


Ollama is one of the most popular open-source projects on GitHub, with more than 155k stars. It is used by many AI enthusiasts and developers to run LLMs locally on their infrastructure without needing to send data to and pay external vendors such as OpenAI. Ollama supports a big variety of open-source models, such as gpt-oss, DeepSeek-R1, Meta's Llama4, or Google's Gemma3.
As part of our commitment to secure the open-source ecosystem, we audited the code base of Ollama for vulnerabilities. We found a critical Out-Of-Bounds Write vulnerability that occurs during the parsing of malicious model files and can lead to the execution of arbitrary code.
In this blog post, we will explain the technical details of this vulnerability, walk you through a proof-of-concept to determine exploitability, and show how the bug was fixed by the Ollama maintainers. The content was also presented as a talk at Hack.lu 2025:
Impact
An attacker with access to Ollama's API can load and run a malicious model, leading to Remote Code Execution. The vulnerability exists in Ollama versions before 0.7.0. We confirmed exploitability in builds without the Position Independent Executable (PIE) configuration, but it is likely also exploitable in PIE-enabled builds, such as the official releases. We strongly recommend updating Ollama to the latest version.
Technical Details
Ollama is mainly written in Go but uses C and C++ under the hood, for example to interface with the llama.cpp library. Especially compute-heavy tasks like inference are performed by C/C++ code. On a higher level, Ollama implements a client-server architecture, where the server can run locally or in the cloud, and the client is only used to interact with the server, e.g., to submit a prompt. The server then spawns a runner process per model to perform the inference and sends the result back to the client:

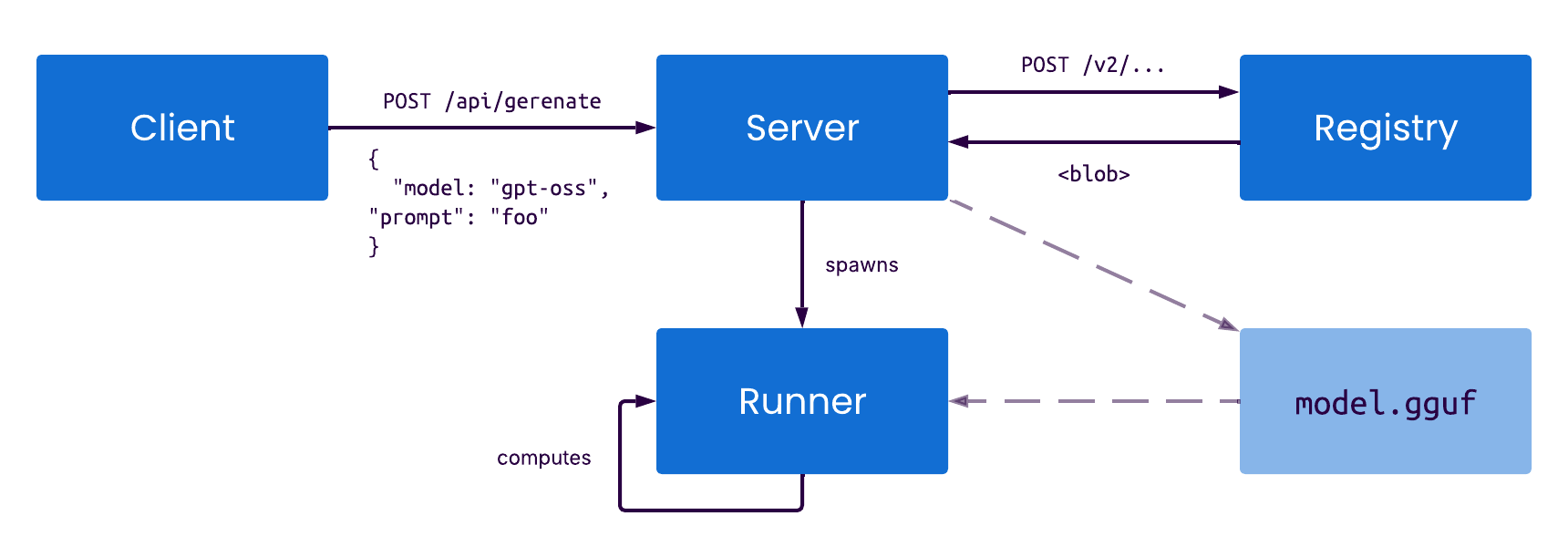
One of Ollama's big strengths is that it can run a wide range of model types. Users can publish models to the internet, and others can pull them. This is very similar to container images, which can be pushed and pulled from registries. There is an official model registry at registry.ollama.ai, but users can also host their own.
To run a model, Ollama first needs to instantiate a runner process, which has to parse and load the model from disk. Each model is loaded from a GGUF file, which is a binary file format storing model metadata and weights. A model's metadata is stored in a key-value pair format, such as its name and description, but also specifics about its internal structure, such as the number of layers. The model's weights are stored in so-called tensors, which are big binary blobs that represent multi-dimensional arrays. Some of a model's metadata is used to build the in-memory representation of the model, and this differs a lot between model types.
