

Cross-Site-Scripting (XSS) ist eine bekannte Art von Sicherheitslücke, die auftritt, wenn ein Angreifer JavaScript-Code in eine anfällige Seite einschleusen kann. Wenn ein ahnungsloses Opfer die Seite besucht, wird der eingeschleuste Code in der Sitzung des Opfers ausgeführt. Die Auswirkungen dieses Angriffs können je nach Anwendung variieren und reichen von keinen geschäftlichen Auswirkungen bis hin zu Kontoübernahmen (ATO), Datenlecks oder sogar Remote-Code-Ausführung (RCE).
Es gibt verschiedene Arten von XSS, wie z. B. reflektiertes, gespeichertes und universelles XSS. In den letzten Jahren hat sich jedoch die Mutationsklasse von XSS zu einer gefürchteten Bedrohung entwickelt, da sie Sanitizer wie DOMPurify, Mozilla Bleach, Google Caja und andere umgehen kann und zahlreiche Anwendungen, darunter auch die Google-Suche, betrifft. Bis heute gibt es viele Anwendungen, die für diese Art von Angriffen anfällig sind.
Aber was ist mXSS?
(Wir haben dieses Thema auch in unserem Vortrag auf der Insomnihack 2024 behandelt: Beating The Sanitizer: Why You Should Add mXSS To Your Toolbox.)
Hintergrund
Wenn Sie Webentwickler sind, haben Sie wahrscheinlich bereits eine Art Sanitization integriert oder sogar implementiert, um Ihre Anwendung vor XSS-Angriffen zu schützen. Aber nur wenige wissen, wie schwierig es ist, einen geeigneten HTML-Sanitizer zu erstellen. Das Ziel eines HTML-Sanitisers ist es, sicherzustellen, dass benutzergenerierte Inhalte, wie Texteingaben oder Daten aus externen Quellen, keine Sicherheitsrisiken darstellen oder die beabsichtigte Funktionalität einer Website oder Anwendung stören.
Eine der größten Herausforderungen bei der Implementierung eines HTML-Sanitisers liegt in der Komplexität von HTML selbst. HTML ist eine vielseitige Sprache mit einer Vielzahl von Elementen, Attributen und möglichen Kombinationen, die die Struktur und das Verhalten einer Webseite beeinflussen können. Das genaue Parsen und Analysieren von HTML-Code unter Beibehaltung seiner beabsichtigten Funktionalität kann eine gewaltige Aufgabe sein.
HTML
Bevor wir uns mit dem Thema mXSS befassen, wollen wir uns zunächst HTML ansehen, die Markup-Sprache, die die Grundlage von Webseiten bildet. Das Verständnis der Struktur und Funktionsweise von HTML ist von entscheidender Bedeutung, da mXSS-Angriffe (Mutation Cross-Site Scripting) die Eigenheiten und Feinheiten von HTML ausnutzen.
HTML gilt als tolerante Sprache, da es bei Fehlern oder unerwartetem Code nachsichtig ist. Im Gegensatz zu einigen strengeren Programmiersprachen legt HTML den Schwerpunkt auf die Anzeige von Inhalten, auch wenn der Code nicht perfekt geschrieben ist. Diese Toleranz zeigt sich wie folgt:
Wenn ein fehlerhaftes Markup gerendert wird, versuchen Browser, den HTML-Code so gut wie möglich zu interpretieren und zu korrigieren, anstatt abzustürzen oder eine Fehlermeldung anzuzeigen, selbst wenn er kleinere Syntaxfehler oder fehlende Elemente enthält. Wenn Sie beispielsweise das folgende Markup im Browser öffnen <p>test, wird es wie erwartet ausgeführt, obwohl das schließende p-Tag fehlt. Wenn wir uns den HTML-Code der endgültigen Seite ansehen, können wir erkennen, dass der Parser unser fehlerhaftes Markup korrigiert und das p-Element selbst geschlossen hat: <p>test</p>.
Warum es tolerant ist:
- Barrierefreiheit: Das Web sollte für alle zugänglich sein, und kleinere Fehler im HTML sollten die Benutzer nicht daran hindern, den Inhalt zu sehen. Toleranz ermöglicht es einem breiteren Spektrum von Benutzern und Entwicklern, mit dem Web zu interagieren.
- Flexibilität: HTML wird oft von Menschen mit unterschiedlichen Programmierkenntnissen verwendet. Toleranz lässt einige Ungenauigkeiten oder Fehler zu, ohne die Funktionalität der Seite vollständig zu beeinträchtigen.
- Abwärtskompatibilität: Das Web entwickelt sich ständig weiter, aber viele bestehende Websites wurden mit älteren HTML-Standards erstellt. Toleranz stellt sicher, dass diese älteren Websites auch in modernen Browsern angezeigt werden können, selbst wenn sie nicht den neuesten Spezifikationen entsprechen.
Aber woher weiß unser HTML-Parser, wie er einen fehlerhaften Markup „reparieren” soll? Soll <a><b> zu<a></a><b></b> oder zu <a><b></b></a> werden?
