitigar este problema según su aplicación.
Durante nuestra investigación, encontramos una serie de enfoques de mitigación y medidas de seguridad que los desarrolladores adoptaron para abordar el problema del mXSS (también disponibles en la hoja de referencia):
Desinfectar el lado del cliente
- Esta es probablemente la regla más importante a seguir. El uso de desinfectantes que se ejecutan en el lado del cliente, como DOMPurify, evita el riesgo de diferencias entre analizadores. Debido a la complejidad del análisis y a la probabilidad de servir contenido a diferentes analizadores (Firefox frente a Chrome frente a Safari, etc.), es imposible evitar las diferencias cuando el HTML se analiza en un lugar distinto al que finalmente se renderiza el contenido. Por esa razón, los sanitizadores del lado del servidor son propensos a fallar.
- Cuando se utiliza el renderizado del lado del servidor (SSR) con un marco JS del lado del cliente, puede ser fácil incorporar bibliotecas como isomorphic-dompurify. Estas permiten que los sanitizadores del lado del cliente, como DOMPurify, «simplemente funcionen» en modo SSR. Pero para lograrlo, también introducen un analizador HTML del lado del servidor, como jsdom, lo que introduce riesgos de diferencias en el analizador. La opción más segura para las aplicaciones web que utilizan SSR es desactivar SSR para el HTML controlado por el usuario y aplazar la desinfección y la representación solo al lado del cliente.
No vuelva a analizar
- Para evitar el «Round trip mXSS», la aplicación puede insertar el árbol DOM desinfectado directamente en el documento, a diferencia de serializar y volver a renderizar el contenido.
- Tenga en cuenta que este enfoque solo se puede llevar a cabo cuando los desinfectantes se implementan en el lado del cliente y puede provocar comportamientos inesperados (como renderizar el contenido de forma diferente debido a que no se adapta al contexto de la página).
Codifique o elimine siempre el contenido sin procesar
- Dado que la idea del mXSS es encontrar una forma de que una cadena maliciosa se represente como texto sin procesar en el desinfectante, pero se analice como HTML más tarde, no permitir/codificar ningún texto sin procesar en la etapa de desinfección haría imposible volver a representarlo como HTML.
- Tenga en cuenta que esto podría romper algunas cosas, como el código CSS.
No admitir elementos de contenido externo
- No admitir elementos de contenido externo (eliminar elementos svg/math y su contenido, no renombrarlos) en los sanitizadores reduce significativamente la complejidad.
- Tenga en cuenta que esto no mitiga el mXSS, pero ofrece una medida de precaución.
Futuro
Un tema tan complejo sin una solución sencilla, ¿hay un futuro prometedor?
La respuesta es sí, afortunadamente hay una serie de propuestas y medidas adoptadas para poner fin a este tipo de errores o, al menos, abordarlos oficialmente.
El mayor problema hoy en día es que la responsabilidad de sanear las entradas HTML no fiables recae en los desarrolladores externos, ya sean desarrolladores de aplicaciones o desarrolladores de sanitizadores. Esto es poco práctico debido a la complejidad de la tarea y al hecho de que tendrían que abordar diferentes analizadores de renderizado (diferentes usuarios utilizan otros navegadores) y mantenerse al día con las especificaciones HTML en constante evolución. Una forma más correcta de abordar esto es hacer que sea responsabilidad del renderizador asegurarse de que no haya contenido malicioso en el marcado. Por ejemplo, tener un limpiador integrado en el navegador podría eliminar la mayoría, si no todos, los bypass que vemos hasta el día de hoy.
La iniciativa Sanitizer API es precisamente eso. Actualmente está siendo desarrollada por el Web Platform Incubator Community Group (WICG) y tiene como objetivo proporcionar a los desarrolladores un limpiador integrado, robusto y sensible al contexto escrito por los propios navegadores (sin diferencias entre analizadores ni reanálisis). Una mayor adopción de la API Sanitizer por parte de los navegadores probablemente llevaría a un mayor uso por parte de los desarrolladores para una manipulación más segura del HTML.
Otra medida adoptada para abordar este problema es la actualización de las especificaciones. Por ejemplo, Chrome ahora codifica los caracteres < y > en los atributos
<svg><style><a alt="</style>"> → <svg><style><a alt="</style>">
Evolucionar los fundamentos de las definiciones HTML hacia un futuro más seguro.
Hoja de referencia de mXSS 🧬🔬
Hemos creado una hoja de referencia de mXSS destinada a ser una ventanilla única para cualquier persona interesada en aprender, investigar e innovar en el mundo de mXSS. Ayudamos a los usuarios a ver el comportamiento inesperado del HTML en una lista simplificada, en lugar de leer 1500 páginas de documentación. Animamos a los usuarios a contribuir y ayudar a impulsar este esfuerzo juntos.
Resumen
mXSS (mutación de scripts entre sitios) es una vulnerabilidad de seguridad que surge de la forma en que se maneja el HTML. Incluso si una aplicación web cuenta con filtros sólidos para prevenir los ataques XSS tradicionales, mXSS puede colarse. Esto se debe a que mXSS aprovecha las peculiaridades del comportamiento del HTML, cegando al sanitizador ante los elementos maliciosos.
Este blog profundiza en mXSS, proporcionando ejemplos, dividiendo este gran nombre «mXSS» en subsecciones y cubriendo las estrategias de mitigación de los desarrolladores. Al dotarle de estos conocimientos, esperamos que los desarrolladores e investigadores puedan abordar con confianza este problema en el futuro.