A wild strcpy
When approaching a target, we first scan it with SonarQube and triage the detected code issues. In the case of Ollama, SonarQube raised a usage of the dangerous strcpy() function:

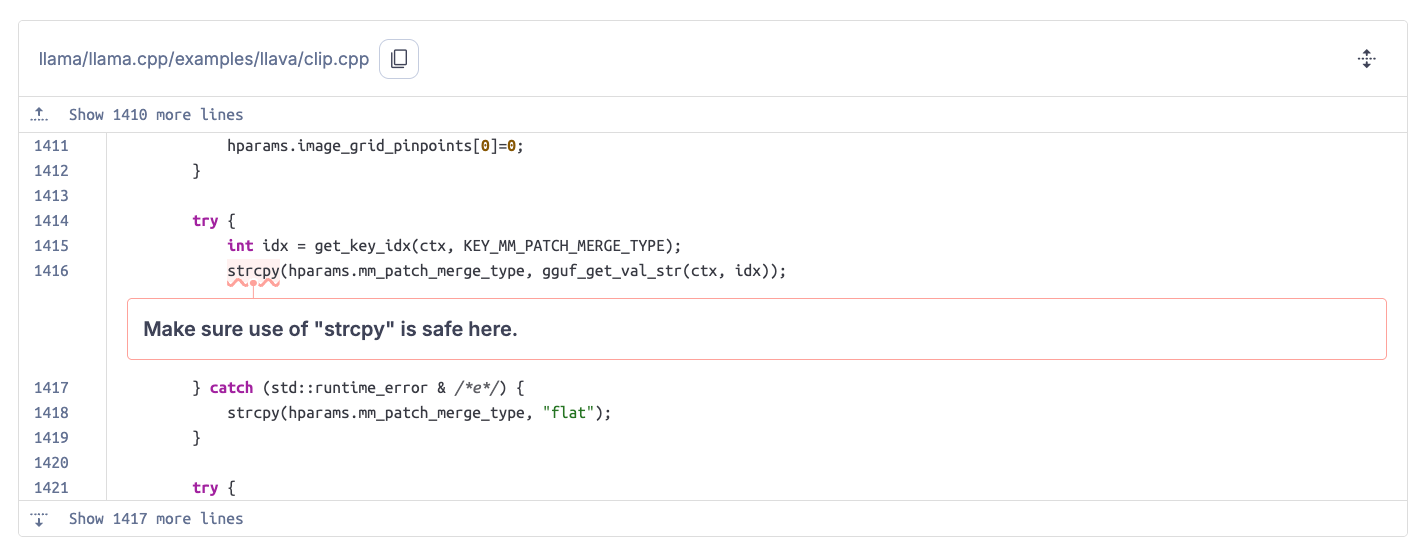
The issue is indeed a valid vulnerability because the copied source string comes from the metadata section of an LLM model file via gguf_get_val_str(), and the target buffer has a fixed size:
llama/llama.cpp/examples/llava/clip.cpp:
struct clip_hparams {
// ...
char mm_patch_merge_type[32] = "flat"; // spatial_unpad or flat (default)
// ...
};An attacker could craft and load a malicious model file with a clip.vision.mm_patch_merge_type metadata entry that is larger than 32 bytes. This would then overflow the buffer and overwrite the data located in memory after the mm_patch_merge_type buffer.
However, after further investigation, the vulnerability did not seem that useful for an attacker because the overwritten data was not used in ways that seemed dangerous. Therefore, we continued our investigation of the Ollama code base.
More untrusted metadata
During the parsing of an mllama model, a multi-modal version of the llama family, there is a special parameter that specifies which layers should be considered "intermediate":
auto &vision_model = new_mllama->vision_model;
auto &hparams = vision_model.hparams;
// [...]
hparams.n_layer = get_u32(ctx, "mllama.vision.block_count");
// [...]
std::vector<uint32_t> intermediate_layers_indices = get_u32_array(ctx, "mllama.vision.intermediate_layers_indices");
hparams.intermediate_layers.resize(hparams.n_layer);
for (size_t i = 0; i < intermediate_layers_indices.size(); i++) {
hparams.intermediate_layers[intermediate_layers_indices[i]] = true;
}As we can see, the code reads an integer from the model's metadata and stores it in n_layer. It then initializes a list of booleans (std::vector<bool>) to reserve space for n_layers items. Afterward, the code uses another metadata item, mllama.vision.intermediate_layers_indices, to mark some layers as intermediate by setting the corresponding vector item to true.
However, there are no checks that verify if an index read from intermediate_layers_indices is actually within the bounds of the intermediate_layers vector. In contrast to other programming languages, the C++ std::vector also does not perform bounds checks, leading to an Out-Of-Bounds (OOB) Write vulnerability. Since the loaded model file can be controlled by an attacker, the included metadata should be treated as untrusted data by Ollama. However, the indices array is never checked to contain only indices smaller than the number of layers.