Um diese Frage zu beantworten, gibt es eine gut dokumentierte HTML-Spezifikation, aber leider gibt es immer noch einige Unklarheiten, die selbst zwischen den gängigen Browsern zu unterschiedlichen HTML-Parsing-Verhaltensweisen führen.
Mutation
OK, HTML kann also fehlerhafte Markups tolerieren – aber warum ist das relevant?
Das M in mXSS steht für „Mutation”, und eine Mutation in HTML ist jede Art von Änderung, die aus irgendeinem Grund am Markup vorgenommen wird.
- Wenn ein Parser einen fehlerhaften Markup korrigiert (
<p>test→<p>test</p>), ist das eine Mutation. - Das Normalisieren von Attribut-Anführungszeichen (
<a alt=test>→<a alt=”test”>) ist eine Mutation. - Das Neuanordnen von Elementen (
<table><a>→<a></a><table></table>) ist eine Mutation - Und so weiter...
mXSS nutzt dieses Verhalten, um die Bereinigung zu umgehen. Wir werden Beispiele in den technischen Details vorstellen.
Hintergrund zum HTML-Parsing
Es ist nicht realistisch, das HTML-Parsing, einen 1500 Seiten langen Standard, in einem Abschnitt zusammenzufassen. Aufgrund seiner Bedeutung für das Verständnis von mXSS und der Funktionsweise von Payloads müssen wir jedoch zumindest einige wichtige Themen behandeln. Um die Sache zu vereinfachen, haben wir ein mXSS-Cheatsheet (weiter unten in diesem Blog) entwickelt, das den umfangreichen Standard zu einer überschaubaren Ressource für Forscher und Entwickler zusammenfasst.
Verschiedene Arten der Inhaltsanalyse
HTML ist keine einheitliche Analyseumgebung. Elemente behandeln ihre Inhalte unterschiedlich, wobei sieben verschiedene Analysemodi zum Einsatz kommen. Wir werden diese Modi untersuchen, um zu verstehen, wie sie mXSS-Schwachstellen beeinflussen:
- void-Elemente
area,base,br,col,embed,hr,img,input,link,meta,source,track,wbr
- das
template-Elementtemplate
- Rohtext-Elemente
script,style,noscript,xmp,iframe,noembed,noframes
- Escapable-Rohtext-Elemente
textarea,title
- Fremde Inhaltselemente
svg,math
- Klartext-Status
plaintext
- Normale Elemente
- Alle anderen zulässigen HTML-Elemente sind normale Elemente.
Anhand des folgenden Beispiels lässt sich der Unterschied zwischen den Parsing-Typen recht einfach veranschaulichen:
- Unsere erste Eingabe ist ein
div-Element, das ein „normales Element” ist: <div><a alt="</div><img src=x onerror=alert(1)>">- Die zweite Eingabe ist hingegen ein ähnliches Markup, das stattdessen das Element
styleverwendet (das ein „Rohtextelement” ist): <style><a alt="</style><img src=x onerror=alert(1)>">
Wenn wir uns das geparste Markup ansehen, können wir die Unterschiede beim Parsen deutlich erkennen:
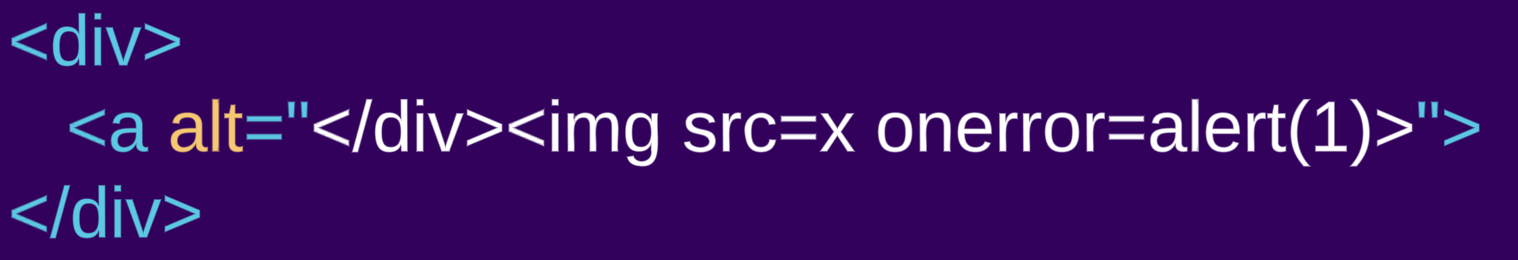

Der Inhalt des div-Elements wird als HTML gerendert, ein a-Element wird erstellt. Was wie ein schließendes div- und ein img-Tag aussieht, ist tatsächlich ein Attributwert des a-Elements und wird daher als alt-Text für das a-Element und nicht als HTML-Markup gerendert. Im style-Beispiel wird der Inhalt des style-Elements als Rohtext gerendert, sodass kein a-Element erstellt wird und das vermeintliche Attribut nun normales HTML-Markup ist.
Fremde Inhaltselemente
HTML5 hat neue Möglichkeiten eingeführt, um spezielle Inhalte in Webseiten zu integrieren. Zwei wichtige Beispiele sind die Elemente <svg> und <math>. Diese Elemente nutzen unterschiedliche Namespaces, was bedeutet, dass sie anderen Parsing-Regeln folgen als Standard-HTML. Das Verständnis dieser unterschiedlichen Parsing-Regeln ist entscheidend für die Minderung potenzieller Sicherheitsrisiken im Zusammenhang mit mXSS-Angriffen.