To confirm the OOB write, we quickly crafted a model file that contains a big index, leading to a segmentation fault:

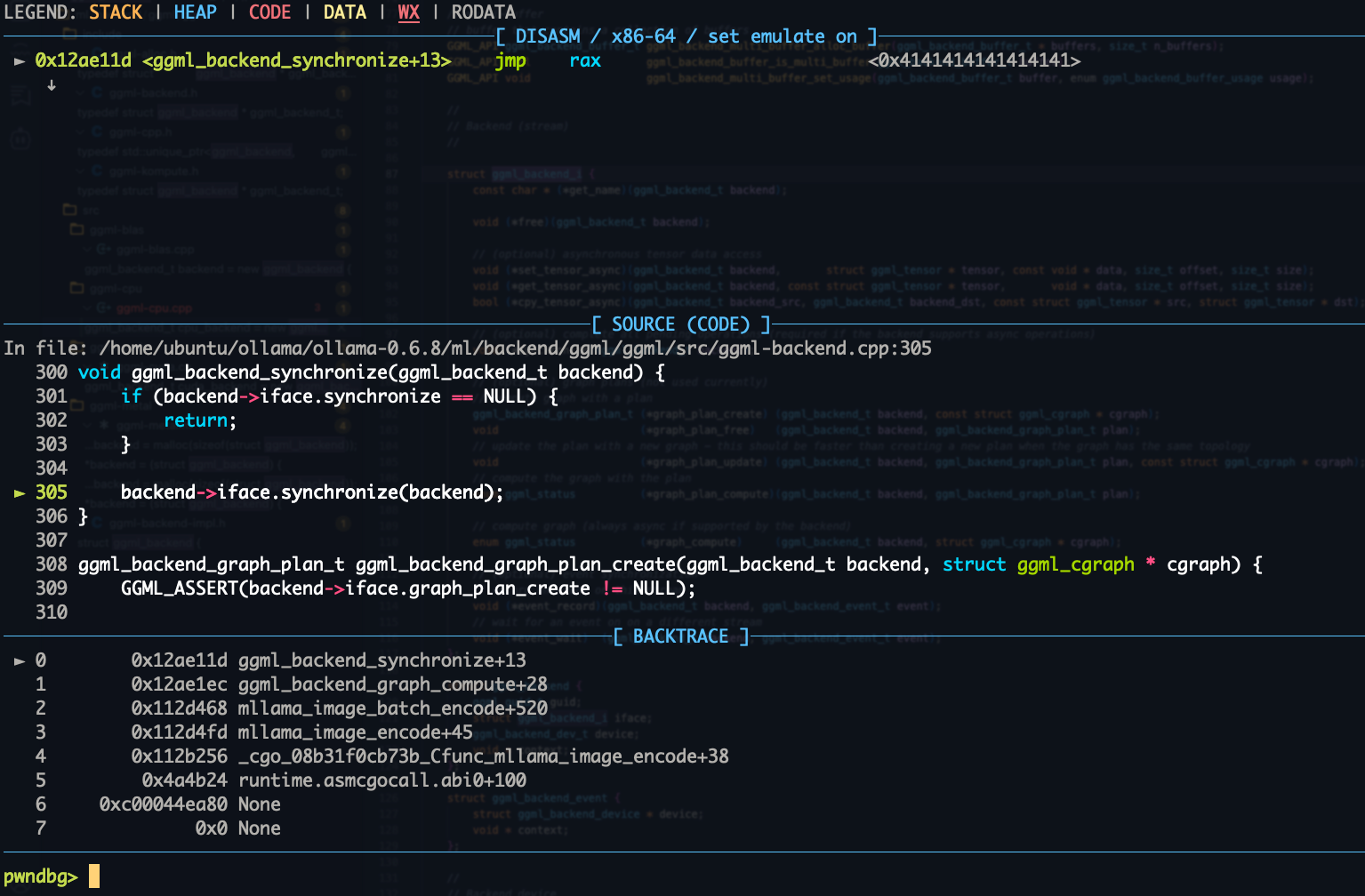
Is this exploitable?
At first glance, this bug does not look very promising for an attacker. Usually, a bool is stored as a single byte where 0 corresponds to false and 1 corresponds to true. Setting arbitrary bytes to 0x01 in the memory after the vector does not look like the attacker can control much.
However, it turns out that std::vector<bool> has a special implementation: since a boolean has only two states, it can be represented with a single bit! Therefore, a vector of booleans uses a memory-efficient representation where each item is packed into a single bit:

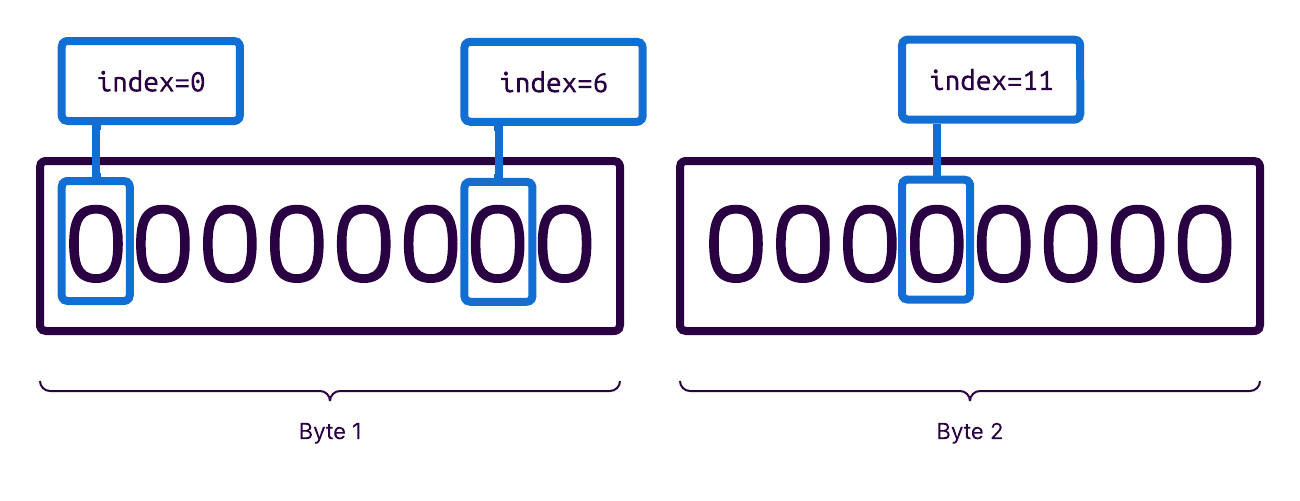
For the vulnerability, this means that an attacker can flip arbitrary bits from 0 to 1. We can immediately make two observations about this primitive: The attacker can create arbitrary values in memory if that memory value is already zero, since all bits can potentially be flipped. However, this also means that the attacker has very limited control over memory that already contains data. Basically, existing values can only be increased because existing 1-bits will stay, and only 0-bits can be flipped to 1.
Is there an attack path?
To see how this bit-setting primitive can be used by the attacker, let's inspect the memory around the vector. Since the vector is allocated on the heap, there are two possible targets:
- Heap chunk metadata
- Contents of heap chunks
We chose to look for the latter first, and indeed, there were some structs in reach of the OOB write that are promising for an attacker. One of them, the ggml_backend struct, contains a bunch of function pointers, some of which are NULL:
ml/backend/ggml/ggml/src/ggml-cpu/ggml-cpu.cpp:
struct ggml_backend {
ggml_guid_t guid;
struct ggml_backend_i iface;
ggml_backend_dev_t device;
void * context;
};
static const struct ggml_backend_i ggml_backend_cpu_i = {
/* .get_name = */ ggml_backend_cpu_get_name,
/* .free = */ ggml_backend_cpu_free,
/* .set_tensor_async = */ NULL,
/* .get_tensor_async = */ NULL,
/* .cpy_tensor_async = */ NULL,
/* .synchronize = */ NULL,
/* .graph_plan_create = */ ggml_backend_cpu_graph_plan_create,
/* .graph_plan_free = */ ggml_backend_cpu_graph_plan_free,
/* .graph_plan_update = */ NULL,
/* .graph_plan_compute = */ ggml_backend_cpu_graph_plan_compute,
/* .graph_compute = */ ggml_backend_cpu_graph_compute,
/* .event_record = */ NULL,
/* .event_wait = */ NULL,
};These function pointers are called later during inference, and there is a catch: Some of the calls are wrapped in checks that will only call the pointer if it's not NULL:
ml/backend/ggml/ggml/src/ggml-backend.cpp:
void ggml_backend_synchronize(ggml_backend_t backend) {
if (backend->iface.synchronize == NULL) {
return;
}
backend->iface.synchronize(backend);
}For the attacker, this is gold: they can overwrite one of the NULL pointers with an arbitrary address (according to the primitive laid out above) and cause the pointer to be called.
Proof-of-concept
To create a first proof-of-concept that makes Ollama call an arbitrary address, we just had to craft a model that contains the right indices representing the offsets of the 1s we want to write in memory. The model also has to pass the parsing and get successfully constructed in memory because the functionality calling the pointer happens during inference, which is after the model parsing.
This was easier said than done, and we had to spend quite some time here. One problem was that off-the-shelf models were quite large (multiple gigabytes), so they weren't great for testing. However, crafting a model from scratch was also not an easy task, as all the metadata and tensors had to match so that no checks would fail while the model was created in-memory.
After some time, we finally managed to create a model that is only a few kilobytes big and can be processed by Ollama. We were able to confirm the controlled call by writing 0x4141414141414141 to the .synchronize member of the ggml_backend struct:

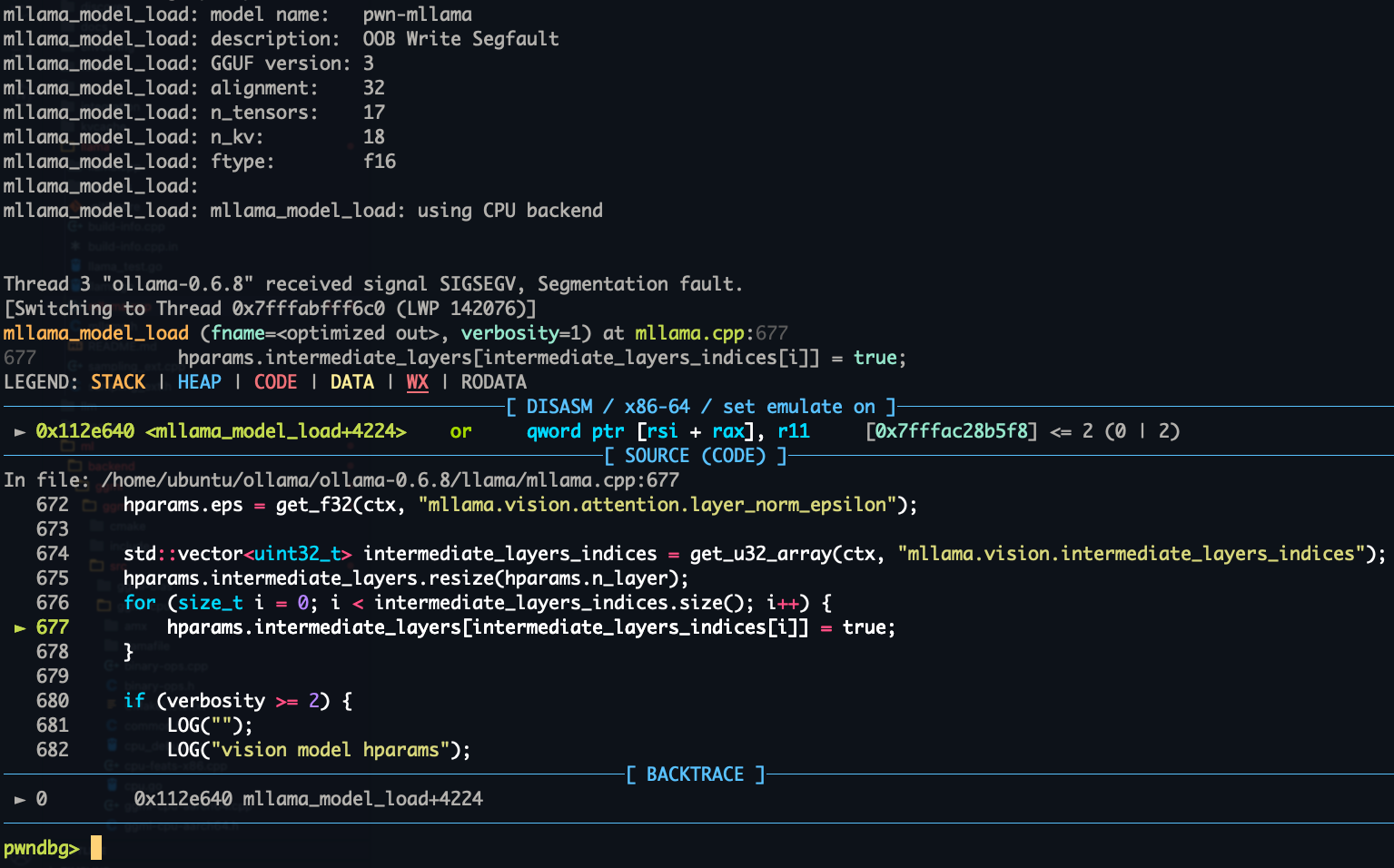
Who you gonna call?