Schauen wir uns dasselbe Beispiel wie zuvor an, diesmal jedoch in einem svg-Element gekapselt:
<svg><style><a alt="</style><img src=x onerror=alert(1)>">
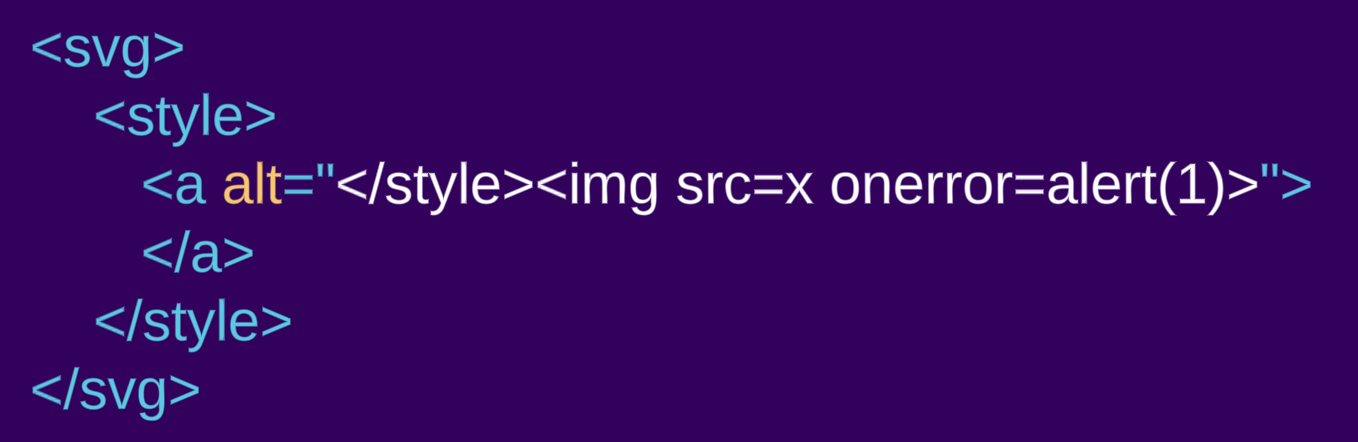
In diesem Fall sehen wir, dass ein a-Element erstellt wird. Das style-Element folgt nicht den Parsing-Regeln für „Rohtext“, da es sich in einem anderen Namespace befindet. Innerhalb eines SVG- oder MathML-Namespace ändern sich die Parsing-Regeln und folgen nicht mehr der HTML-Sprache.
Mithilfe von Techniken zur Verwirrung des Namespace (wie DOMPurify 2.0.0 Bypass) können Angreifer den Sanitizer manipulieren, um Inhalte anders zu parsen, als sie letztendlich vom Browser gerendert werden, und so die Erkennung bösartiger Elemente umgehen.
Von Mutationen zu Schwachstellen
Häufig wird der Begriff mXSS in einem breiten Sinne verwendet, wenn es um verschiedene Sanitizer-Bypässe geht. Zum besseren Verständnis werden wir den allgemeinen Begriff „mXSS“ in vier verschiedene Unterkategorien unterteilen
Parser-Unterschiede
Obwohl Parser-Unterschiede als gewöhnliche Sanitizer-Umgehung bezeichnet werden können, werden sie manchmal auch als mXSS bezeichnet. In beiden Fällen kann ein Angreifer eine Parser-Diskrepanz zwischen dem Algorithmus des Sanitizers und dem des Renderers (z. B. Browser) ausnutzen. Aufgrund der Komplexität der HTML-Parsing-Vorgänge bedeutet das Vorhandensein von Parsing-Differenzen nicht unbedingt, dass ein Parser falsch und der andere richtig ist.
Nehmen wir zum Beispiel das Element noscript. Die Parsing-Regel dafür lautet: „Wenn das Scripting-Flag aktiviert ist, schalten Sie den Tokenizer in den RAWTEXT-Zustand. Andernfalls belassen Sie den Tokenizer im Datenzustand.” (Link) Das bedeutet, dass der Body des noscript-Elements je nachdem, ob JavaScript deaktiviert oder aktiviert ist, unterschiedlich gerendert wird. Es ist logisch, dass JavaScript in der Sanitizer-Phase nicht aktiviert ist, aber im Renderer. Dieses Verhalten ist per Definition nicht falsch, kann aber zu Umgehungen führen, wie zum Beispiel: <noscript><style></noscript><img src=x onerror=”alert(1)”>
JS deaktiviert:

JS aktiviert:

Viele andere Parser-Unterschiede, wie z. B. unterschiedliche HTML-Versionen, Inhaltsart-Inkompatibilitäten und vieles mehr, könnten auftreten.