This already shows quite a big amount of control over the program, but we had to determine whether attackers would be able to execute arbitrary code. For this, we had to find functions that might be interesting for an attacker to use on their way to arbitrary code execution.
For our debugging setup, we built Ollama via go build ., which does not enable the Position-Independent Executable (PIE) security hardening by default. This means that the address of the program in memory is static, which also makes the address of every function in the binary deterministic. An attacker could use this to write the address of any function contained within the Ollama binary into the struct's .synchronize field, causing it to be called.
First, we checked if there are easy-to-use gadgets, such as a one-gadget. However, this approach did not work out. First, the base address of libc is unknown, making it impossible for the attacker to use gadgets from libc. Second, the Ollama binary itself did not import functions like system(), so we could not simply jump there.
Third and most importantly, the .synchronize function pointer is only called with a single argument, which is a pointer to the ggml_backend struct itself. This means that, even if the attacker could redirect the call to system(), they would not be able to pass a string with attacker-controlled commands to it. We decided that it was not worth looking for other "easy" gadgets and that it was time to go the classic route of building a Return-Oriented Programming (ROP) chain.
Building a ROP chain
Knowing the base address of the executable in memory not only means the attacker can jump to arbitrary functions, but also to any instruction within the binary. This can be used to chain together a list of already existing instruction snippets that, when executed sequentially, perform the behavior that the attacker wants. These instructions are called gadgets.
However, to make the program execute a sequence of gadgets, the attacker needs to control the stack and write multiple return addresses that represent the gadgets. When the program returns from the first gadget, it will return to the address of the second gadget, and so on. To make this feasible in the Ollama scenario, the attacker first needs to perform a stack pivot by swapping out the stack with a memory location the attacker controls. This is usually done by overwriting the stack pointer (rsp).
After listing and examining the available ROP gadgets, there was one promising gadget that stood out:
mov rsp, rbx ; pop rbp ; ret
This gadget would overwrite the stack pointer with the value in rbx, remove one item from the stack, and then continue the ROP chain from there. While debugging the program at the point of the attacker-controlled jump, we can see that rbx points to the ggml_backend struct, which will become the new stack! This is great for the attacker because they already know how to control some of the values of this struct. However, there are some constraints that need to be met to make the attack work.
Fitting a ROP chain into ggml_backend
The main problem is that the attacker can't control all the values in the struct, due to the limitations of the bit-flipping primitive. To recap, the attacker can only flip 0s to 1s, not the other way around. Looking at the values in the struct before the OOB write happens, it seems that the attacker only has limited control over the ROP chain:

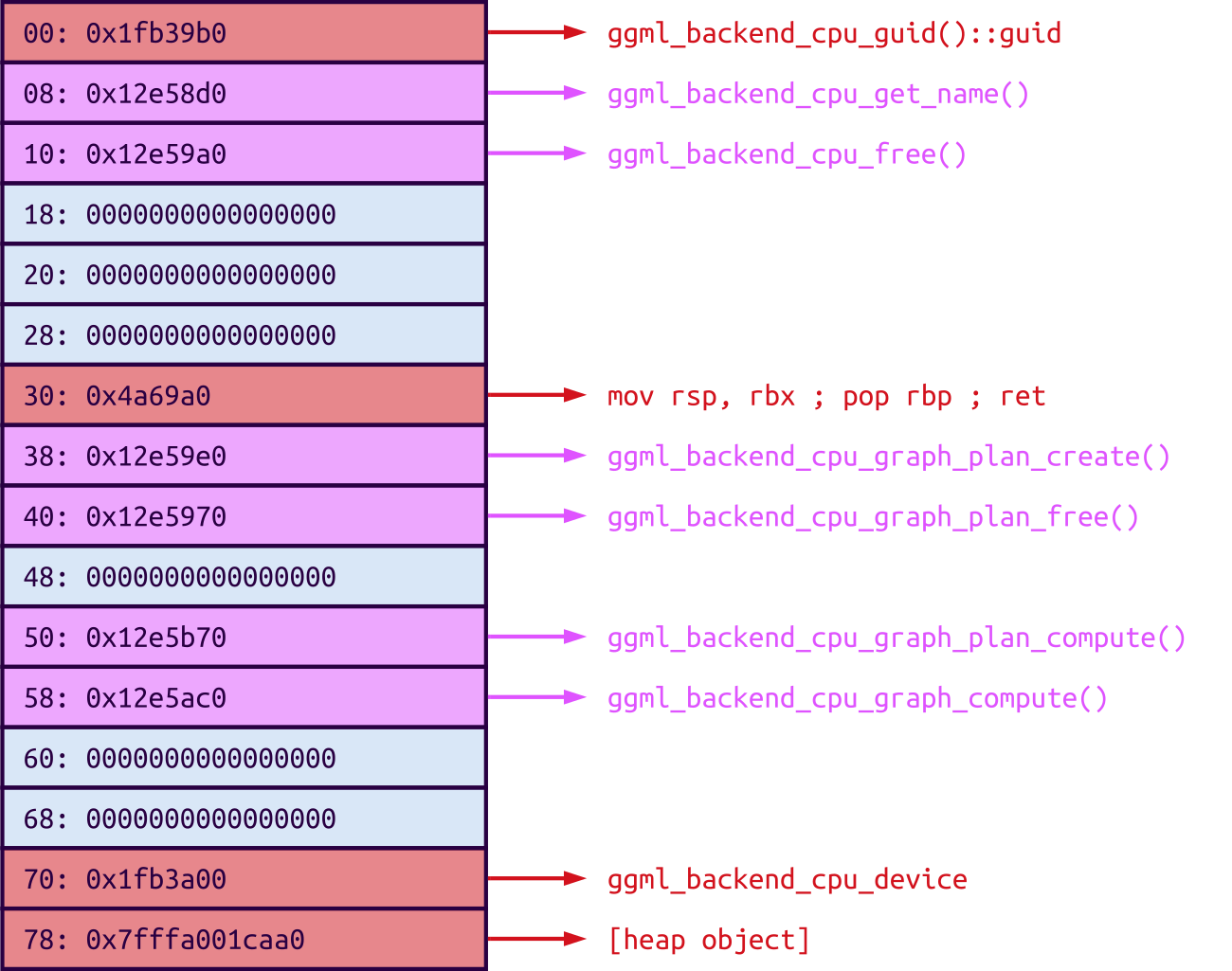
The red areas cannot be changed. The first one points to a location after the binary's text section, meaning it cannot be modified to become a valid code pointer because the bit flipping primitive can only be used to increase values. The second red slot cannot be changed because it points to the stack pivot gadget that starts the whole ROP chain. The last two red slots also point to locations after the text section.
The pink areas already contain values, but they are pointers to the text section. This means that they could be slightly altered to point to different code locations, but the modifications are very limited.
The blue areas only contain null bytes. The attacker can therefore overwrite them with arbitrary data, so they can be used for arbitrary ROP gadgets without any constraints.
The first problem for the attacker is that the very beginning of the struct contains data that cannot be modified into a code pointer. However, the stack pivot gadget pops a value off the stack after overwriting rsp, so the first "slot" is skipped.
The next problem is that the existing function pointers (in pink) might have side effects when called, such as clobbering register values or crashing due to unexpected argument values. However, with a bit of scripting, we were able to confirm that an attacker can modify them into harmless ret gadgets.