Parsing-Roundtrip
Parsing-Roundtrip ist ein bekanntes und dokumentiertes Phänomen, das besagt: „Es ist möglich, dass die Ausgabe dieses Algorithmus, wenn sie mit einem HTML-Parser geparst wird, nicht die ursprüngliche Baumstruktur zurückgibt. Baumstrukturen, die keinen Roundtrip-Schritt mit Serialisierung und Reparsing durchlaufen, können auch vom HTML-Parser selbst erzeugt werden, obwohl solche Fälle in der Regel nicht konform sind.“
Das bedeutet, dass sich die resultierende DOM-Baumstruktur je nach der Anzahl der Parsing-Durchläufe eines HTML-Markups ändern kann.
Sehen wir uns das offizielle Beispiel aus der Spezifikation an:
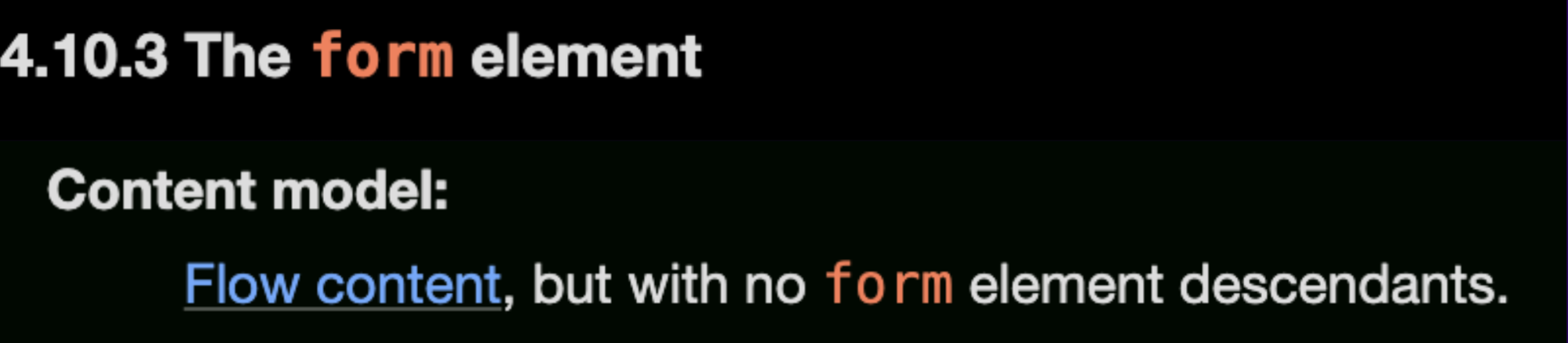
Zunächst müssen wir jedoch verstehen, dass ein form-Element kein weiteres form-Element enthalten kann: „Inhaltsmodell: Fließender Inhalt, jedoch ohne untergeordnete Formularelemente.“ (wie in den Spezifikationen beschrieben)
Wenn wir jedoch weiter in der Dokumentation lesen, finden wir ein Beispiel dafür, wie form-Elemente verschachtelt werden können, und zwar durch den folgenden Markup:
<form id="outer"><div></form><form id="inner"><input>
html
├── head
└── body
└── form id="outer"
└── div
└── form id="inner"
└── inputDas </form> wird aufgrund des nicht geschlossenen div ignoriert, und das input-Element wird mit dem inneren form-Element verknüpft. Wenn diese Baumstruktur nun serialisiert und erneut geparst wird, wird das Start-Tag <form id="inner"> ignoriert, sodass das input-Element stattdessen mit dem äußeren form-Element verknüpft wird.
<html><head></head><body><form id="outer"><div><form id="inner"><input></form></div></form></body></html>
html
├── head
└── body
└── form id="outer"
└── div
└── inputAngreifer können dieses Verhalten ausnutzen, um eine Verwechslung der Namespaces zwischen dem Sanitizer und dem Renderer zu verursachen, was zu Umgehungen wie der folgenden führt:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
Quelle: @SecurityMB, ausführlich behandelt hier.
Desanitization
Desanitization ist ein schwerwiegender Fehler, den Anwendungen begehen, wenn sie die Ausgabe des Sanitisers vor dem Senden an den Client verändern und damit im Wesentlichen die Arbeit des Sanitisers zunichte machen. Jede kleine Änderung am Markup kann erhebliche Auswirkungen auf den endgültigen DOM-Baum haben und zu einer Umgehung der Sanitization führen. Wir haben dieses Problem bereits in einem Vortrag bei Insomni'Hack und mehreren Blog-Beiträgen behandelt, in denen wir Schwachstellen in verschiedenen Anwendungen identifiziert haben, darunter:
- Fallstricke der Desanitization: Durchsickern von Kundendaten aus osTicket
- Code-Schwachstellen gefährden Proton-E-Mails
- Remote-Code-Ausführung in Tutanota Desktop aufgrund eines Code-Fehlers
- Code-Schwachstellen gefährden Skiff-E-Mails
Hier ist ein Beispiel für Desanitization: Eine Anwendung nimmt die Ausgabe des Sanitizers und benennt das Element svg in custom-svg um. Dadurch wird der Namespace des Elements geändert, was beim erneuten Rendern zu XSS führen kann.