For example, the .free member points to the ggml_backend_cpu_free function at the address 0x12e59a0. Listing all valid code addresses that can be constructed from this address by flipping 0-bits, we can find some gadgets:

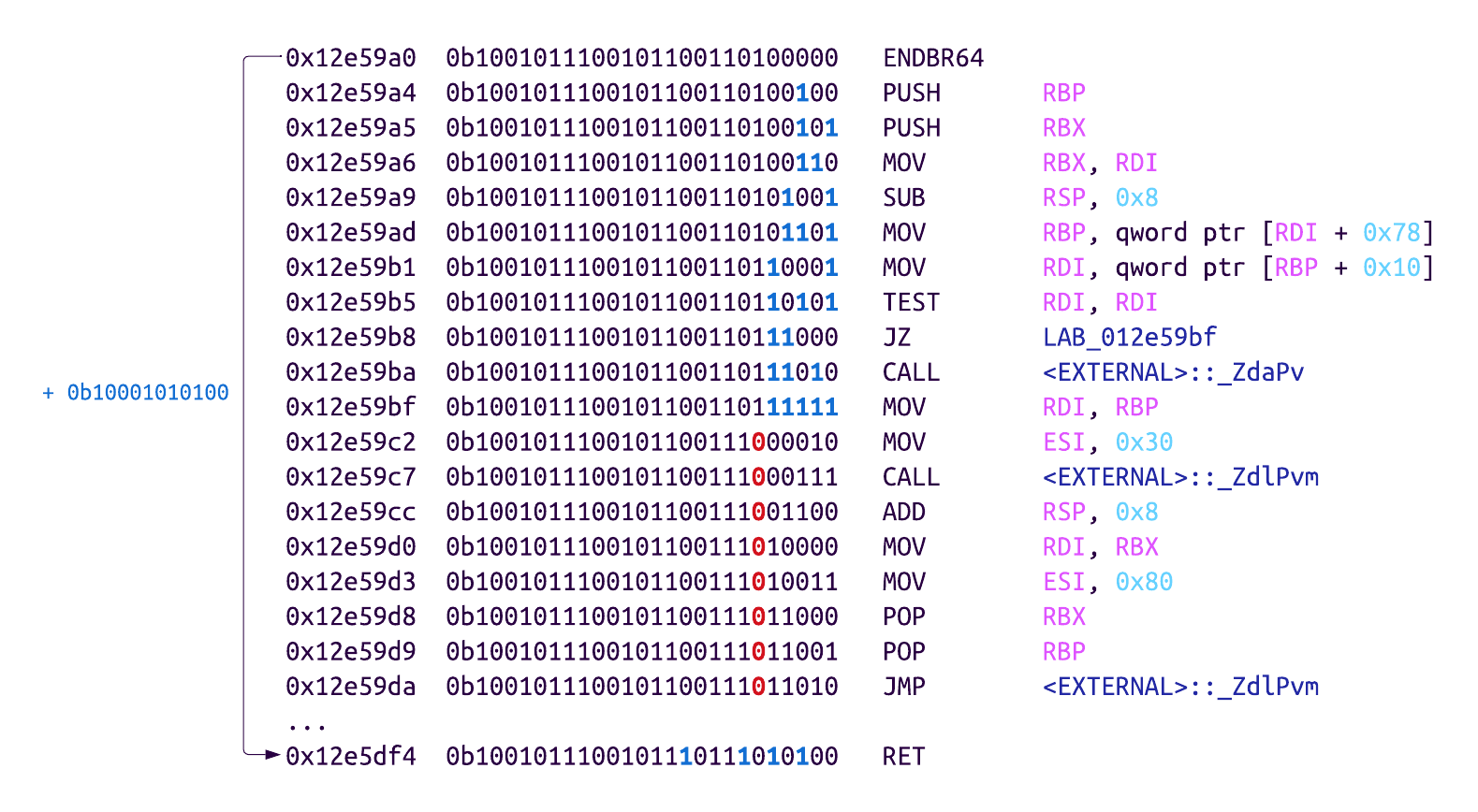
We noticed that all the existing addresses (pink areas in the struct) can be turned into the addresses of ret instructions. These are essentially no-ops because the only thing they do is return to the next ROP gadget without causing any side effects. The attacker, therefore, does not have to worry about them and can focus on using the free slots for actual gadgets. There is still the limitation of only 6 free slots, but this already gives the attacker much more room to play with.
From free to system
Looking at the binary's protections, we can see that RelRO is only set to partial, which means that the Global Offset Table (GOT) is writable. Since Ollama imports some functions from libc, such as printf or free, the attacker can modify these GOT entries to point to a dangerous function like system instead. Investigating Ollama's code, we found a location that calls free with the address of an attacker-controlled string:
func (m *Model) Tokenize(text string, addSpecial bool, parseSpecial bool) ([]int, error) {
// [...]
cText := C.CString(text)
defer C.free(unsafe.Pointer(cText))
// [...]
}During prompt tokenization, Ollama calls from its Go code base into the C++ code of llama.cpp. For this, strings need to be converted to C-strings and allocated on the heap to avoid memory management issues. To clean up unused memory afterward, the Tokenize function defers a call to libc's free() that will happen when Tokenize finishes.
Since the prompt is attacker-controlled, the call to free() receives an attacker-controlled string as its argument. To weaponize this, the attacker can use a ROP chain that redirects the free function to libc's system function instead. This can be done by adding the distance between free and system onto the GOT entry for free. This can, for example, be achieved with the following ROP chain:

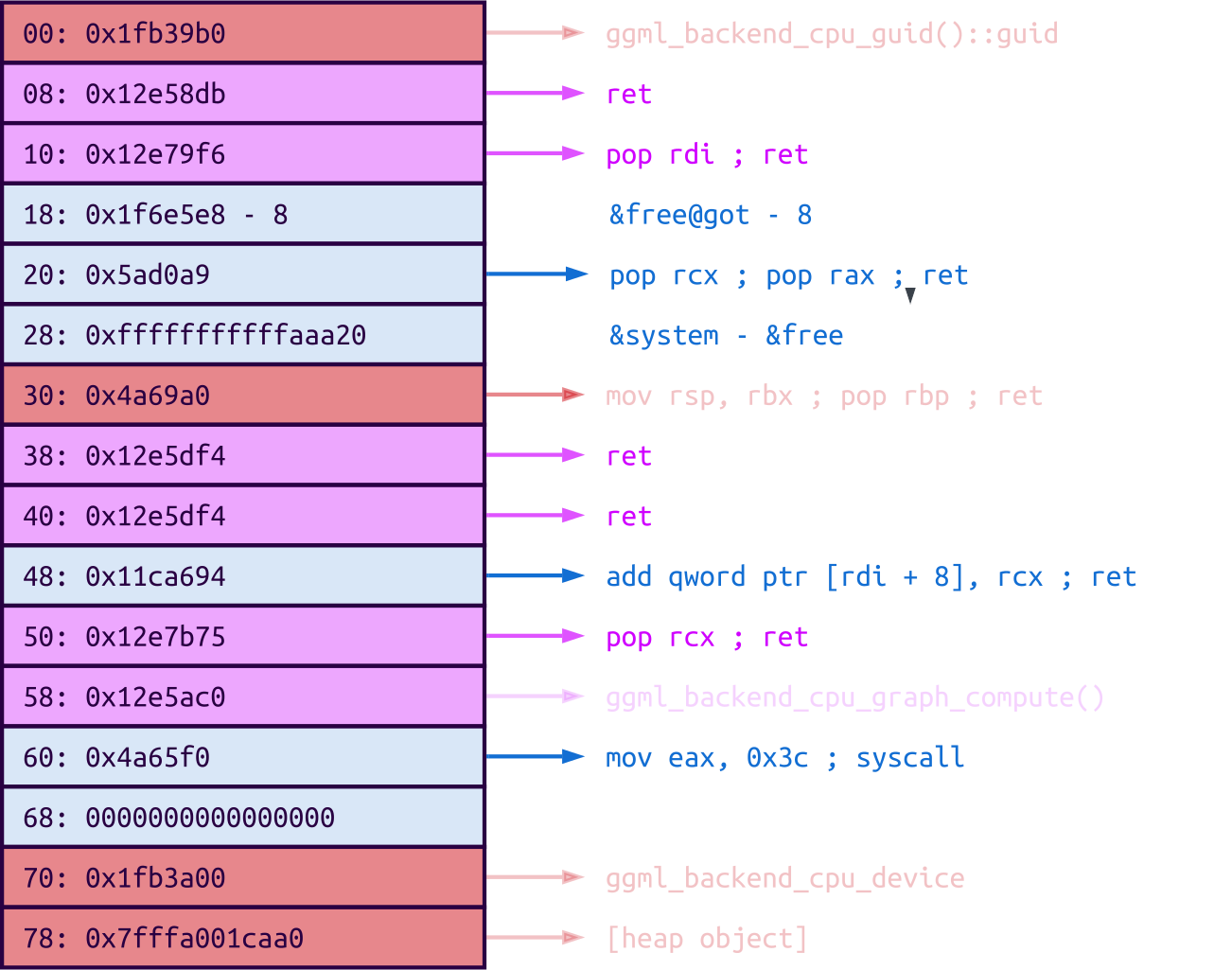
After this overwrite, any call to free will instead run a system command via system!
The final hurdle
In order to be able to send another prompt with the command, the attacker needs to keep the runner process alive long enough. However, the current ROP chain will not exit gracefully, causing the process to crash shortly after.
To avoid this, the attacker can add one more gadget that calls the exit syscall. In contrast to libc's exit() function, this syscall does not terminate the process but only the current thread. Since the model inference computation is done asynchronously, terminating the thread does not crash or terminate the runner process. Instead, the main thread will notice that the work threads have terminated, expecting the inference to be completed. This allows the attacker to send follow-up prompt requests containing arbitrary system commands, which will be executed by the runner process via system() instead of free()-ing them.
The PIE is a lie
After finishing our proof-of-concept, we realized that it would not work for most Ollama instances. But why? When building Ollama for release, another protection called "Position-Independent Executable" (PIE) is enabled explicitly via the -buildmode=pie build argument. This means that, to build a ROP chain, an attacker would first need to leak an address from memory and compute the binary base address.
However, since the model parsing happens as the first thing when spawning a runner process, there is basically no chance for an information leak before that. Therefore, in order to build an exploit against release versions of Ollama, the attacker would need to go a different route, likely using the OOB write to corrupt some other object's size field, giving them arbitrary read and write primitives during inference. However, we chose not to pursue this in the interest of time, although we deem it to be possible.
Patch
When we wanted to report the vulnerability to the Ollama maintainers, we double-checked that the vulnerable code lines were still present in the latest version on GitHub. However, when searching for the mllama.cpp file, we weren't able to find it. What happened?
It turns out that the mllama model handling was rewritten in Go and merged to the main branch just 2 days prior. We still sent a heads-up email to the maintainers, and they confirmed that the C++ implementation was indeed replaced with the new Go implementation.
This is a new remediation record in our disclosure history! The Ollama maintainers fixed the vulnerability 2 days before we even reported it. Good job on making our timeline look funny:
Timeline
| Date | Action |
| 2025-05-13 | The Ollama maintainers release version 0.7.0, which removes the vulnerable code |
| 2025-05-15 | We report the issue to the Ollama maintainers |
Summary
With AI and LLMs on the rise, it is more important than ever to check the security of the code that they run on top of. In this blog post, we showed that vulnerabilities in memory-unsafe code like C and C++ are still a thing in 2025. Such bugs can have severe consequences, and security hardenings like Position Independent Executable (PIE) are just a band-aid to limit the impact. Security in depth is a good thing, but vulnerabilities should be tackled where they originate: in the code.
Finally, we would like to express kudos to the Ollama maintainers for their outstanding time-to-fix of -2 days!
Related Blog Posts
- Code Security for Conversational AI: Uncovering a Zip Slip in EDDI
- Securing Go Applications With SonarQube: Real-World Examples
- Caught in the FortiNet: How Attackers Can Exploit FortiClient to Compromise Organizations
- Why Code Security Matters - Even in Hardened Environments
- Parallel Code Security: The Challenge of Concurrency