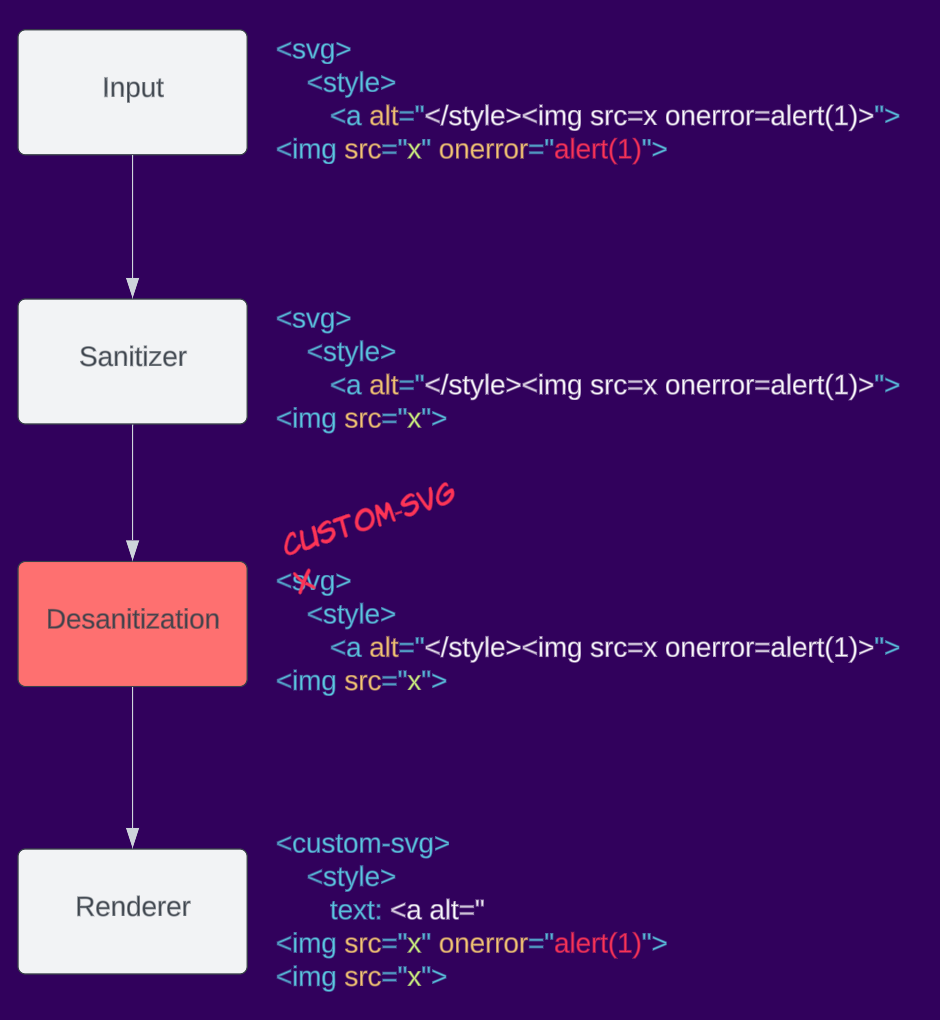
Kontextabhängig
HTML-Parsing ist komplex und kann je nach Kontext unterschiedlich sein. Beispielsweise unterscheidet sich das Parsen eines gesamten Dokuments vom Parsen von Fragmenten in Firefox (siehe Abschnitt „Browser Specific” auf dem Cheatsheet). Beim Umgang mit dem Wechsel vom Sanitizing zum Rendering im Browser können Entwickler versehentlich den Kontext ändern, in dem die Daten gerendert werden, was zu Parsing-Unterschieden führt und letztendlich das Sanitizing umgeht. Da Sanitizer von Drittanbietern den Kontext, in dem das Ergebnis platziert wird, nicht kennen, können sie dieses Problem nicht beheben. Dies soll gelöst werden, wenn Browser einen integrierten Sanitizer implementieren (Sanitizer API).
Beispielsweise bereinigt eine Anwendung eine Eingabe, aber beim Einbetten in die Seite wird sie in SVG gekapselt, wodurch sich der Kontext in einen SVG-Namespace ändert.
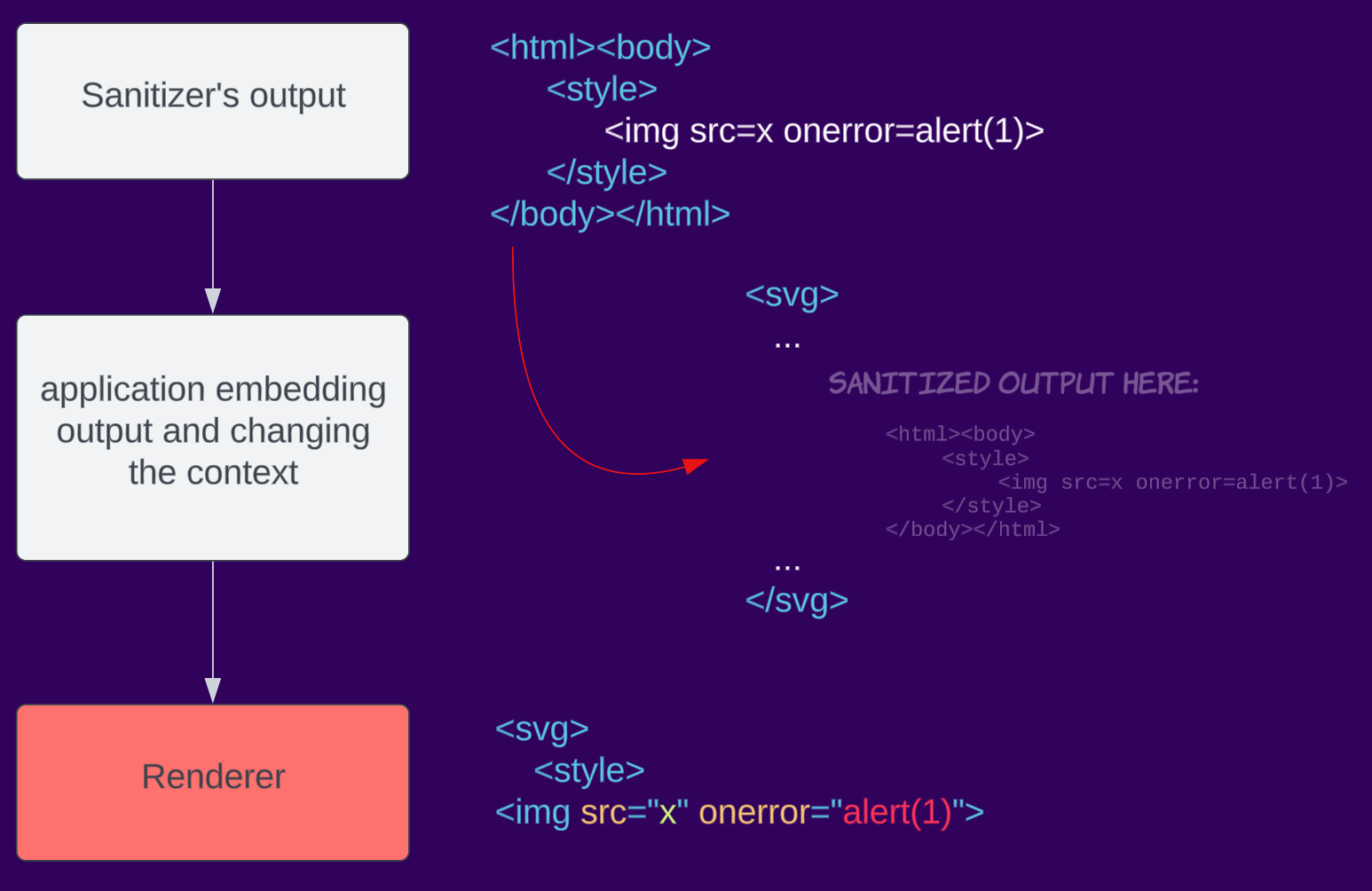
mXSS-Fallstudien
Wir haben in der Vergangenheit bereits Blogbeiträge zu mXSS-Schwachstellen veröffentlicht, darunter Reply to calc: The Attack Chain to Compromise Mailspring, und haben auch über verschiedene Sanitizer-Bypässe berichtet, darunter mganss/HtmlSanitizer (CVE-2023-44390), Typo3 (CVE-2023-38500), OWASP/java-html-sanitizer und mehr.
Aber schauen wir uns eine einfache Fallstudie zu einer Software namens Joplin (CVE-2023-33726) an, einer in Electron geschriebenen Desktop-App zum Erstellen von Notizen. Aufgrund unsicherer Electron-Konfigurationen kann der JS-Code in Joplin interne Funktionen von Node nutzen, wodurch ein Angreifer beliebige Befehle auf dem Rechner ausführen kann.
Der Ursprung der Schwachstelle liegt im Parser des Sanitisers, der nicht vertrauenswürdige HTML-Eingaben über das npm-Paket htmlparser2 parst. Das Paket selbst gibt an, dass es sich nicht an die Spezifikation hält und Geschwindigkeit vor Genauigkeit bevorzugt: „Wenn Sie eine strikte Einhaltung der HTML-Spezifikation benötigen, schauen Sie sich parse5 an.“
Wir haben sehr schnell festgestellt, dass dieser Parser sich nicht an die Spezifikation hält. Anhand der folgenden Eingabe können wir sehen, dass der Parser unterschiedliche Namespaces nicht berücksichtigt.

Während der Parser des Sanitisers das img-Element nicht rendert, tut dies der Renderer. Dies ist ein Beispiel für Parser Differential. Ein Angreifer kann einfach einen onerror-Ereignishandler hinzufügen, der beliebigen Code ausführt, wenn ein Opfer eine bösartige Notiz öffnet.
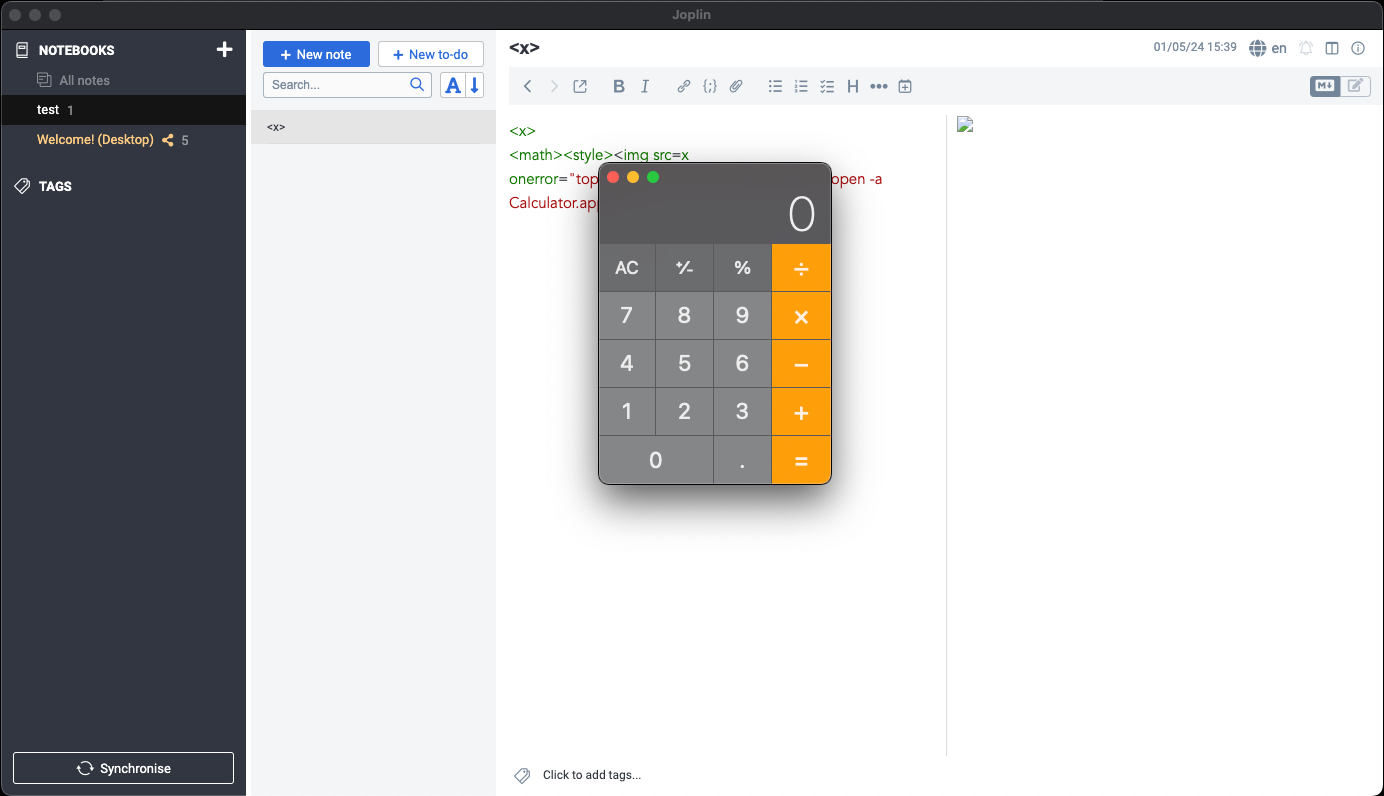
Diese spezifische Erkenntnis wurde auch unabhängig davon von @maple3142 gewonnen.
Abhilfe
Leider gibt es keine einfache Lösung für dieses Problem. Wir empfehlen Entwicklern, sich eingehend mit dieser Fehlerklasse vertraut zu machen, damit sie eine bessere Entscheidung darüber treffen können, wie sie dieses Problem entsprechend ihrer Anwendung beheben können.
Im Rahmen unserer Untersuchungen sind wir auf eine Reihe von Abhilfemaßnahmen und Sicherheitsvorkehrungen gestoßen, die Entwickler ergriffen haben, um das Problem von mXSS zu beheben (auch im Cheatsheet verfügbar):
Clientseitige Bereinigung
- Dies ist wahrscheinlich die wichtigste Regel, die es zu befolgen gilt. Durch die Verwendung von clientseitigen Bereinigungsprogrammen wie DOMPurify lassen sich Risiken aufgrund von Parser-Unterschieden vermeiden. Aufgrund der Komplexität des Parsings und der Tatsache, dass Inhalte höchstwahrscheinlich an verschiedene Parser (Firefox vs. Chrome vs. Safari usw.) geliefert werden, lassen sich Unterschiede nicht vermeiden, wenn HTML nicht an derselben Stelle geparst wird, an der der Inhalt schließlich gerendert wird. Aus diesem Grund sind serverseitige Sanitizer anfällig für Fehler.
- Bei der Verwendung von Server-Side Rendering (SSR) mit einem clientseitigen JS-Framework kann es einfach sein, Bibliotheken wie isomorphic-dompurify einzufügen. Sie lassen clientseitige Sanitizer wie DOMPurify im SSR-Modus „einfach funktionieren”. Um dies zu erreichen, führen sie jedoch auch einen serverseitigen HTML-Parser wie jsdom ein, der Risiken durch Parser-Unterschiede mit sich bringt. Die sicherste Option für Webanwendungen, die SSR verwenden, besteht darin, SSR für benutzergesteuertes HTML zu deaktivieren und die Bereinigung und das Rendern ausschließlich auf die Client-Seite zu verlagern.
Nicht erneut parsen
- Um „Round Trip mXSS“ zu vermeiden, kann die Anwendung den bereinigten DOM-Baum direkt in das Dokument einfügen, anstatt den Inhalt zu serialisieren und neu zu rendern.
- Beachten Sie, dass dieser Ansatz nur möglich ist, wenn die Sanitizer auf der Client-Seite implementiert sind, und dass er zu unerwarteten Verhaltensweisen führen kann (z. B. unterschiedliches Rendern von Inhalten, da sie nicht an den Kontext der Seite angepasst sind).
Rohinhalte immer kodieren oder löschen
- Da die Idee von mXSS darin besteht, einen Weg zu finden, wie eine bösartige Zeichenfolge im Sanitizer als Rohtext gerendert, später jedoch als HTML geparst werden kann, würde das Verbot/die Kodierung von Rohtext in der Sanitizer-Phase ein erneutes Rendern als HTML unmöglich machen.
- Beachten Sie, dass dies einige Dinge wie CSS-Code beschädigen könnte.
Keine Unterstützung für fremde Inhaltselemente
- Die Nichtunterstützung fremder Inhaltselemente (Löschen von SVG-/Math-Elementen und deren Inhalt, keine Umbenennung) in Ihren Sanitisern reduziert die Komplexität erheblich.
- Beachten Sie, dass dies mXSS nicht mindert, sondern eine Vorsichtsmaßnahme darstellt.
Zukunft
Gibt es für ein so komplexes Thema ohne einfache Lösung eine vielversprechende Zukunft?
Die Antwort lautet ja. Glücklicherweise gibt es eine Reihe von Vorschlägen und Maßnahmen, um diese Fehlerklasse zu beseitigen oder zumindest offiziell anzugehen.
Das größte Problem besteht derzeit darin, dass die Verantwortung für die Bereinigung nicht vertrauenswürdiger HTML-Eingaben bei Drittentwicklern liegt, seien es Anwendungsentwickler oder Sanitizer-Entwickler. Dies ist aufgrund der Komplexität der Aufgabe und der Tatsache, dass sie verschiedene Renderer-Parser (verschiedene Benutzer verwenden unterschiedliche Browser) berücksichtigen und mit den sich weiterentwickelnden HTML-Spezifikationen Schritt halten müssen, nicht praktikabel. Ein korrekterer Ansatz wäre es, die Verantwortung dafür, dass das Markup keine schädlichen Inhalte enthält, dem Renderer zu übertragen. Ein in den Browser integrierter Sanitizer könnte beispielsweise die meisten, wenn nicht sogar alle Umgehungsmöglichkeiten beseitigen, die wir bis heute kennen.
Die Initiative Sanitizer API verfolgt genau dieses Ziel. Sie wird derzeit von der Web Platform Incubator Community Group (WICG) entwickelt und soll Entwicklern einen integrierten, robusten und kontextsensitiven Sanitizer zur Verfügung stellen, der von den Browsern selbst geschrieben wird (keine Parser-Unterschiede oder erneutes Parsen mehr). Eine breitere Akzeptanz der Sanitizer API in Browsern würde wahrscheinlich dazu führen, dass Entwickler sie verstärkt für eine sicherere HTML-Bearbeitung nutzen.
Eine weitere Maßnahme zur Lösung dieses Problems sind Spezifikationsaktualisierungen. Beispielsweise codiert Chrome nun die Zeichen < und > in Attributen
<svg><style><a alt="</style>"> → <svg><style><a alt="</style>">
Weiterentwicklung der Grundlagen der HTML-Definitionen für eine sicherere Zukunft.
mXSS-Spickzettel 🧬🔬
Wir haben einen mXSS-Spickzettel erstellt, der als zentrale Anlaufstelle für alle dienen soll, die sich für das Lernen, Forschen und Innovieren in der Welt von mXSS interessieren. Er hilft Benutzern, unerwartetes HTML-Verhalten in einer vereinfachten Liste zu erkennen, anstatt 1500 Seiten Dokumentation lesen zu müssen. Wir haben die Benutzer dazu ermutigt, Beiträge zu leisten und diese Bemühungen gemeinsam voranzutreiben.
Zusammenfassung
mXSS (Mutation Cross-Site Scripting) ist eine Sicherheitslücke, die durch die Art und Weise entsteht, wie HTML verarbeitet wird. Selbst wenn eine Webanwendung über starke Filter verfügt, um herkömmliche XSS-Angriffe zu verhindern, kann mXSS dennoch durchschlüpfen. Das liegt daran, dass mXSS Schwachstellen im HTML-Verhalten ausnutzt und den Sanitizer für bösartige Elemente blind macht.
Dieser Blog befasst sich eingehend mit mXSS, liefert Beispiele, unterteilt den großen Begriff „mXSS” in Unterabschnitte und behandelt Strategien zur Risikominderung für Entwickler. Wir hoffen, dass Entwickler und Forscher mit diesem Wissen in Zukunft selbstbewusst mit diesem Problem umgehen können.